
Представьте, что вы учите робота играть в дартс. Он бросает дротики — и вот результаты:
- первый бросок — прямо в яблочко (ошибка 0);
- второй — на 2 см левее (ошибка −2);
- третий — на 3 см выше (ошибка +3).
Как оценить, насколько хорошо робот играет? Кажется, проще некуда — достаточно сложить ошибки: 0+(−2)+3=1. Неплохо, но это обман: два промаха (−2 и +3) почти компенсировали друг друга!
Тут на помощь приходит среднеквадратичная ошибка (СКО или MSE — Mean Squared Error).
В чем же ее прелесть?
Среднеквадратичная ошибка показывает, насколько результаты расчета разнятся с реальными цифрами — но с одним хитрым трюком: все ошибки возводятся в квадрат.
Шаг 1. Считаем ошибки (разницу между реальным и предсказанным):
- бросок 1: 0
- бросок 2: −2
- бросок 3: +3
Шаг 2. Возводим ошибки в квадрат в записи языка программирования Python. (Две звездочки — это возведение в степень, двойка после звездочек — показатель степени.) Вот тут и начинается магия:
- 0 ** 2 = 0
- (−2) ** 2 = 4
- 3 ** 2 = 9
Шаг 3. Считаем среднее квадратов:
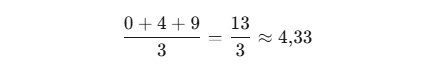
Шаг 4. Извлекаем квадратный корень (по желанию), чтобы вернуться к исходным единицам измерения — получаем среднеквадратичное отклонение:
Как видите, реальная ошибка вовсе не 1, как могло показаться вначале.
Почему квадрат — это гениально?
Возведение в квадрат даёт два мощных, почти волшебных эффекта.
Он устраняет минусы. Любые числа при возведении в квадрат становятся положительными и они больше не компенсируют другие ошибки. Всё честно!
Квадрат наказывает за большие промахи. Смотрите:
- маленькая ошибка 1 становится 1 ** 2 = 1 (так и осталась единицей);
- средняя ошибка 2 становится 2 ** 2 = 4 (увеличилась в 2 раза);
- большая ошибка 3 становится 3 ** 2 = 9 (увеличилась в 3 раза).
Главный принцип: всё, что меньше 1, после возведения в квадрат становится ещё меньше, а всё, что больше 1, — резко увеличивается. Это заставляет нейросеть особенно сильно «бояться» больших ошибок! Согласитесь, вот так легко и ненавязчиво уже сейчас можно разделить данные на «близкие» и «далекие».
Почему нейросети без среднеквадратичной ошибки как повар без весов?
Нейросети обучаются методом проб и ошибок. И СКО — их главный учитель:
Это показатель прогресса. Нейросеть видит: «О, вчера моя СКО была 5,2, а сегодня 3,1 — я учусь!»
Заставляет быть аккуратной. Квадратные штрафные санкции для нейросети — оберег от грубых ошибок. Лучше сделать несколько мелких промахов, чем один катастрофический.
Даёт единый критерий. Цель программы предельно ясна и она вытекает из предыдущего пункта: добиться значения СКО как можно ближе к 0.
Помогает сравнивать модели. Если две сетки решают одну и ту же задачу с результатом в у нейросети А = 0,5, а у модели Б = 1,2 — очевидно, что А лучше справляется со своей задачей.
Работает с градиентами. Математически производная от квадрата ошибки проста для вычислений — это позволяет быстро и эффективно обновлять веса нейросети.
И еще немного волшебства. Почему «1» — магическое число?
Цифра 1 здесь — своего рода «точка отсчёта»:
Если ошибка меньше единицы (например, 0,5), то после возведения в квадрат она становится ещё меньше (0,25). Это значит, что небольшие промахи «прощаются» нейросети.
Если ошибка больше 1 (например, 2), то после квадрата она резко растёт (4). Это красный сигнал светофора: «Эй, тут что то пошло не так, исправляй!»
Представьте, что вы учитель, а нейросеть — ученик. Если он ошибся на 0,1 балла — вы махнёте рукой. А если на 3 балла — поставите двойку и заставите переделывать!
Краткий итог: почему СКО — супергерой нейросетей?
- Честность: не позволяет ошибкам «компенсировать» друг друга.
- Справедливость: маленькие ошибки почти не влияют на результат, большие — наказываются жёстко.
- Простота: легко считать и оптимизировать.
- Универсальность: работает с любыми данными — от цен на дома до распознавания лиц.
- Наглядность: чем ближе СКО к 0, тем лучше модель. Идеал — 0 (абсолютная точность).
Мораль истории: среднеквадратичная ошибка — это не скучная формула, а умный способ научить нейросеть быть аккуратной. Она говорит: «Мелкие огрехи допустимы, но крупных промахов — ни в коем случае!»