GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
GitFlic - pg_expecto - статистический анализ производительности и ожиданий СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен
Предисловие
В настоящем отчете представлены результаты сравнительного статистического анализа производительности СУБД PostgreSQL 17.5 в условиях модификации ключевого параметра конфигурации — размера разделяемого буферного кэша (shared_buffers). Исследование проведено методом корреляционного анализа ожиданий (wait events) и метрик операционной системы (vmstat) при выполнении синтетического нагрузочного сценария «Update only». Целью работы являлась количественная оценка влияния увеличения shared_buffers с 2 до 4 ГБ на операционную скорость, структуру ожиданий и характер взаимодействия с дисковой подсистемой.
Сценарий нагрузочного тестирования
# НАСТРОЙКИ НАГРУЗОЧНОГО ТЕСТИРОВАНИЯ
# Начальная нагрузка
start_load = 30
# Максимальная нагрузка
finish_load = 80
# Тестовая БД
testdb = default
# Тип синтетической нагрузки
load_mode = oltp
# Веса сценариев по умолчанию
scenario1 = 0.5
# Размер тестовой БД
#~10GB
scale = 685
Сценарий нагрузочного тестирования
Постановка эксперимена
Эксперимент-1 : shared_buffers = 2GB
Эксперимент-2 : shared_buffers = 4GB
Операционная скорость
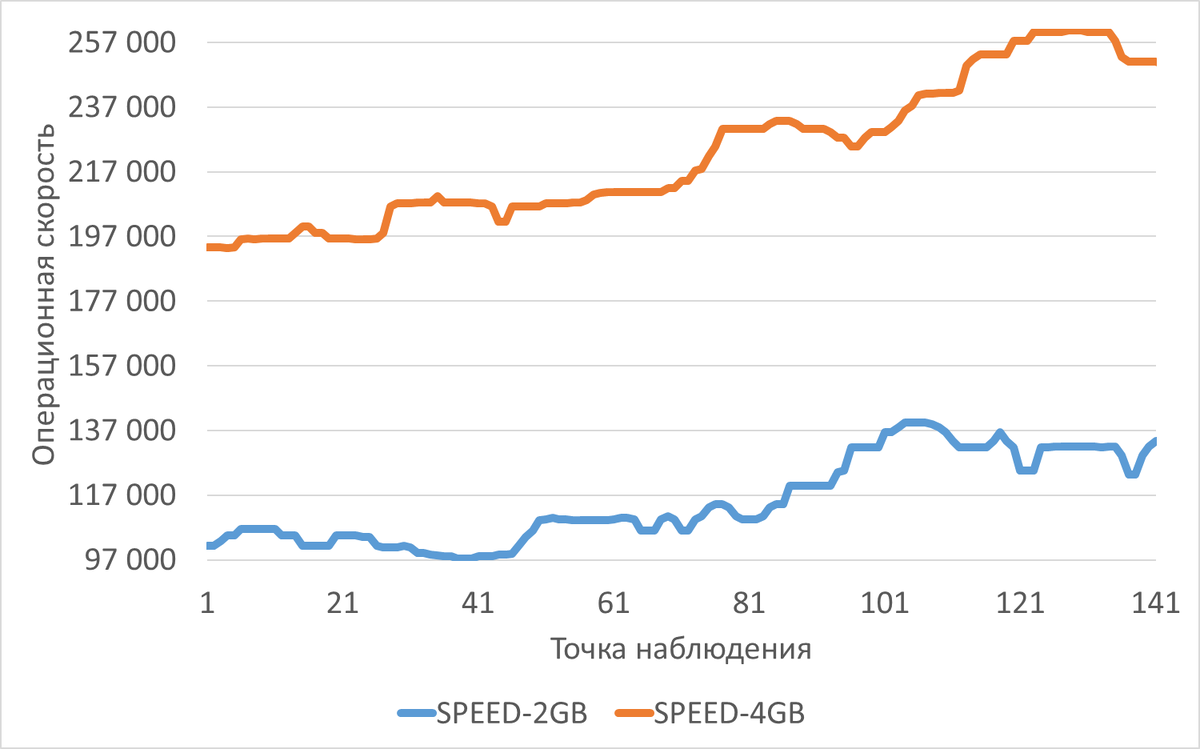
Среднее превышение операционной скорости в эксперименте-2 составило 94%
Ожидания СУБД
Среднее снижение ожиданий СУБД в эксперименте-2 составило 11%
Ожидания типа IO
Среднее снижение ожиданий типа IO в эксперименте-2 составило 11%
Ожидания типа Lock
Среднее повышение ожиданий типа Lock в эксперименте-2 составило 161%
Ожидания типа LWLock
Среднее повышение ожиданий типа LWLock в эксперименте-2 составило 285%
Сводный сравнительный отчет производительности СУБД и инфраструктуры
Общая информация
- Дата проведения: 13.03.2026
- Объект тестирования: PostgreSQL 17.5, виртуальная машина (KVM) с 8 vCPU и 7.5 ГБ RAM.
