Сегодня разбираемся, что скрывается под кулером вашей видеокарты или в чипе MacBook. Почему одни GPU лучше для игр, другие — для нейросетей, а третьи вообще стирают грани между памятью процессора и видеокарты? Поехали.
1. Архитектура: как GPU думают
Если процессор (CPU) — это «швейцарский нож» с 8–16 мощными ножами, то GPU — это армия из тысяч маленьких, но одинаковых лезвий. Они идеально подходят для задач, где нужно выполнить однотипные операции над миллионами данных: рендеринг, симуляции, обучение нейросетей.
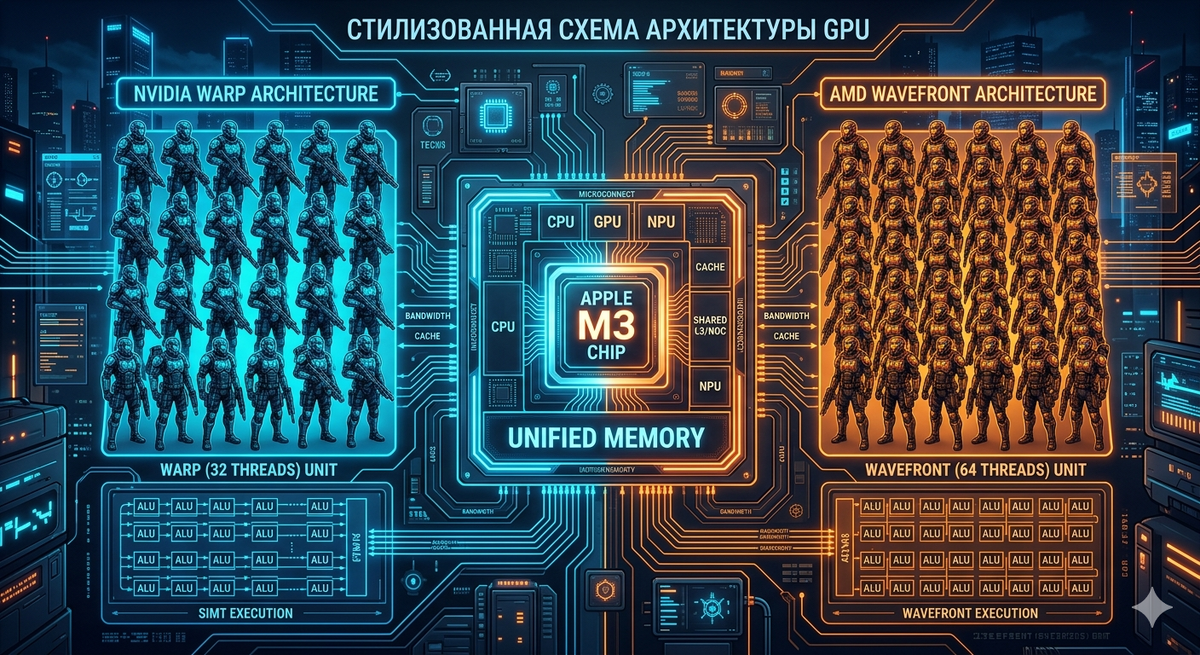
У NVIDIA — классика: «варпы» по 32 потока. Представьте отряд, где все идут строем, пока не встретят развилку. Если пути расходятся, часть отряда ждёт — это называется расхождение потоков. В новых архитектурах (начиная с Volta) NVIDIA научилась управлять этим гибче.
У AMD — отряды по 64 потока (волновые фронты). В два раза больше, поэтому плотность выше. Зато в игровых картах RDNA 3 есть фишка: один вычислительный блок может выполнять две разные инструкции одновременно (например, дробное число и целое). Это позволяет выжимать больше кадров в играх.
У Apple — своя экосистема. В чипах M-серии GPU работает в едином адресном пространстве с CPU. Это значит, что данные не нужно перекидывать туда-сюда через PCIe, как в обычных ПК. Результат — безумно быстрый доступ к памяти, но за всё приходится платить: вы не сможете просто так взять и поставить «видяху» в Mac Pro.
