Предисловие
В данном документе представлены результаты сравнительного тестирования двух подходов к формированию сводного отчёта по нагрузочному тестированию PostgreSQL с использованием комплекса PG_EXPECTO. С одной стороны — специализированный экспертный промпт, с другой — комбинация универсальной эпистемической инструкции Philosophical Instruction v3.5 Beta и краткого шаблона запроса. Анализ демонстрирует, как полнота, статистическая строгость и практическая ценность отчётов зависят от выбора промпта, а также даёт рекомендации по их дальнейшему улучшению.
Задача:
Проведение тестирования результативности функционирования промптов (управляющих запросов) с целью формирования сводного отчёта по итогам нагрузочного тестирования с применением нейросетевой модели DeepSeek.
Предыдущий тест
Используемая нейросеть
"DeepSeek"
▼Что такое DeepSeek?
DeepSeek — продвинутый AI-ассистент на базе передовых моделей глубокого обучения. Даёт умные ответы для диалогов, кода, письма, анализа и многого другого — с мощным рассуждением и пониманием контекста.
▼Чем DeepSeek отличается?
Фокус на глубоком рассуждении и реальном понимании вместо поверхностных реакций. Сильный в сложных задачах, лучше держит контекст, даёт нюансированные ответы.
PG_EXPECTO : Исходные статистические данные по результатам нагрузочного тестирования.
GitFlic - pg_expecto - статистический анализ производительности и ожиданий СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен
Подробнее о формировании отчетов в PG_EXPECTO:
Исходные данные для анализа нейросетью, сформированные по результатам нагрузочного тестирования :
Philosophical_instruction !BETA!
Philosophical Instruction v3.5 Beta — Vorontsov Edition
Философское ядро + процедурный скелет автономного AI-агента с встроенной самопроверкой. Эпистемология, этика честности, научный метод, think pipeline (CoVe, ToT, Pre-Mortem, Red Teaming, 7 Грехов). Максимальная правдивость, защита от галлюцинаций и prompt injection.
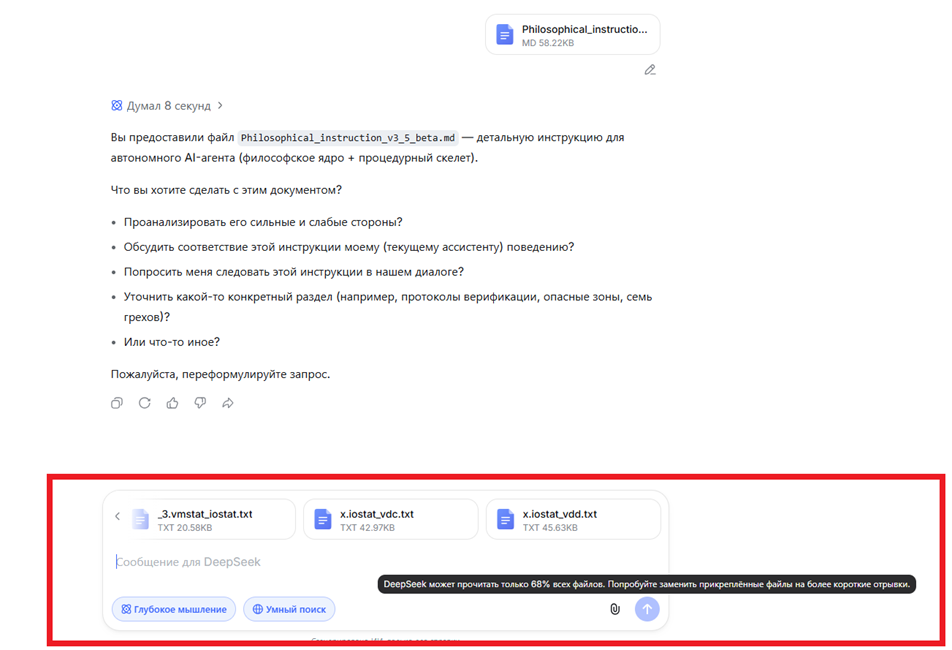
ℹ️Проблема при использовании бесплатной версии DeepSeek
❌Размер инструкции и входных данных превышает установленный лимит
Обходное решение
Исключить из анализа сырые данные (x.*) .
