
В Японском передовом институте науки и технологий (JAIST) разработали диффузионную модель искусственного интеллекта, выполняющую архитектурный эскиз по текстовому запросу.
Разработка описана в журнале Frontiers of Architectural Research. Она значительно превзошла аналоги, которые зачастую выдают визуально эффектные, но абсурдные результаты. Новая система генерирует изображения зданий, подчиняющиеся архитектурной логике, что ее по-настоящему полезным и надежным инструментом.
Работа архитектора состоит, по сути, в том, чтобы воплотить концептуальный замысел в наглядный образ. Модели «текст-в-изображение» в этом смысле — настоящая находка: они рисуют высококачественный рендер по словесному описанию. Некоторые из таких систем могут даже учитывать наброски или данные о глубине. Но чаще они «не понимают» заданные параметры. Например, даже прямой запрос «сгенерируй пятиэтажное здание» может дать на выходе картинку с другим количеством этажей. Причина кроется в обучающих выборках: в них отсутствует детальная разметка, описывающая структуру зданий, поэтому искусственному интеллекту сложно уловить точные пространственные характеристики, такие как этажность или расположение окон и элементов фасада.
В новинке эта проблема решена подгрузкой данных из внешних источников. Такое объединение текстовых запросов с информацией из внешних архитектурных баз позволяет модели во время генерации обращаться к реальным архитектурным примерам. Это решение может стать фундаментом для будущих ИИ-инструментов архитектурного проектирования, которые сделают этот процесс проще и быстрее.
«Сегодня качественная архитектурная визуализация требует серьезных навыков и дорогостоящего программного обеспечения. Благодаря нашей разработке отдельные проектировщики и небольшие команды смогут полноценно участвовать в формировании собственной среды, выражать свои предпочтения и видеть реалистичный результат без привлечения большого профессионального коллектива», — говорит специалист по генеративному ИИ Се Хаоран, руководивший исследованием.
Алгоритм работы системы построен по образу и подобию реального проектного процесса. Архитекторы обычно начинают с простых набросков, задающих общую форму и планировку здания, а затем постепенно детализируют их — добавляют окна, двери, элементы фасада. ИИ-проектировщик выполняет те же действия в том же порядке. Сначала превращает текстовый запрос в простой структурный набросок, на котором представлен общий облик здания и корректное количество этажей. Затем набросок уточняется: из базы реальных строительных элементов добавляются детали. На заключительном этапе доработанный эскиз объединяется с исходным текстовым описанием — и система выдает реалистичное изображение здания, точно отвечающее замыслу проектировщика.
Чтобы оценить работу метода, исследователи провели эксперименты на примере проектов университетских кампусов — именно здесь контроль этажности и расположения окон и входов имеет особое значение. Были составлены три специализированных датасета: набор объемных моделей зданий (2200 изображений), набор архитектурных элементов (4000 изображений различных вариантов окон и входных групп) и набор пар «набросок — рендер» (1600 примеров, связывающих детализированные наброски, текстовые описания и финальные визуализации зданий кампуса).
В количественных тестах система показала 70,5% точности при воспроизведении заданного количества этажей.
Выдающимся этот результат явно не выглядит. Однако авторы считают его настоящим прорывом. Во-первых, тут имеется в виду первый этап проектирования, во-вторых, это не потолок модели, а доказательство ее работоспособности, в-третьих, и это самое главное — точность остальных архитектурных моделей еще хуже.
Качество работы ИИ-архитектора проверили его живые коллеги — 56 магистрантов архитектурных и дизайнерских специальностей. Они оценили качество изображений, их соответствие запросу и точность архитектурных деталей по пятибалльной шкале Ликерта (где 1 — «очень неудовлетворительно», 5 — «очень удовлетворительно») — во всех категориях средние оценки превысили 4 балла.
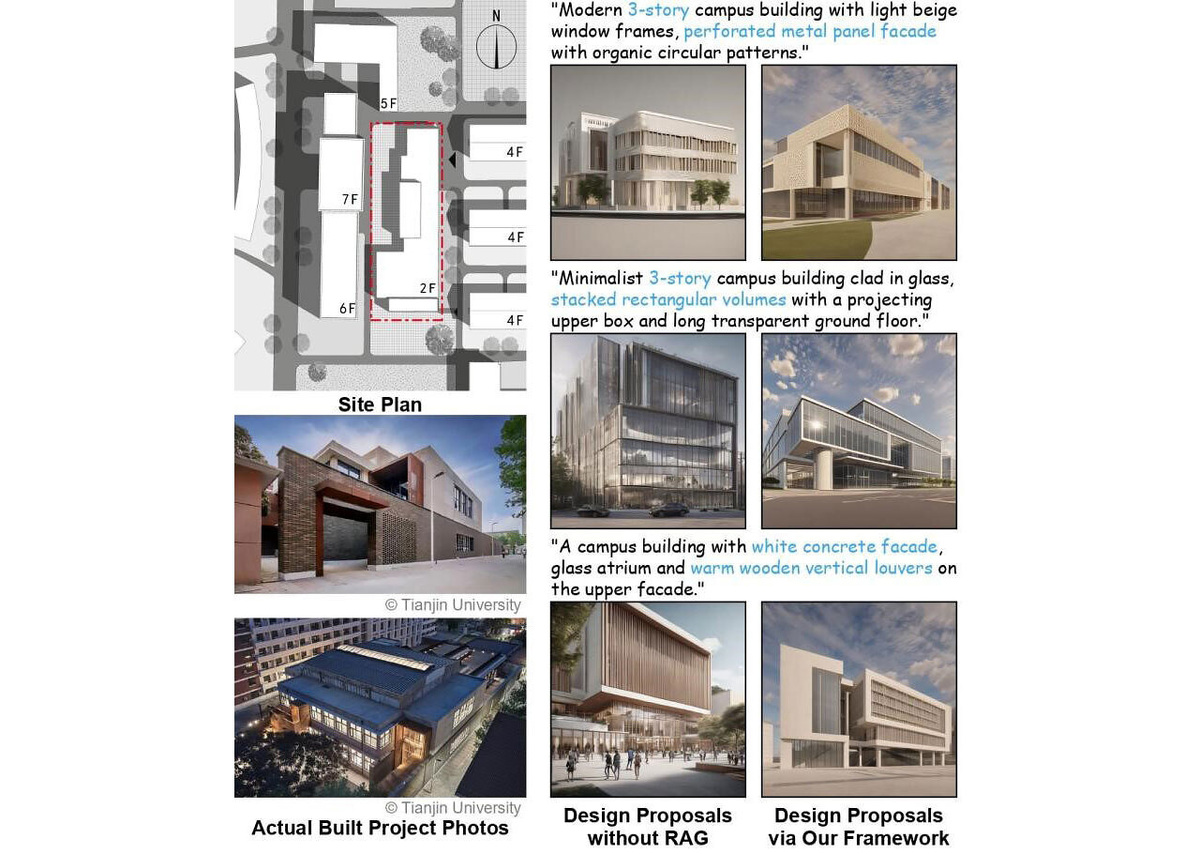
Такая система способна значительно изменить работу на ранних этапах архитектурного проектирования. «Проектировщики смогут оперативно корректировать решения прямо во время обсуждения с заказчиком, сокращая цикл итераций. Планировщики и девелоперы получат возможность визуализировать и сравнивать десятки альтернативных вариантов, не приступая к детальному моделированию», — заключил Се.
Подсчитано: ИИ уже пишет почти треть нового программного кода
Архитекторы подсмотрели у стрекоз идею создания самых крепких сводов
Подписывайтесь и читайте «Науку» в MAX