- Нагрузка: Выполнение функции select scenario1().
- Цель: Оценка влияния увеличения размера shared_buffers с 2 ГБ до 4 ГБ на производительность СУБД и состояние инфраструктуры.
Общий анализ операционной скорости и ожиданий СУБД для "Эксперимент-1" и "Эксперимент-2"
Сравнительный анализ граничных значений операционной скорости (SPEED) и ожиданий СУБД (WAITINGS)
- Скорость (SPEED):
Наблюдается значительный прирост производительности. Медианная скорость выполнения операций выросла с ~109 444 до ~214 210 (рост ~95%).
Минимальная скорость увеличилась еще сильнее (с ~97 389 до ~193 512), что говорит о более стабильной работе системы под нагрузкой в эксперименте-2. - Ожидания (WAITINGS):
Общее время ожиданий снизилось. Медиана упала с ~99 027 до ~90 944 (снижение ~8%).
Однако, максимальные ожидания остались на сопоставимом высоком уровне (~172 000 и ~163 000), что указывает на сохранение пиковых проблем с производительностью.
Сравнительный анализ трендов операционной скорости (SPEED) и ожиданий СУБД (WAITINGS)
- Скорость (SPEED):
shared_buffers=2ГБ: Модель тренда хорошая (R²=0.77), скорость растет с умеренным углом наклона (41.31).
shared_buffers=4ГБ: Модель стала очень сильной (R²=0.92), скорость растет быстрее (угол наклона 43.87). Это говорит о том, что система лучше справляется с нагрузкой во времени. - Ожидания (WAITINGS):
2ГБ: Очень сильный тренд роста ожиданий (R²=0.94, угол 44.06). Ситуация с ожиданиями быстро ухудшалась на протяжении теста.
4ГБ: Тренд роста ожиданий также очень сильный (R²=0.93), но темп роста (угол наклона) практически не изменился (44.01). Рост производительности не привел к замедлению роста очередей ожидания.
1. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД
- Основной тип ожиданий: В обоих экспериментах доминирующим типом ожиданий является IO. Взвешенная корреляция ожиданий (ВКО) для IO в обоих случаях критическая (1.0).
2ГБ: Ожидания IO практически полностью состоят из DataFileRead (97.85%).
4ГБ: Ожидания IO распределяются между DataFileRead (66.88%) и DataFileWrite (33.12%). Появление значительной доли записи — важное изменение. - Другие типы ожиданий (IPC, Lock, LWLock, Timeout):
2ГБ: Корреляция этих ожиданий с общими ожиданиями СУБД статистически значима (p < 0.05), но их абсолютный вклад (ВКО) ничтожен (<0.01). Они игнорируются в анализе.
4ГБ: Ситуация идентична. Несмотря на высокие коэффициенты корреляции (особенно для Lock — 0.98), их влияние на общую картину остается незначительным. - Интегральный приоритет: В обоих экспериментах приоритет типа ожидания для IO одинаков — 0.6271.
Итог по разделу "1. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД"
- Увеличение shared_buffers привело к значительному росту скорости, но не устранило главное узкое место — ожидания ввода-вывода.
- Характер нагрузки сместился: при 2 ГБ система в основном читала с диска, при 4 ГБ начала также активно и писать, что может быть связано с более эффективным использованием буферного кэша и сбросом "грязных" страниц.
2. СРАВНИТЕЛЬНЫЙ ТРЕНДОВЫЙ АНАЛИЗ ПРОИЗВОДИТЕЛЬНОСТИ VMSTAT
- procs -> r (очередь на CPU):
2ГБ: Хорошая модель тренда (R²=0.63) с улучшением (отрицательный наклон).
4ГБ: Модель неудовлетворительная (R²=0.12), тренд отсутствует. Очередь на CPU перестала быть фактором. - procs -> b (процессы в ожидании IO):
2ГБ: Критический негативный тренд (R²=0.89). Количество процессов, заблокированных IO, быстро росло.
4ГБ: Тренд отсутствует (R²=0.01). Ситуация стабилизировалась. Однако само значение b остается высоким (медиана 12, макс. 18 против 8 ядер CPU). - cpu -> wa (ожидание IO):
2ГБ: Удовлетворительный негативный тренд (R²=0.51). Время простоя CPU в ожидании IO росло.
