Microsoft превратила Copilot Researcher в систему из двух моделей: OpenAI отвечает за драфт, Anthropic за аудит.
Проблема одной модели в том, что ей приходится одновременно планировать, искать, писать и проверять саму себя. Именно поэтому бизнес сомневается в таких отчётах: выглядят аккуратно, но могут опираться на слабые или непроверенные данные.
Подход Critique разделяет роли. Одна модель исследует и пишет, другая проверяет источники, полноту и фактическую обоснованность перед финальной отправкой отчёта.
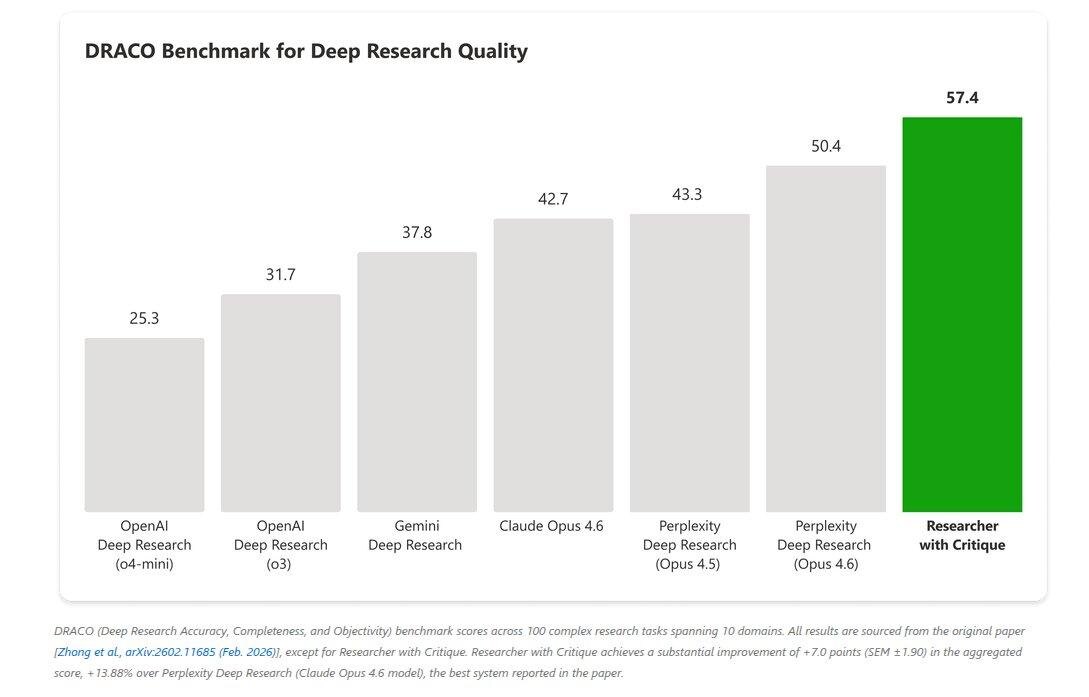
На бенчмарке DRACO (100 задач, 10 доменов, оценка через GPT-5.2) система набрала 57.4 балла. Это на 13.88% выше лучшего результата из исследования.
Основной прирост в ширине и глубине анализа, качестве подачи и точности фактов. Логично, потому что отдельная модель-ревьюер заточена на поиск пробелов, слабых аргументов и сомнительных источников.
Главное здесь не «две модели лучше одной», а разделение ролей. Каждая модель делает свою узкую задачу, вместо попытки одной системы быть исследователем, автором, редактором и фактчекером одновременно.
И это уже не столько исследовательский прорыв, сколько продуктовый ход. Microsoft продаёт не просто ИИ, а проверенные отчёты. Бизнесу важнее не бенчмарки, а возможность доверять результату и использовать его в работе.
https://x.com/satyanadella/status/2038604619795042716