Вы когда-нибудь ждали, пока нейросеть обучится, и чувствовали, что время тянется бесконечно? А может, слышали, что современные кластеры для ИИ стоят миллиарды, но почему‑то не выдают полную мощность? Часто проблема не в самих видеокартах, а в том, как они общаются друг с другом.
Сегодня разберём главное сражение в мире высокопроизводительных вычислений: InfiniBand против Ethernet. Сложные термины оставим инженерам, а вы получите чёткое понимание, почему одна технология делает обучение GPT‑5 быстрее, а другая – гибче для облаков. И да, я расскажу, как обычный «плохой» сервер может затормозить целый дата‑центр.

Почему видеокарты не могут работать в одиночку
Современные нейросети — это десятки тысяч GPU, которые постоянно обмениваются данными. Если они «заговорят» с задержкой или начнут терять пакеты, обучение затянется на недели, а счета за электричество улетят в космос.
Вот тут и вступают в игру две технологии. Обе позволяют видеокартам общаться напрямую (RDMA), минуя процессор. Но делают это по‑разному.
Физический уровень: почему биты не должны теряться
Представьте, что ваши видеокарты – это супер‑курьеры. Они передают друг другу тонны данных. Если курьер хоть раз ошибётся адресом или уронит посылку, вся работа встанет.
InfiniBand работает как курьерская служба с гарантией: на уровне канала связи потери пакетов просто не существует. Если линия начинает «шуметь» (битовые ошибки), связь автоматически перестраивается, но повреждённые данные никогда не уходят дальше.
Ethernet с RoCEv2 – это обычная почта, в которую добавили спецдоставку. Данные упаковываются в стандартные интернет‑пакеты и летят по тем же правилам, что и ваши любимые видео с котами. Но обычные Ethernet‑коммутаторы работают по принципу «принял – сохранил – отправил». При перегрузке они просто начинают терять пакеты. А для ИИ‑кластера потеря пакета – как выпадение из видеозвонка в самый ответственный момент. Только масштаб – миллиарды операций.
Управление пробками: когда один сервер тормозит всех
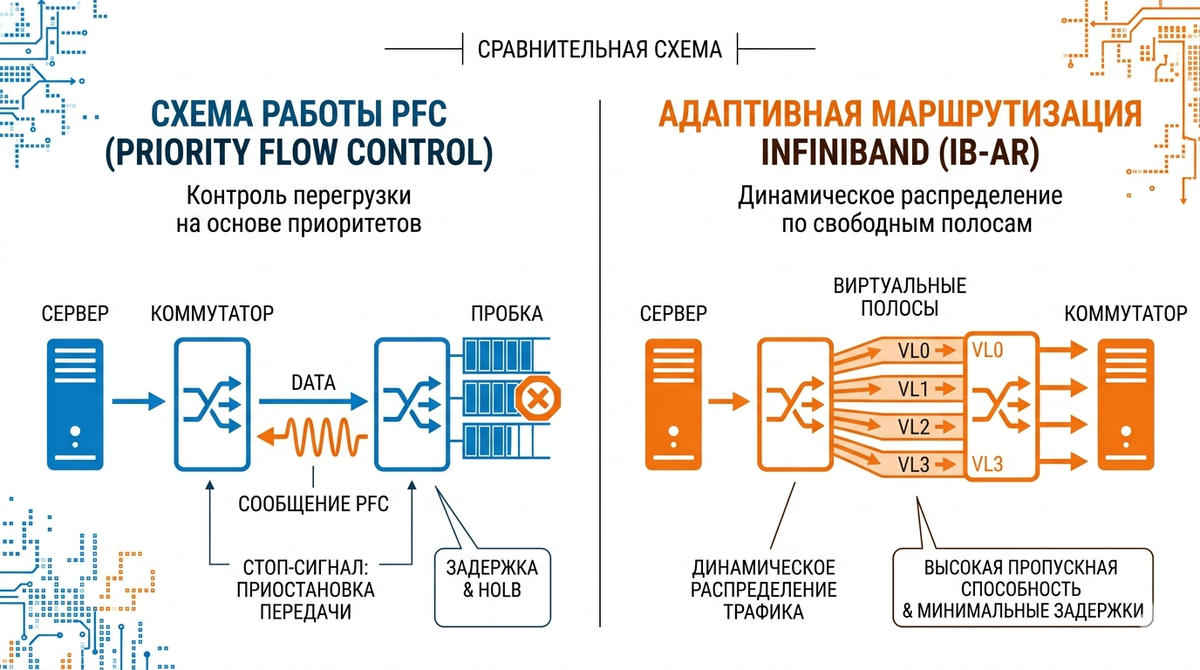
Здесь начинается настоящая драма. В InfiniBand инженеры предусмотрели «умные полосы» – 16 виртуальных дорожек на каждом кабеле. Данные сами выбирают свободную полосу, а коммутаторы режут трафик практически без задержек (сквозной режим). Никаких «пауз» для всех.