4ГБ: Тренд отсутствует (R²=0.06). Значение wa стабилизировалось, но остается на экстремально высоком уровне (медиана 55%, макс. 68%). - cpu -> id (простой CPU):
2ГБ: Критический негативный тренд (R²=0.83). Простой CPU быстро падал, что коррелирует с ростом wa.
4ГБ: Тренд отсутствует (R²=0.02). Простой CPU стабилизировался, но остается низким (медиана 26%), так как CPU занят ожиданием IO.
Итог по разделу "2. СРАВНИТЕЛЬНЫЙ ТРЕНДОВЫЙ АНАЛИЗ ПРОИЗВОДИТЕЛЬНОСТИ VMSTAT"
- В эксперименте с 2 ГБ наблюдалось быстрое ухудшение всех ключевых метрик, связанных с IO (b, wa, id). Система "захлебывалась" по мере роста нагрузки.
- Увеличение shared_buffers до 4 ГБ полностью стабилизировало тренды. Падения производительности во времени больше не происходит. Однако это не решило проблему, а лишь зафиксировало ее на высоком, неприемлемом уровне (wa > 50% постоянно).
3. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД и МЕТРИК VMSTAT
- Относительные показатели vmstat
Общее для обоих экспериментов:
ALARM: Свободная RAM менее 5% (100% времени).
ALARM: wa (ожидание IO) превышает 10% (100% времени).
Различия:
2ГБ: ALARM: Процессы в b (непрерываемый сон) превышают количество ядер CPU (100% времени).
4ГБ: ALARM: Процессы в b превышают количество ядер CPU (72.5% времени). Ситуация улучшилась, но остается критической. - Корреляция IO и wa:
2ГБ: Высокая значимая корреляция (0.61). Связь есть, но модель регрессии слабая (R²=0.37).
4ГБ: Корреляция отсутствует. Ожидания СУБД (IO) перестали напрямую коррелировать с простоем CPU (wa). Это парадоксально, но может означать, что CPU простаивает не только в явных очередях СУБД, но и из-за других операций ввода-вывода (например, фоновой записи). - Индекс приоритета корреляции (CPI):
2ГБ: Максимальный приоритет у связей "операционная скорость <-> прочитанные/записанные блоки" (CPI > 0.96). Производительность полностью зависит от диска.
4ГБ: Связь скорости с записью остается высокой (CPI=0.89), но на первое место выходит корреляция переключений контекста (cs) с пользовательским временем (us) и прерываниями (in). Это указывает на возросшую роль пользовательского кода и обработки прерываний.
Итог по разделу "3. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД и МЕТРИК VMSTAT"
- Критическая нехватка оперативной памяти (free < 5%) и высокий процент времени ожидания IO (wa) являются системными проблемами, не решенными увеличением shared_buffers.
- При 2 ГБ производительность была линейно привязана к дисковым операциям. При 4 ГБ картина усложнилась: добавились накладные расходы на переключение контекста, но фундаментальная проблема с IO осталась.
Детальный анализ – граничные значения и корреляции
Ожидания СУБД
- 2ГБ: Доминирует DataFileRead (13 млн событий). Это указывает на то, что буферного кэша (2 ГБ) не хватало для обслуживания рабочего набора данных.
- 4ГБ: Общее количество событий IO снизилось (с ~13 млн до ~11.8 млн). Появились DataFileWrite (~3.9 млн). Это говорит о том, что часть данных теперь помещается в кэш, изменяется там и требует последующего сброса на диск.
Память и буферный кэш
- Shared Buffers Hit Ratio:
2ГБ: Медиана 97.1%.
4ГБ: Медиана 98.5%.
Показатель немного вырос. Для OLAP-подобной нагрузки (которая, судя по SQL, и выполняется) это приемлемые значения, но они все еще не дотягивают до целевых 99%+, характерных для OLTP. - Свободная RAM: В обоих экспериментах катастрофически низкая (медиана ~162 МБ при 2ГБ и ~128 МБ при 4ГБ), что вызывает ALARM. Система находится на грани использования swap'а (хотя сам swap не активен).
- Dirty Pages:
2ГБ: Размер "грязных" страниц в среднем составляет ~991 396 КБ (~0.99 ГБ). Это очень близко к порогу принудительной записи (dirty_ratio = 30% от 7.5 ГБ = ~2.25 ГБ).
4ГБ: Размер "грязных" страниц снизился до ~556 588 КБ (~0.55 ГБ). Это положительный эффект: более частый сброс данных на диск (появились ожидания DataFileWrite) не дает накапливаться большому объему измененных данных в памяти.
Дисковая подсистема (I/O)
- bi (чтение с диска):
2ГБ: Медиана ~49 304 блоков.
4ГБ: Медиана ~46 880 блоков. Чтение немного снизилось, что согласуется с ростом hit ratio. - bo (запись на диск):
2ГБ: Медиана ~24 254 блоков.