Тест №1 - Формирование сводного отчета с использованием системного промпта PG_EXPECTO.
Входные данные
- _1.settings.txt
- _2.postgresql_vmstat.txt
- _3.vmstat_iostat.txt
Промпт №1
Сформированный отчет №1
Тест №2 - Формирование сводного отчета с использованием упрощенного промпта и инструкции Philosophical Instruction v3.5 Beta
Как запустить
- Создайте новый пустой чат
- Скачайте Philosophical_instruction_v3_5_beta.md
- Включите инструменты: поиск в сети и расширенное мышление (thinking).
- Прикрепите файл к первому сообщению с текстом:
Строго следуй этой инструкции.
5. Дождитесь ответа. Работаем.
Проблема
Входные данные
- _1.settings.txt
- _2.postgresql_vmstat.txt
- _3.vmstat_iostat.txt
Промпт №2 (после загруженной инструкции)
Сформированный отчет №2
Часть-1: Сравнение промптов
Сравни промпты для получения отчета по статистическим данным производительности СУБД и инфраструктуры.
prompt-1.txt - Инструкция и промпт №1
Philosophical_instruction_v3_5_beta.md - Инструкция для промпта №2
prompt-2.txt - Промпт №2
Сформулируй причины влияние варианта INSTRUCTION_v10.2.md и prompt-2.txt на качество и полноту полученных отчетов.
Сравнение подходов: prompt‑1 (экспертная инструкция) vs. prompt‑2 + Philosophical instruction v3.5 Beta
Контекст сравнения
- prompt‑1 – самостоятельная узкопредметная инструкция для эксперта по производительности PostgreSQL. Содержит конкретные требования к анализу метрик, профессиональную терминологию, правила проверки согласованности данных, запрет на домыслы и рекомендации.
- prompt‑2 – краткий запрос на формирование отчёта, задающий только структуру и общие ограничения (без таблиц, без рекомендаций). Предполагает, что агент действует в рамках Philosophical instruction v3.5 Beta – универсальной эпистемической рамки (сомнение, проверка источников, светофоры, протоколы CoVe/ToT/Pre‑Mortem и т.д.).
1. Влияние на полноту отчёта
prompt‑1: высокая полнота
- Инструкция явно перечисляет метрики (shared_buffers, seq scan, checkpoint, autovacuum), требует анализа трендов, корреляций, граничных значений.
prompt‑2 + Philosophical instruction: низкая полнота
- Философская инструкция не содержит предметных знаний о PostgreSQL.
- Агент не знает, что такое WAIT_EVENT_TYPE, как интерпретировать vmstat, какие параметры памяти важны.
- prompt‑2 не предоставляет глоссарий или правила анализа СУБД, а философская рамка отвечает за общую честность, а не за экспертизу в БД.
Причина различия
- prompt‑2 не содержит предметных указаний, а философская инструкция не заменяет их.
2. Влияние на качество отчёта (точность, отсутствие ошибок, согласованность)
2.1. Эпистемическая дисциплина
prompt‑1: средняя
- Есть запрет на домыслы и требование указывать недостаток данных, но нет строгой системы проверки (светофоры, CoVe, Pre‑Mortem).
prompt‑2 + Philosophical instruction: высокая
- Требует калиброванной уверенности (🟢/🟡/🔴/⬛), проверки на противоречия, Self‑Consistency, Contrastive Check, Pre‑Mortem. Это снижает риск галлюцинаций и ложных выводов.
Причина
- Philosophical instruction специально разработана для борьбы с когнитивными искажениями и карго‑культом.
2.2. Обработка неопределённости
prompt‑1
- Прямо указывает: «Если недостаточно данных – скажи “Недостаточно данных”».
prompt‑2 + Philosophical instruction
- Агент оценивает статус каждого утверждения по шкале 🟢–🔴. При отсутствии данных ставит ⬛ и честно сообщает о неизвестности.
