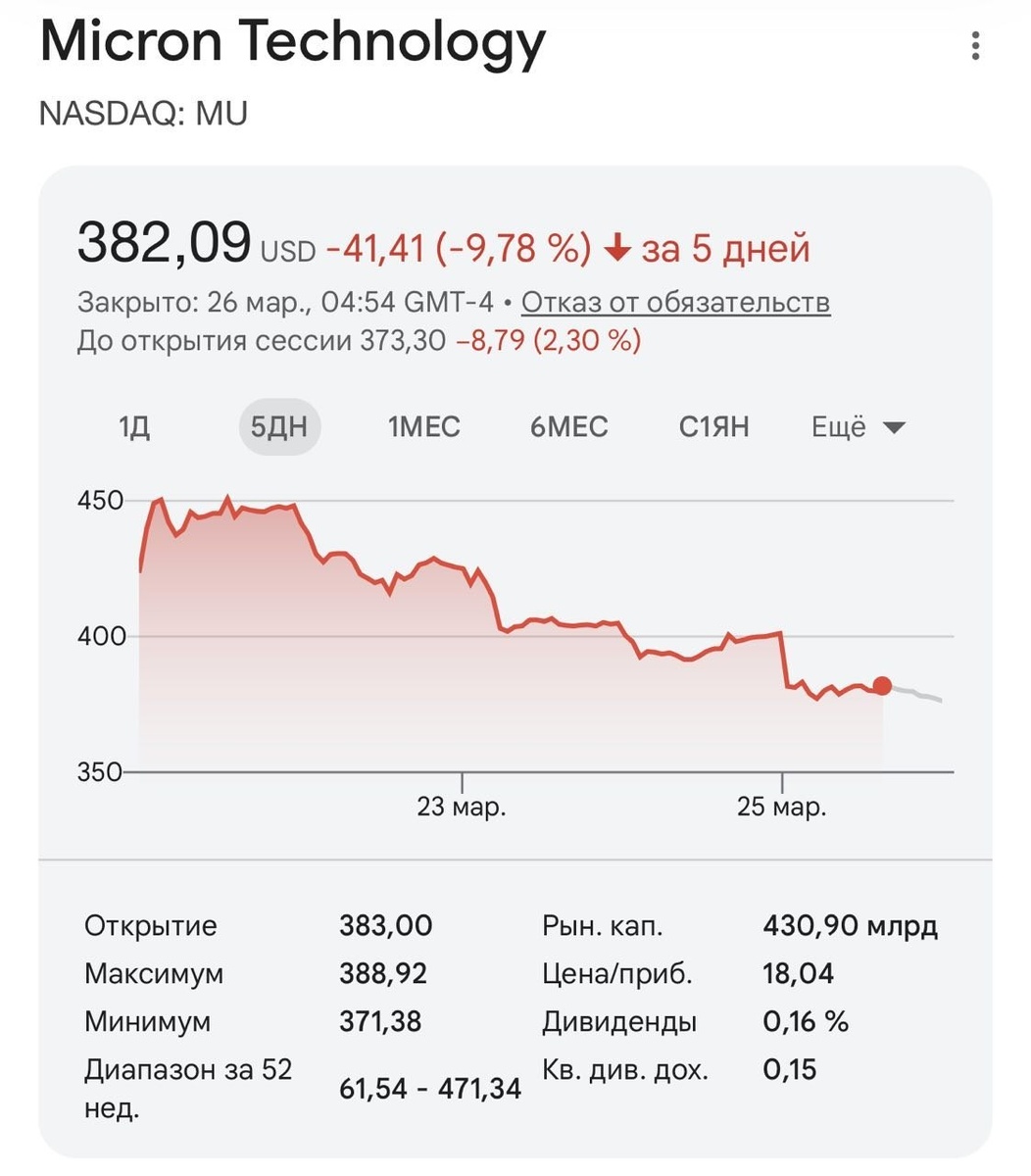
Они выпустили алгоритм сжатия для LLM-моделей TurboQuant: он уменьшает необходимые ресурсы для KV cache — это такая память нейросети, которая позволяет помнить каждый предыдущий токен (слово) во время генерации ответа. Результаты потрясающие: требования к памяти с алгоритмом снижаются в 6 раз, а скорость работы — увеличивается на 8 раз, при этом без потери в точности. Инвесторы новость оценили и побежали сливать акции производителей памяти — Micron, SK Hynix. @exploitex
Google спасёт нас от дефицита ОЗУ — компания добра внезапно нашла решения кризиса.
Они выпустили алгоритм сжатия для LLM-моделей TurboQuant: он уменьшает необходимые ресурсы для KV cache — это такая память нейросети, которая позволяет помнить каждый предыдущий токен (слово) во время генерации ответа.
Результаты потрясающие: требования к памяти с алгоритмом снижаются в 6 раз, а скорость работы — увеличивается на 8 раз, при этом без потери в точности.
Инвесторы новость оценили и побежали сливать акции производителей памяти — Micron, SK Hynix.