4ГБ: Медиана ~24 805 блоков. Запись немного выросла, что коррелирует с появлением DataFileWrite. - Анализ:
2ГБ: Очень высокая корреляция скорости с bi (0.98) и bo (0.97). Это классический признак того, что база данных упирается в производительность дисковой подсистемы.
4ГБ: Корреляция с bi снизилась до 0.79, с bo до 0.89. Производительность стала чуть меньше зависеть от пиковых значений IO, но зависимость остается очень сильной.
CPU и системные вызовы
- cs (переключения контекста) и in (прерывания):
2ГБ: Очень высокая корреляция (0.98) и сильная модель (R²=0.95). Высокая активность диска порождает много прерываний, что ведет к переключениям контекста.
4ГБ: Корреляция остается высокой (0.86), модель хорошая (R²=0.73). Связь сохраняется, но стала слабее. - cs (переключения контекста) и us (user time):
2ГБ: Очень высокая корреляция (0.94) и сильная модель (R²=0.89).
4ГБ: Очень высокая корреляция (0.88) и хорошая модель (R²=0.78).
Это указывает на то, что само пользовательское приложение (функция scenario1) генерирует большое количество переключений контекста, возможно, из-за большого числа мелких операций или неэффективных вызовов.
Ожидания IO
- В обоих экспериментах это главная проблема.
- 2ГБ: Ожидания связаны преимущественно с чтением. Система не успевает читать данные с диска.
- 4ГБ: Ожидания связаны как с чтением, так и с записью. Система упирается в возможности диска как на чтение, так и на запись.
Ожидания Lock
- Корреляция с общими ожиданиями высокая, но абсолютное значение ожиданий мизерное (медиана ~53 при 2ГБ и ~128 при 4ГБ). Проблем с блокировками на уровне БД не зафиксировано.
Ожидания LWLock
- Аналогично Lock. Вклад в общую картину пренебрежимо мал. Увеличение shared_buffers не создало проблем с внутренними блокировками PostgreSQL.
Ключевые проблемы для "Эксперимент-1 (shared_buffers=2GB)" и "Эксперимент-2 (shared_buffers=4GB)"
Проблемы СУБД
- (Общая) Диск — главное узкое место: В обоих экспериментах основное время тратится на ожидание IO. Система упирается в производительность дисковой подсистемы.
- (Эксперимент-1) Нехватка буферного кэша: Высокая доля чтений с диска (DataFileRead) и сильнейшая корреляция скорости с чтениями указывают на то, что рабочий набор данных значительно превышает выделенные 2 ГБ shared_buffers.
- (Эксперимент-2) Смещение узкого места: Увеличение кэша позволило разместить в нем больше данных, что сместило проблему с чистого чтения на смесь чтения и записи. Появились ожидания DataFileWrite, что говорит о затратах на синхронизацию буферного кэша с диском.
- (Эксперимент-1) Деградация во времени: Наблюдался сильный тренд ухудшения всех показателей (рост b, wa, падение id). Система не справлялась с растущей нагрузкой.
Проблемы инфраструктуры
- (Общая) Катастрофическая нехватка оперативной памяти: Уровень свободной памяти менее 5% на протяжении 100% времени в обоих тестах — это критический сигнал. Это заставляет систему излишне агрессивно управлять кэшами и может приводить к неожиданным просадкам производительности.
- (Общая) Экстремально высокая нагрузка на диск: Процессы постоянно находятся в состоянии ожидания IO (b выше числа ядер CPU), а процессоры простаивают в ожидании IO более 50-70% времени. Это говорит о том, что дисковая система (предположительно, один общий LVM том на vdd) не способна обеспечить требуемую скорость чтения/записи.
- (Эксперимент-1) Быстрая деградация дисковой системы: Количество процессов, заблокированных IO, быстро росло на протяжении теста, указывая на то, что диск "захлебывался" все сильнее по мере увеличения глубины очереди запросов.
Послесловие
Проведенное исследование подтвердило нелинейный характер влияния буферного кэша на производительность: увеличение shared_buffers до 4 ГБ обеспечило значительный прирост медианной скорости выполнения операций (до 95%) и стабилизировало тренды деградации ключевых метрик ввода-вывода. Однако главное узкое место — высокая зависимость от производительности дисковой подсистемы — не было устранено. Выявлено смещение характера ожиданий в сторону операций записи (DataFileWrite) и сохранение критического уровня времени ожидания ввода-вывода (wa > 50%), что наряду с катастрофическим дефицитом оперативной памяти указывает на необходимость масштабирования инфраструктурных ресурсов, а не только дальнейшей оптимизации параметров СУБД.