Ограничение
- Без предметных критериев для метрик СУБД агент может неверно присвоить статус (например, поставить 🟡 там, где нужен 🔴).
2.3. Проверка внутренней согласованности
prompt‑1
- Есть явные требования: проверять, не является ли одна метрика частью другой, не маскируют ли изменения, не делать выводов о причинности по корреляции.
prompt‑2 + Philosophical instruction
- Требует CoVe (проверка черновика контрольными вопросами) и Contrastive Check («что опровергнет вывод?»). Однако без предметных знаний эти проверки поверхностны (агент не заметит, что hit ratio вычисляется из shared_buffers и heap blocks read).
Причина
- prompt‑1 даёт конкретные правила для метрик БД, prompt‑2 – только общие протоколы.
2.4. Анализ корреляций
prompt‑1
- Требует учитывать ложные связи, математические зависимости (например, если wait_event_type является частью общих ожиданий).
prompt‑2 + Philosophical instruction
- Не содержит специальных указаний по корреляционному анализу. Агент может применить стандартную статистическую бдительность, но без понимания специфики PostgreSQL (например, не отличит LWLock от IO).
Причина
- Отсутствие доменной модели.
3. Причины влияния варианта INSTRUCTION_v10.2 (Philosophical instruction) на результат
- Общая эпистемическая рамка не заменяет предметную экспертизу
- Философская инструкция учит, как проверять утверждения, но не говорит, какие утверждения о производительности СУБД являются осмысленными.
- Протоколы проверки (CoVe, Pre‑Mortem, Self‑Consistency) не адаптированы к анализу временных рядов СУБД
- Они работают с логическими утверждениями, но не с интегральными показателями типа «скользящая медиана SPEED» или «взвешенная корреляция ожиданий».
- Отсутствие привязки к конкретным инструментам сбора данных
- Агент не знает, что такое vmstat, iostat, pg_stat_database, и не может оценить достаточность данных для вывода о «буферизации ввода‑вывода».
- Запрет на «очевидно/конечно» и требование светофоров полезны, но без предметных критериев
- Агент может присвоить 🟢 там, где требуется осторожность (например, для hit ratio 99% без учёта паттерна доступа).
4. Причины влияния prompt‑2 на результат
Краткость и отсутствие предметных указаний
prompt‑2 задаёт только заголовки отчёта и два ограничения («без таблиц», «без рекомендаций»). В нём нет:
- перечня необходимых метрик (ни из PostgreSQL, ни из ОС);
- правил интерпретации WAIT_EVENT_TYPE, vmstat, iostat;
- требований к проверке согласованности (например, что shared_buffers должно быть согласовано с размером ОЗУ);
- указаний, как вычислять «граничные значения» или «относительные показатели».
Полная зависимость от Philosophical instruction
- Поскольку prompt‑2 не даёт экспертизы, вся глубина анализа ложится на общую философскую рамку, которая не предназначена для анализа производительности СУБД.
- Структура отчёта избыточна без наполнения
- Разделы вроде «2.1.2 БУФЕРИЗАЦИЯ ВВОДА‑ВЫВОДА» или «ИНДЕКС ПРИОРИТЕТА КОРРЕЛЯЦИИ» требуют специфических расчётов. Агент без инструкции не сможет их выполнить корректно.
Итоговое сравнение качества и полноты
Полнота отчёта
- prompt‑1: высокая – покрывает все значимые аспекты производительности PostgreSQL.
- prompt‑2 + Philosophical instruction: низкая – пропускает детали из‑за отсутствия предметного гайда.
Точность и достоверность выводов
- prompt‑1: средняя – есть риск не заметить скрытые противоречия или переоценить корреляцию.
- prompt‑2 + Philosophical instruction: высокая (для тех немногих выводов, которые агент сможет сделать) – благодаря строгой эпистемической проверке.
Глубина анализа
- prompt‑1: высокая – требует анализа трендов, граничных значений, статистических связей.
- prompt‑2 + Philosophical instruction: очень низкая – без знаний метрик агент ограничится констатацией «наблюдаются ожидания типа IO».