2. Где живут данные: память и кэш
У любой видеокарты есть своя быстрая память (VRAM), но доступ к ней — самое узкое место. Инженеры используют хитрые конструкции:
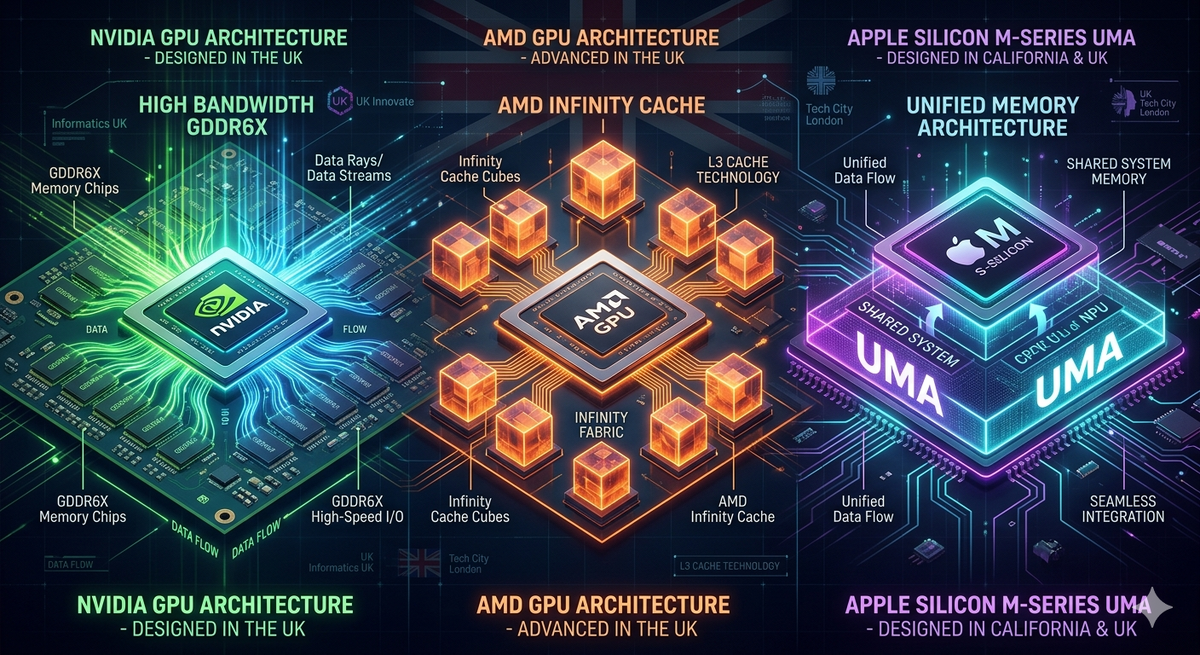
- NVIDIA (RTX 4090) — 96 КБ кэша на каждый мультипроцессор, который можно разделить между общим кэшем и памятью для ядер. Плюс огромный L2-кэш, который «подсасывает» повторяющиеся данные, чтобы не дёргать медленную GDDR6X.
- AMD (RDNA 3) — сделали чиплетную конструкцию: основное вычислительное ядро (5 нм) и отдельные кристаллы с кэшем (Infinity Cache). Это как иметь промежуточный склад между процессором и складом видеопамяти — задержки снижаются.
- Apple — вообще отказалась от отдельной VRAM. В M-серии стоит LPDDR5, которую используют и CPU, и GPU. За счёт этого приложения для нейросетей (например, Stable Diffusion) могут работать без копирования данных туда-сюда. Минус: если модель нейросети весит больше доступной памяти — только внешний SSD спасёт, но скорость упадёт.
3. Тензорные ядра: оружие для ИИ
Современные GPU — это не просто «видеокарты». У них есть специализированные блоки для матричных вычислений, которые используют нейросети.
- NVIDIA Tensor Cores (4-е поколение) — могут работать с форматами FP8 (8-битная плавающая точка), что критически важно для больших языковых моделей (LLM). Благодаря им инференс (работа уже обученной сети) происходит в разы быстрее.
- AMD Matrix Cores — аналог тензорных ядер. Железно они даже мощнее у некоторых серверных карт (MI300X), но софт (библиотеки ROCm) пока уступает экосистеме NVIDIA CUDA. Это как иметь суперкар, но только с грунтовыми дорогами.
- Apple Neural Engine (ANE) — выделенные 16–32 ядра для нейросетей. В связке с GPU через Metal Performance Shaders они могут эффективно запускать локальные LLM, но без полноценных тензорных ядер в классическом понимании. Для большинства пользователей M3 хватит за глаза, но для обучения огромных моделей Apple не конкурент.
4. Когда одной карты мало: объединение GPU
Для суперкомпьютеров и обучения ИИ-моделей нужно объединять сотни GPU. Здесь начинается настоящая магия:
- NVIDIA NVLink — специальная шина, которая позволяет видеокартам обмениваться данными со скоростью 900 ГБ/с (это в 15 раз быстрее, чем PCIe 5.0). В системе GB200 (Blackwell) до 576 GPU работают как один гигантский чип.
- AMD Infinity Fabric — аналогичная технология, особенно круто реализованная в гибридных чипах MI300A, где CPU и GPU находятся на одной подложке и общаются без задержек.
- Apple — масштабирование ограничено двумя чипами через UltraFusion (в M2 Ultra). Для домашнего продакшена хватает, но для дата-центров Apple не идёт.
5. Софт решает всё
Самое главное оружие NVIDIA — это CUDA. Библиотеки cuBLAS, cuDNN, TensorRT настолько оптимизированы, что даже если у конкурента железо быстрее, на CUDA код будет работать стабильнее и с меньшими танцами с бубном.
AMD развивает ROCm — он уже позволяет запускать многие CUDA-программы через транслятор HIP, но требует больше времени на настройку.
Apple держится на Metal и Metal Performance Shaders. Для приложений, оптимизированных под Mac (например, Final Cut Pro или DaVinci Resolve), производительность выдающаяся, а для «сырых» AI-задач придётся искать обходные пути.
Итог: что выбрать?
- Для LLM-инференса и тренировок — NVIDIA Blackwell с поддержкой FP8 и NVLink.
- Для HPC-задач с огромными объёмами данных — AMD MI300X даёт больше памяти (до 144 ГБ HBM3e), но готовься к экспериментам с софтом.
- Для экосистемы Apple и гибридных задач — M3 Max / M2 Ultra — технологический шедевр единой памяти, но без возможности расширения.
Какую архитектуру вы предпочитаете? Пишите в комментариях. А если хотите оживить картинку — используйте промпты выше в любом генераторе, чтобы увидеть, как видят эти технологии нейросети.
Если нужно больше технических подробностей — дайте знать, разберём PCIe 6.0, CXL-протоколы или внутренности нейронных движков.