В Ethernet же для работы RoCE приходится включать PFC (Priority Flow Control). Это механизм, который говорит: «Стоп! У меня очередь переполнилась, не шли мне больше пакеты!». Проблема в том, что стоп‑сигнал получают все серверы, подключённые к этому порту. Даже те, кто слал данные без проблем.
Аналогия: вы едете по шоссе, впереди одна фура заглохла на узком участке – и вся многополосная трасса встаёт. Вот так работает PFC.
Один «плохой» сервер, создавший лишний трафик, может снизить производительность кластера из 64 000 видеокарт на 30–40%. Чтобы этого избежать, в Ethernet используют алгоритм DCQCN – сложнейшую систему, которая пытается предсказывать перегрузки и сглаживать их. Настройка DCQCN – это высший пилотаж сетевых инженеров, сравнимый с ручной сборкой гоночного двигателя.
Где прячется «магия» ускорения
В мире InfiniBand есть секретное оружие – SHARP (Scalable Hierarchical Aggregation and Reduction Protocol). Это технология, которая позволяет коммутаторам не просто передавать данные, а складывать их прямо внутри сети.
Когда 10 000 видеокарт одновременно обновляют веса нейросети, обычно все данные стекаются на главный сервер, складываются и раздаются обратно. SHARP делает это на уровне сетевых чипов – без участия процессоров и без загрузки шин PCIe. Время выполнения такой коллективной операции сокращается с логарифмического до постоянного. Другими словами, чем больше видеокарт, тем выгоднее.
В Ethernet такого «интеллекта» внутри коммутаторов нет. Все операции сложения выполняются либо на специальных DPU, либо на самих GPU, используя библиотеку NCCL.
Что выбрать для своих задач?
Здесь нет универсального ответа. Всё зависит от того, что вы строите.
Вы обучаете большую языковую модель (GPT‑уровня) на десятках тысяч H100.
Ваш выбор – InfiniBand. Причина – SHARP. В таких задачах обмен данными между видеокартами занимает до 30–40% времени обучения. SHARP вырезает эти задержки прямо в сети. Без этого ваши GPU будут простаивать, даже если у вас 400‑гигабитные каналы.
Вы облачный провайдер, сдаёте мощности в аренду.
Здесь выгоднее RoCEv2 на качественном Ethernet (например, Spectrum‑X или Arista 7800R). Вы получаете гибкость: легко изолируете клиентов, делаете динамическую маршрутизацию, не привязываетесь к одному вендору. Но будьте готовы, что ваша команда должна быть уровня «бывшие инженеры Google», чтобы вылизать настройки на 20 000 портов.
Шпаргалка для тех, кто принимает решения
InfiniBandRoCEv2 на Ethernet✅ Гарантированная доставка без потерь✅ Знакомая инфраструктура, гибкость✅ SHARP – ускорение коллективных операций✅ Дешевле на старте (commodity hardware)✅ Низкая задержка, предсказуемое поведение✅ Возможность обслуживания без остановки❌ Жёсткая привязка к одному вендору (NVIDIA)❌ Требует тончайшей настройки PFC/ECN/DCQCN❌ Сложности с L3‑маршрутизацией и арендой❌ Риск просадок производительности
Если вы строите выделенную ИИ‑фабрику и не хотите тратить полгода на вылизывание сетевых параметров – берите InfiniBand. Если у вас уже есть мощная команда SRE и вы сдаёте мощности разным клиентам – Ethernet даст вам свободу.
А вы уже сталкивались с «тормозами» в работе нейросетей?
Может, замечали, как медленно обучаются модели, когда на серверах высокая нагрузка? Поделитесь в комментариях – я расскажу, как диагностировать сетевые проблемы ещё до того, как они скажутся на производительности.
Было полезно? Жмите лайк! 🔥 Таким образом вы не только поддерживаете канал, но и помогаете другим читателям найти этот материал. Хотите каждый день узнавать что-то новое и вдохновляться? Тогда ПОДПИШИТЕСЬ прямо сейчас — дверь в мир увлекательных открытий открыта для вас. И не болейте! Крепкого здоровья и отличного настроения. Кстати, а какая тема волнует лично вас? Заказывайте темы для статей в комментариях, задавайте вопросы — давайте разбираться вместе.
Пусть биты летят без потерь,
А кластеры выдают тонны.
Вам – гибкости, если в облака,
И скорости, если для кода.