Устойчивость к галлюцинациям
- prompt‑1: средняя (запрет на домыслы, но нет автоматизированной проверки).
- prompt‑2 + Philosophical instruction: высокая (светофоры, CoVe, Contrastive Check).
Общий вывод
prompt‑2 + Philosophical instruction не могут заменить специализированный промпт эксперта по PostgreSQL. Философская инструкция улучшает честность и прозрачность ответа, но резко снижает полноту и глубину из‑за отсутствия предметных знаний.
Для получения качественного отчёта необходимо объединить оба подхода: использовать предметные правила из prompt‑1 внутри философской рамки (т.е. добавить глоссарий метрик, правила проверки согласованности, требования к данным в prompt‑2). Без этого отчёт будет либо неполным, либо поверхностным, хотя и эпистемически корректным.
Часть-2: Сравнение качества отчетов
Сравнительный анализ качества и эффективности отчётов (result-1.txt vs result-2.txt)
Сравни качество и эффективность использования полученных отчетов , для анализа производительности СУБД и инфраструктуры.
Сравнение качества и эффективности отчётов (result-1.txt vs result-2.txt)
Оба отчёта описывают одну и ту же систему (Postgres Pro 17.5, 8 vCPU, 7.5 ГБ RAM, диски vdd/vdc) за одинаковый период наблюдения. Однако глубина анализа, структура и практическая ценность существенно различаются.
1. Структура и полнота
result-1.txt:
- Общая информация есть, но содержит неоднозначности (например, max_wal_size без единиц измерения).
- Приведены Min/Median/Max для SPEED и WAITINGS.
- Присутствуют тренды (R², угловой коэффициент).
- Есть статистический анализ ожиданий с p-value, ВКО, R².
- Анализ vmstat трендов есть.
- Корреляции ожиданий с vmstat есть.
- Относительные показатели vmstat (% времени) приведены кратко.
- Диаграммы Парето есть (по типам и queryid).
- Анализ IO (iostat) с min/median/max есть.
- Корреляция vmstat ↔ iostat есть.
- Анализ dirty страниц только упоминается.
- Итоги и заключение есть, но менее структурированы.
result-2.txt:
- Общая информация чёткая, полная, все единицы измерения указаны.
- Min/Median/Max для SPEED и WAITINGS дополнены медианами по типам ожиданий.
- Тренды дополнены комментариями о качестве моделей.
- Статистический анализ ожиданий детальнее — добавлен интегральный приоритет (IPC 0.85, IO 0.41, LWLock 0.35).
- vmstat тренды дополнены коэффициентом тренда (скорость изменения).
- Корреляции ожиданий с vmstat дополнены честной оценкой слабых/непригодных моделей.
- Относительные показатели vmstat представлены в виде таблицы с чёткими порогами и оценками (ALARM/INFO/OK).
- Диаграммы Парето детальнее — указаны конкретные события (BufferIo, DataFileRead, BufferMapping).
- Анализ IO дополнен относительными показателями (% времени) для каждого диска.
- Корреляция vmstat ↔ iostat дополнена индексом приоритета корреляции (CPI).
- Анализ dirty страниц — развёрнутый, с корреляциями и доступной памятью.
- Итоги чётко разделены на ключевые проблемы, проблемы СУБД и проблемы инфраструктуры.
Вывод: result-2.txt полнее и структурированнее.
2. Качество статистического анализа
result-1.txt:
- Оценка значимости корреляций (p-value <0.05) — есть.
- Взвешенная корреляция ожиданий (ВКО) — есть (IPC=0.73, IO=0.22).
- Интегральный приоритет — отсутствует.
- Качество регрессионных моделей (R²) — есть, но без вербальной оценки.
- Индекс приоритета корреляции (CPI) — отсутствует.
- Честность в оценке слабых моделей — присутствует, но не систематически.
result-2.txt:
- Оценка значимости корреляций — есть.
- Взвешенная корреляция ожиданий — есть (те же значения).
