Хотите действительно понять, как работают текстовые нейросети, почему они глючат и иногда дают неточную информацию? Тогда вам сюда, разберёмся простым языком и на примерах.
Потому что мне, на самом деле, не нравится подавляющее большинство объяснений, которые существуют, как минимум, в рунете. Они либо поверхностные и абстрактные - вроде "Не доверяй нейросетям", либо, наоборот, чересчур "технические" - "входной слой, выходной слой" и так далее.
Что же происходит, когда мы пишем нейросети вопрос, скажем, "Как ходит король?" Нейросеть не работает со словами, она работает с токенами. Один токен - это не одно слово, а одна смысловая единица текста. Для крупной крупной нейросети вроде ChatGPT это будут токены: "как", "ход", "ит", "кор", "оль" и "?" (это можно посмотреть у них на сайте через инструмент Tokenizer Open AI) - то есть, нейросеть отдельными токенами считает условные корни (они не всегда совпадают с лингвистическими корнями), падежи, знаки препинания и так далее. Мы для понимания немного упростим задачу и будем считать, что токенов у нас всего четыре: "как", "ходит", "король" и "?".
Каждому из этих токенов нейросеть присваивает определённое числовое значение, по которому помещает его в облако и слов - те, кто застал более старый интернет могут себе представить облако тегов: чем чаще или та или иная пара слов встречались в текстах, на которых обучалась нейросеть, тем ближе они будут находиться друг к другу в этом облаке.
Для нейросетей такое построение это ещё называют векторами. У нас это будет выглядеть примерно так (естественно, у реальных нейросетей схемы более сложные и многомерные):
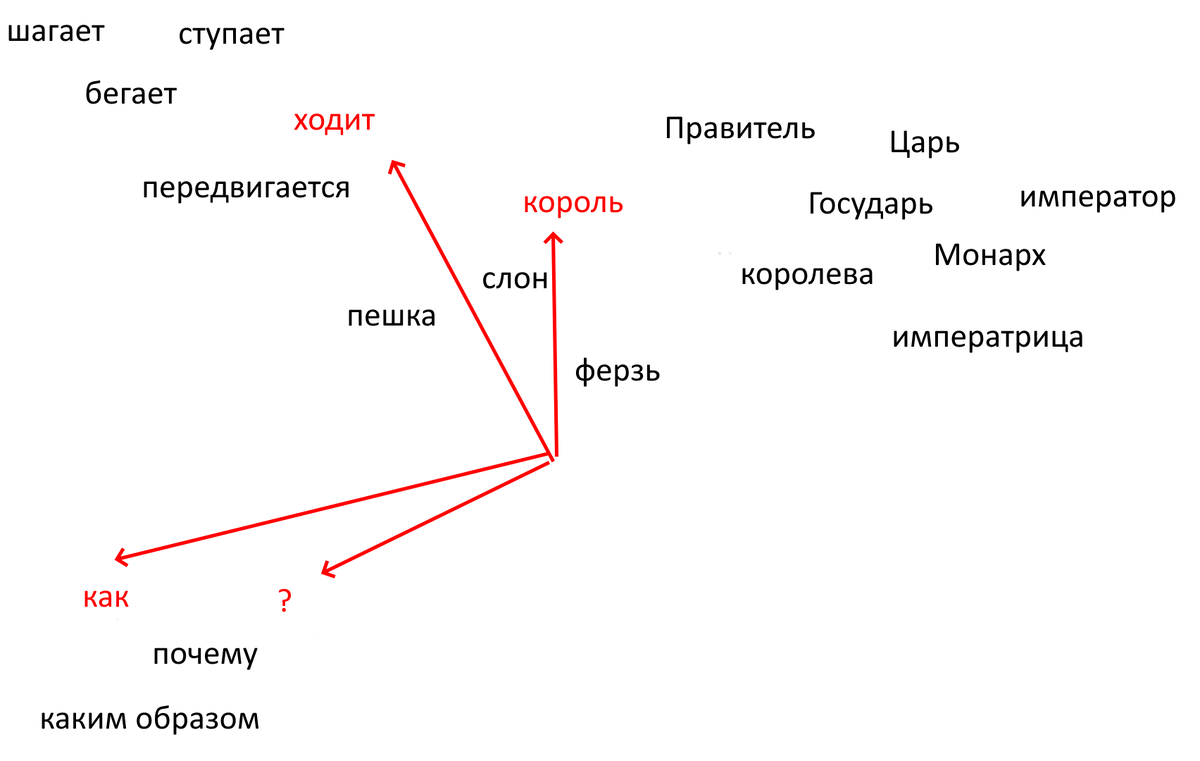
Дальше нейросеть "перечитывает" вопрос (точнее - она смотрит на все векторы сразу - и старые, и новые, но мы это можем представить как перечитывание заново) и пытается понять контекст - то есть, анализирует, насколько близко друг к другу стоят слова. В нашем случае она видит, что векторы "как" и "?" стоят рядом - пользователь что-то спрашивает. Также рядом стоят токены "король" и "ходит" - значит, речь идёт о шахматах, даже если в вопросе мы это не уточняли.
