Наташ, ты спишь? Мы там все уронили и мониторинг твой не сработал…
Мониторинг – тема сложная, гораздо сложнее чем кажется на первый взгляд и главное в ней правильно настроить объект мониторинга, чтобы получать нужное и не получать ненужное.
А еще хуже, когда мы мониторим вообще не то, что надо. В результате о случившемся нас оповестит не мониторинг, а разгневанные пользователи.
На днях обновляли 1С:Предприятие в одной подопечной организации и местный админ попросил что-нибудь простое и современное для мониторинга доступности основных сервисов, чтобы просто видеть, что живо, а что упало.
Показали ему Uptime Kuma, понравилось, запустили. Он пошел добавлять узлы, а мы принялись за свою работу, а потом все-таки заглянули посмотреть, что он там сделал и сильно удивились.
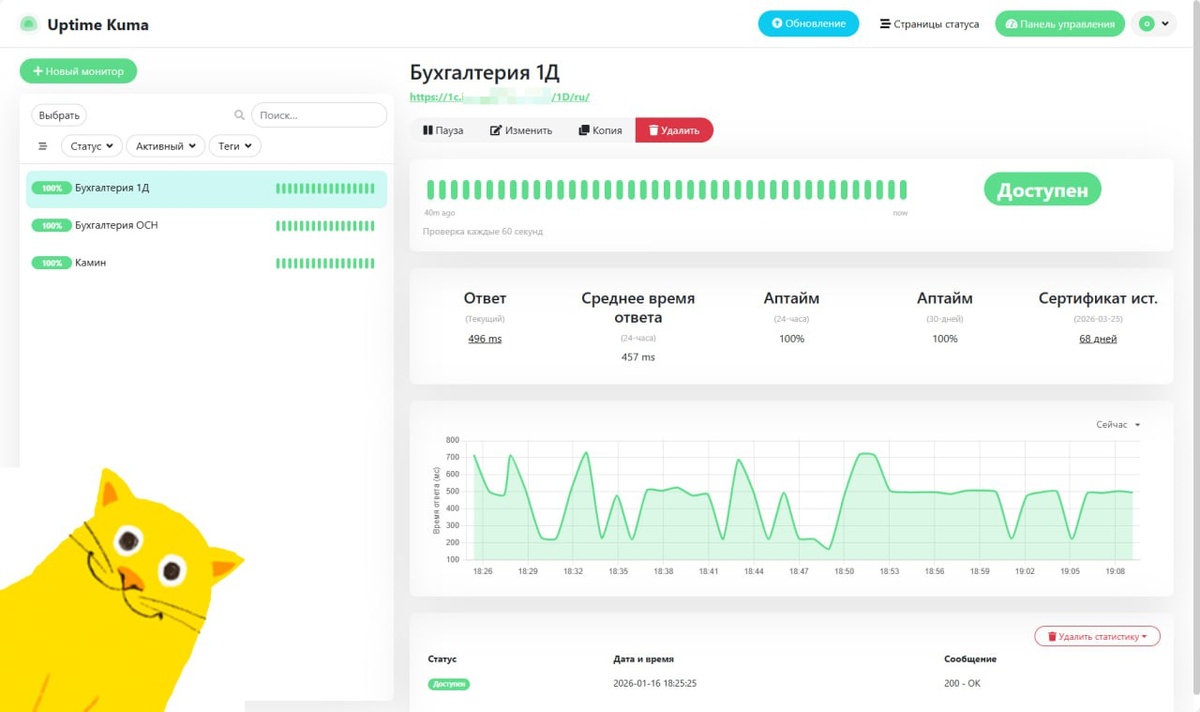
В общем это классика жанра. В нашем случае это был веб-сервер с опубликованными на нем базами 1С:Предприятие, скажем 1с.example.com, ну вот наш коллега ничтоже сумняшеся взял и добавил в монитор именно этот узел.
После чего мы предложили ему сесть и подумать, что именно будет контролировать такой монитор? Чтобы активировать мыслительный процесс мы предложили перейти по этой ссылке и полюбоваться на стандартную заглушку IIS/Apache.
Да, такой монитор покажет нам жив ли веб-сервер в принципе, но никакого контроля над опубликованными на нем сервисах у нас не будет. В данном случае хуже будет только Ping, хотя и так многие делают, а потом сильно удивляются, когда их будят рано утром.
А вот здесь самое время подумать, что именно нам нужно мониторить. Веб-сервер? Его статус в вакууме нам не даст никакой полезной информации. Веб-приложения? Именно, вот именно их состояние нам и интересно.
Мы вполне можем получить ситуацию, когда веб-сервер работает нормально, а веб-приложение или сайт вдруг начали выдавать коды 4хх или 5хх и наша задача узнать об этом своевременно, а не тогда, когда найдут и разбудят.
Поэтому добавляем в мониторинг не один узел, а три, по количеству опубликованных веб-сервисов (понятно, что у вас может быть любое количество) и теперь мы будем видеть состояние каждого из них в отдельности.
Теперь вы можете своевременно реагировать на происходящее и четко понимать, что и с кем случилось.
Этот подход следует применять для любых систем мониторинга и сервисов. Помните, что нас интересует не состояние узла, а работоспособность развернутых на нем сервисов, поэтому мониторить нам нужно именно их, а потом уже все остальное.
Кстати, состоянием узла тоже пренебрегать не стоит. Особенно если есть возможность настраивать зависимости. Скажем в Zabbix вы можете настроить зависимости триггеров сервисов от состояния узла и если он полностью выключен, то Zabbix не будет спамить вас десятком сообщений о недоступности каждого сервиса в отдельности, а просто скажет, что узел такой-то не в сети.
Но первичны у нас именно сервисы, помните об этом!