

Alibaba Research выпустила языковую модель нового поколения. Разработчики из команды Qwen сосредоточились не на том, чтобы модель лучше отвечала на вопросы, а на том, чтобы она умела самостоятельно выполнять длинные цепочки действий: планировать, запускать код, исправлять ошибки и двигаться дальше без подсказок.
Главное структурное отличие от предшественника — контекстное окно в один миллион токенов по умолчанию. Для понимания масштаба: это примерно 750 тысяч слов, или несколько крупных романов одновременно. Благодаря этому модель держит в «голове» весь большой проект целиком: историю переписки, код, документацию, результаты предыдущих шагов.
В области автономного написания кода Qwen3.6-Plus показывает результаты вплотную к лидерам отрасли. На бенчмарке SWE-bench Verified — это стандартный тест, где модель должна самостоятельно найти и починить реальный баг в публичном репозитории на GitHub — новинка набрала 78,8 балла. Claude Opus 4.5 от Anthropic получил 80,9. Разница небольшая, но контекст важен: Qwen3.6-Plus при этом дешевле в эксплуатации для большинства сценариев.
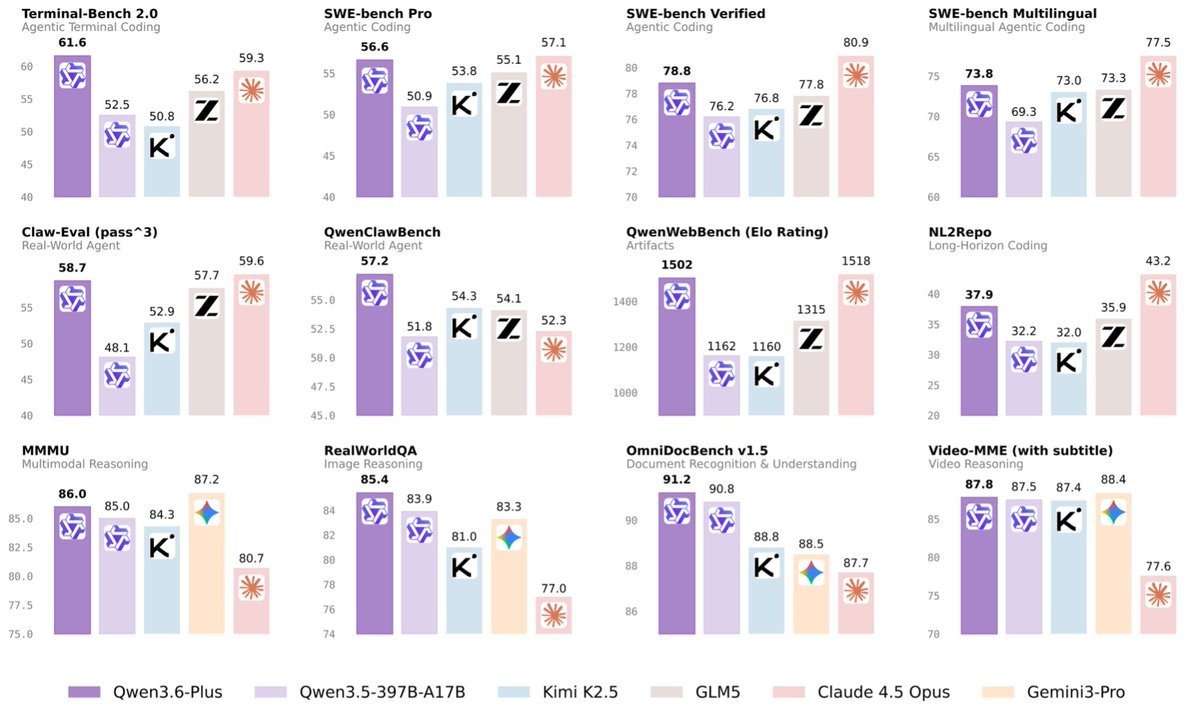
Отдельно стоит выделить Terminal-Bench 2.0 — тест на работу в настоящем терминале Linux с реальными файлами, процессами и временными ограничениями. Здесь модель набрала 61,6 балла, и это лучший результат среди всех участников сравнения, включая Claude и GLM5.
Qwen3.6-Plus воспринимает не только текст, но и изображения, скриншоты интерфейсов, видео. По тесту RealWorldQA, где нужно отвечать на вопросы по фотографиям реальных ситуаций, модель набрала 85,4 — это выше, чем у GPT-5.2 (83,3) и Gemini-3 Pro (83,3). Практическое применение — модель видит скриншот сайта или мокап дизайна и сразу пишет рабочий HTML/CSS/JS-код. В автоматическом рейтинге фронтенд-разработки QwenWebBench новинка набрала 1501,7 балла против 1159,5 у Kimi-K2.5.
Модель доступна через API Alibaba Cloud Model Studio. Ключевая особенность интеграции — поддержка протокола Anthropic, то есть ее можно подключить к Claude Code просто через переменные окружения, без переписывания существующих скриптов. Аналогично работает совместимость с OpenAI-форматом.
Среди поддерживаемых инструментов — OpenClaw, Qwen Code, Cline и другие популярные агентные оболочки для терминала. Новый параметр API сохраняет цепочку рассуждений модели между шагами — это снижает избыточные вычисления в длинных агентных сессиях.
Alibaba анонсировала скорый открытый релиз компактных версий модели. Это означает, что часть возможностей Qwen3.6-Plus появится в локальном запуске — без API и облака.
Также недавно писали, что эксперты назвали OpenClaw катастрофой в сфере безопасности. Подробности в статье.