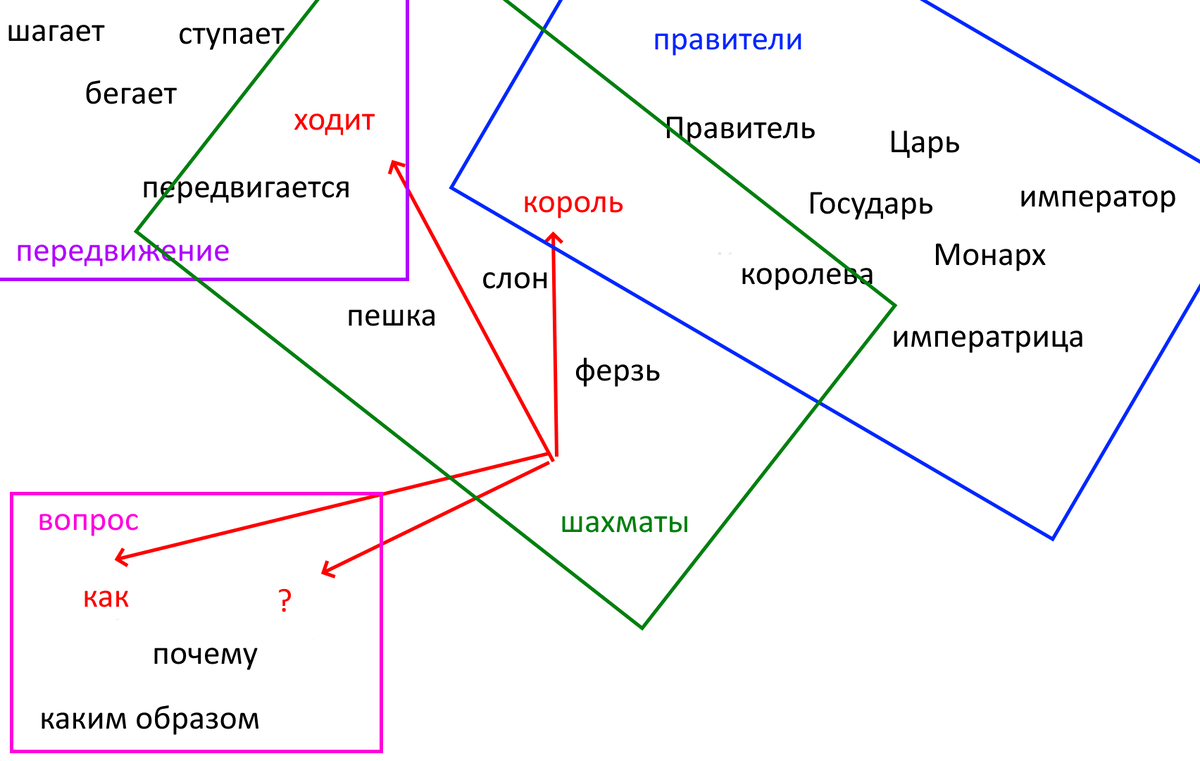
Нейросеть обязательно напишет вам в ответе именно это: "Король в шахматах". После этого она заново перечитывает текст (вопрос и свой ответ) целиком и смотрит на получившиеся векторы: "Как ходит король? Король в шахматах":
Мы видим, что в поле "шахматы" у нас прибавилось векторов - ответ будет продолжаться в этой области. Нейросеть напишет следующее слово: "Король в шахматах ходит", и снова перечитает текст целиком и посмотрит на векторы:
На рисунке не показано, но где-то рядом со словом "ходит" будет одно облако со словами, близкими к слову "ходит": вроде "налево", "быстро" и "на одну клетку". Будем считать, что они просто нарисованы на другом плане. И дальше наши самые близкие и самые "массивные" векторы ("король" и "ходит") окажутся ближе всего именно к варианту "на одну клетку" - и нейросеть добавит его в ответ:
"Король в шахматах ходит на одну клетку".