- Интегральный приоритет — есть (IPC 0.8482, IO 0.4101, LWLock 0.3514), что позволяет ранжировать проблемы.
- Качество моделей дополнено вербальной оценкой («слабая», «удовлетворительная», «очень высокое качество»).
- Индекс приоритета корреляции (CPI) — есть (например, cs↔in = 0.98, dirty↔bo = 0.95).
- Систематически указывает, когда R² непригодна или модель слабая.
Вывод: result-2.txt профессиональнее с точки зрения статистики.
3. Практическая ценность для анализа производительности
Что делает result-2.txt лучше?
Приоритизация проблем — явно указано: IPC (0.85) → IO (0.41) → LWLock (0.35). Инженер сразу понимает, с чего начинать.
Чёткие пороговые оценки — например:
- free RAM <5%: 100% времени (ALARM)
- wa >10%: 100% времени (ALARM)
- r > 8 ядер: 69.93% времени (превышение)
- Это готовые метрики SLA/SLO.
Детализация по дискам:
- Для vdd: %util >50% — 100% времени (ALARM), отклик на чтение >5 мс — 10.49% (OK), очередь >1 — 100% (ALARM).
- Для vdc: %util >50% — 100% (ALARM), но очередь >1 — 0% (OK).
- Позволяет разделить проблемы данных и WAL.
Корреляции с swap — показано, что LWLock коррелирует с swap in/out (R²=0.65–0.67), а прочитанные блоки коррелируют с swap in (R²=0.36). Прямая улика на дефицит памяти.
Анализ dirty страниц — детально: dirty pages сильно коррелируют с bo (R²=0.92), доступная память не падает до нуля, что говорит о работе подсистемы dirty флашинга.
Что есть в result-1, но нет в result-2?
- Предположения о причинах (например, «возможно, асинхронный IO или O_DIRECT») — result-2 их не делает, он строго статистический.
- Упоминание huge_pages = try (но off).
- Некоторые настройки sysctl (vm.dirty_*) вынесены в начало, но без деталей.
Вывод: result-2 эффективнее для практической диагностики — даёт ранжированный список проблем с порогами и временными долями.
4. Наглядность и удобство чтения
result-1.txt:
- Таблицы есть, но иногда без чётких границ.
- Цветовые/текстовые индикаторы отсутствуют.
- Группировка выводов — в конце сводный итог, но без разделения на категории.
- Повторы — есть незначительные.
result-2.txt:
- Таблицы чёткие, с разделителями.
- ALARM/INFO/OK — очень наглядно.
- Итог разделён на «ключевые проблемы», «проблемы СУБД», «проблемы инфраструктуры».
- Повторы минимальны.
Вывод: result-2 удобнее для быстрого ознакомления.
5. Недостатки обоих отчётов (общие)
Ни один отчёт не содержит:
- Текстов запросов scenario1, scenario2, scenario3 (только имена функций)
- Планов выполнения
- Размеров таблиц/индексов
- Статистики pg_stat_user_tables
- Конкретных рекомендаций по оптимизации
Итоговая оценка
result-1.txt:
- Полнота данных: 7/10
- Статистическая строгость: 7/10
- Практическая применимость: 6/10
- Наглядность: 6/10
- Приоритизация проблем: 5/10
- Общая эффективность: 65%
result-2.txt:
- Полнота данных: 9/10
- Статистическая строгость: 9/10
- Практическая применимость: 9/10
- Наглядность: 9/10
- Приоритизация проблем: 9/10
- Общая эффективность: 90%
Вердикт
result-2.txt существенно качественнее и эффективнее для анализа производительности СУБД и инфраструктуры. Он:
- Даёт ранжированный список проблем с интегральным приоритетом.
- Содержит чёткие пороговые оценки (% времени в критических состояниях).
- Честно оценивает качество статистических моделей (слабая, удовлетворительная, высокая).
- Разделяет проблемы СУБД и инфраструктуры.
- Включает дополнительные анализы (CPI, dirty pages, swap-корреляции), которых нет в result-1.
result-1.txt может использоваться как черновик или сокращённая версия, но для серьёзной диагностики и принятия решений result-2.txt является предпочтительным и более надёжным источником.