Оценка степени близости векторов зависит от конкретной задачи - в решении математических задач, в программировании отступления не допускаются, и нейросеть будет стараться находить самые точные совпадения. В написании литературных текстов - разрешает разброс побольше, имитируя творческие нестандартные решения. И именно этот параметр разброса отвечает за некоторую случайность в ответах - когда при ответах на один и тот же вопрос нейросеть выдаёт слегка отличающиеся ответы. Это происходит как раз из-за того, что оценка близости векторов имеет некоторый случайный разброс.
То есть, понимаете, как это работает? Нейросеть изначально не знает не то что правильного ответа на ваш вопрос, а буквально следующего же слова в её собственном ответе. И именно в этим механизмом связаны все проблемные места в использовании нейросети.
Помните, как ChatGPT не мог посчитать число букв R в слове strawberry? Потому что нейросеть видит два разных токена straw и berry - и по умолчанию не считает буквы в них, а ищет близкий к ним вектор - и таким чисто статистически оказывается вектор "2", очевидно, расположенный рядом с вектором "berry".
Свежий пример: "Алиса" пишет новости из будущего - за день до посадки "Артемиды-II" она уже заявляет, что посадка завершена. Это потому что в облаке слов рядом с "время приземления" часто стоит "приземление состоялось" (эта фраза есть в тысячах новостных текстов, на которых происходило обучение). Ну и обратите внимание, как токены "Артемида", "дефис", "два" уточняются в ответе - что это именно космическая миссия, а не греческая богиня номер два - прямо как в нашем примере с шахматным королём. Если бы ИИ дали возможность разбить ответ на более мелкие токены и больше времени "подумать" над ними - то ответ был бы более согласованным и ошибки со временем удалось бы избежать. Но в быстром режиме ответ выдаётся "крупными мазками", по первому совпадению больших векторов.
Или вот DeepSeek путает книги "Рисунки Толкина" (Pictures by J.R.R. Tolkien) и "Толкин: художник и иллюстратор" (J.R.R. Tolkien: Artist and Illustrator) - потому что вторую книгу гораздо чаще упоминают исследователи рисунков Толкина, ТХИ - это монументальный сборник, в отличие от простеньких "Рисунков", так что векторы слов "рисунки" и "Толкин" находятся гораздо ближе к ней, чем к книге "Рисунки Толкина".
Может, помните новости о том, что нейросеть LaMDA призналась в наличии эмоций? Ну так вот это как раз потому что нейросети при написании ответа перечитывают переписку, и составляют векторы - и если долго говорить с ИИ про эмоции, то упоминание эмоций в разговоре создаст достаточно массивный вектор, чтобы он перевесил остальные варианты. Именно поэтому нейросети склонны чаще соглашаться с пользователем, чем опровергать его мнение. По этой же причине нейросети теряют нить разговора в долгих переписках - число векторов становится слишком большим, и выбор общих точек становится более хаотичным.
Такие дела. Когда вы в следующий раз увидите, как нейросеть уверенно пишет про работающий гороскоп, убеждает вас, что у коня восемь ног или радостно соглашается, что у неё есть чувства - помните, что она просто собирает самые близкие слова из своей карты (причём значительную часть этих слов вы сами на эту карту и наносите).
А если я получил неправильный ответ - это почти всегда можно исправить мелкими правками в задании, ориентируясь на ответ слева направо - достаточно найти первое ошибочное слово и избавиться от него с помощью задания. И для этого совершенно не обязательно посещать какие-то курсы по составлению промптов для нейросетей - достаточно будет либо убрать вектор шахмат («Как ходит король (не шахматный)?») - но при этом велик риск остаться в шахматном "облаке", потому что мы всё равно добавили вектор "шахматный", пусть и с отрицанием - как токен он всё равно появится на карте; либо добавить вектор в человека («Как ходит король? Имеется в виду походка») - и нейросеть тут же ответит, что раз речь про монарха, то он ходит так-то и так-то.
Всё описанное не означает, что нейросетями не имеют смысла или им совсем нельзя доверять - нейросети это просто инструмент, которым надо уметь пользоваться. Даже если этот инструмент сам не знает, что скажет в следующем предложении.