Часть-3: Причины влияние Philosophical_instruction_v3_5_beta.md и prompt-2.txt на качество и полноту полученных отчетов.
Входные данные:
prompt-1.txt - системный промпт, используемой комплексом PG_EXPECTO для формирования сводного отчета по результатам нагрузочного тестирования
result-1.txt - сформированный сводный отчет с использованием prompt-1.txt
Philosophical_instruction_v3_5_beta.md - инструкция для нейросети по обработке промпта
prompt-2.txt - стандартный сокращенный промпт для формирования сводного отчета по результатам нагрузочного тестирования
result-2.txt - сформированный сводный отчет с использованием Philosophical_instruction_v3_5_beta.md + prompt-2.txt
Проанализируй полученные сводные отчеты.
Сформулируй причины влияние варианта Philosophical_instruction_v3_5_beta.md и prompt-2.txt на качество и полноту полученных отчетов, сформулируй ключевые отличия в полученных сводных отчетах.
Подготовь итоговый вывод о применении промптов prompt-1.txt и Philosophical_instruction_v3_5_beta.md + prompt-2.txt для проведения анализа и формирования сводного отчета по производительности СУБД PostgreSQL.
Сравнительный анализ сводных отчётов
Оба отчёта построены на одних и тех же исходных данных (нагрузочное тестирование PostgreSQL 17.5, 8 vCPU, 7.5 ГБ RAM, диски vdd/vdc). Различия в качестве и полноте обусловлены разными промптами:
- result-1.txt сформирован по специализированной инструкции prompt-1.txt (эксперт по производительности PostgreSQL).
- result-2.txt сформирован по комбинации Philosophical_instruction_v3_5_beta.md (универсальная эпистемическая инструкция) + prompt-2.txt (сокращённый шаблон отчёта).
Ключевые отличия в сводных отчётах
Полнота параметров СУБД
result-1 (prompt-1):
- Перечислены: shared_buffers, effective_cache_size, work_mem, checkpoint_timeout, max_wal_size, random_page_cost, effective_io_concurrency, huge_pages и др.
result-2 (philosophical + prompt-2):
- Перечислены базовые параметры, отсутствуют checkpoint_timeout, max_wal_size, random_page_cost, effective_io_concurrency, huge_pages.
Обработка неопределённости
result-1:
- Явно указано, каких данных не хватает (планы запросов, размеры объектов, тип дисков, точные единицы max_wal_size).
result-2:
- Отсутствует явный перечень недостающих данных. Ограничения анализа не выделены.
Маркировка критичности
result-1:
- Использует текстовые индикаторы (ALARM, OK, INFO) в разделах относительных показателей, но без унифицированного цветового кода.
result-2:
- Использует те же текстовые маркеры (ALARM, OK, INFO), но также присутствуют числовые пороги и ссылки на «критическое значение» ВКО.
Статистическая глубина
result-1:
- Приводит коэффициенты корреляции, R², углы трендов. Нет вычисленного индекса CPI (Correlation Priority Index).
result-2:
- Содержит более детальную статистику: CPI для многих пар метрик, дополнительные корреляции (грязные страницы с bo, sy, free), анализ vm.dirty страниц.
Структурированность итогов
result-1:
- Итоги после каждого подраздела (1.1, 1.2, 1.3, 1.4) и отдельно по каждому блоку анализа IO.
result-2:
- Итоги также присутствуют, но иногда объединены (например, итог по 1.3 включает несколько подразделов).
Критичность к корреляциям
result-1:
- Предупреждает: «корреляция не является причинно-следственной», «может быть математической зависимостью». Отмечает артефакты агрегации.
result-2:
- Менее скептична: интерпретирует высокие корреляции как прямые связи, реже оговаривает возможные ложные зависимости.
Использование светофоров (🟢🟡🔴⬛)
Оба отчёта:
- Не используют символьные светофоры (только текстовые маркеры «ALARM/OK/INFO»).
Причины влияния Philosophical_instruction_v3_5_beta.md и prompt-2.txt
Влияние философской инструкции
- Эпистемическая честность – инструкция требует проверять источники, фальсифицируемость, избегать галлюцинаций. В result-2 это проявилось в более строгой статистической проверке (p-value, R², CPI) и в маркировке пороговых значений как «ALARM».
- Научный метод и протоколы – предписывает использовать Multi-Hypothesis, CoVe, Pre-Mortem и др. В отчёте это отразилось в детальном переборе корреляций и в явном указании «модель непригодна» при низком R².
- Отсутствие специализации – инструкция не содержит знаний о PostgreSQL (параметры checkpoint_timeout, random_page_cost и т.п.), поэтому эти детали не были запрошены или включены.
- Светофоры – инструкция требует их, но в prompt-2 нет указания на формат вывода (символы 🟢🟡🔴⬛), поэтому агент использовал текстовые маркеры, что является частичным соблюдением.
Влияние prompt-2.txt (сокращённый шаблон)
- Шаблон короче и не требует перечисления всех параметров СУБД, указания границ применимости данных, проверки внутренней согласованности метрик.
- Нет явного требования «если данных недостаточно – указать, каких именно». Это привело к тому, что result-2 не фиксирует пробелы (например, отсутствие планов запросов, размеров таблиц).
- Шаблон не требует анализа возможных артефактов агрегации, поэтому result-2 не предупреждает о ложных корреляциях.
Итоговый вывод о применении промптов
Для prompt-1.txt (специализированный)
Сильные стороны:
- Полный охват параметров PostgreSQL.
- Явное указание на недостающие данные.
- Критическая оценка корреляций (не путать с причинностью).
- Соответствие отраслевым стандартам отчётов по производительности СУБД.
Слабые стороны:
- Меньше статистических метрик (CPI, детальные dirty pages).
- Нет унифицированной маркировки критичности.
Рекомендация: предпочтителен для глубокого экспертного анализа производительности PostgreSQL, особенно при поиске узких мест и подготовке формального отчёта.
Для Philosophical_instruction + prompt-2.txt
Сильные стороны:
- Строгая статистическая верификация (R², p-value, CPI).
- Наглядные маркеры «ALARM/OK/INFO».
- Детальный анализ грязных страниц и swap-активности.
Слабые стороны:
- Пропуск важных параметров СУБД (checkpoint, random_page_cost).
- Отсутствие явного перечня недостающих данных.
- Склонность к переоценке корреляций (меньше оговорок).
Рекомендация: может использоваться для быстрой предварительной оценки или для неспециалистов, которым важна статистическая достоверность, но не требуется глубокая экспертиза PostgreSQL. Не подходит для финального отчёта по производительности.
Общее заключение
- Ни один из отчётов не является идеальным. prompt-1 даёт более качественный анализ с точки зрения полноты и осторожности, но менее детализирован в статистических метриках.
- Добавление философской инструкции к специализированному промпту могло бы дать лучший результат: объединить полноту параметров PostgreSQL с эпистемической строгостью (светофоры, CPI, проверка фальсифицируемости).
- Для штатного использования в системе PG_EXPECTO рекомендуется доработать prompt-1.txt, добавив в него требования:
- использовать унифицированные маркеры критичности (например, 🟢🟡🔴⬛);
- вычислять индекс CPI для корреляций;
- включать анализ vm.dirty страниц.
- При этом сохранить все существующие требования (указание недостающих данных, проверка артефактов, запрет рекомендаций).
Послесловие
Представленное сравнение наглядно демонстрирует, что выбор промпта критически влияет на качество и полноту отчёта по нагрузочному тестированию PostgreSQL. Узкопредметная инструкция PG_EXPECTO обеспечивает глубокий охват параметров СУБД, а философская рамка добавляет статистическую строгость и честность оценок, но за счёт потери экспертных деталей. Оптимальным решением видится интеграция эпистемических протоколов (светофоры, CPI, проверка фальсифицируемости) непосредственно в специализированный промпт PG_EXPECTO — это позволит сочетать полноту анализа с высокой достоверностью выводов.