🎧 Fish Audio S2 Pro - мощная open-source модель для синтеза речи.
Это 4B + 400M параметровая TTS-модель с необычной архитектурой Dual-AR, обученная на 10+ миллионах часов аудио и поддерживающая 80+ языков.
Что делает её интересной.
🏗 Dual-AR архитектура
Модель разделена на две части:
• 4B Slow AR отвечает за семантику и структуру речи
• 400M Fast AR генерирует 9 residual codebooks для акустики
Такой подход позволяет сохранить высокое качество звука без сильной нагрузки на инференс.
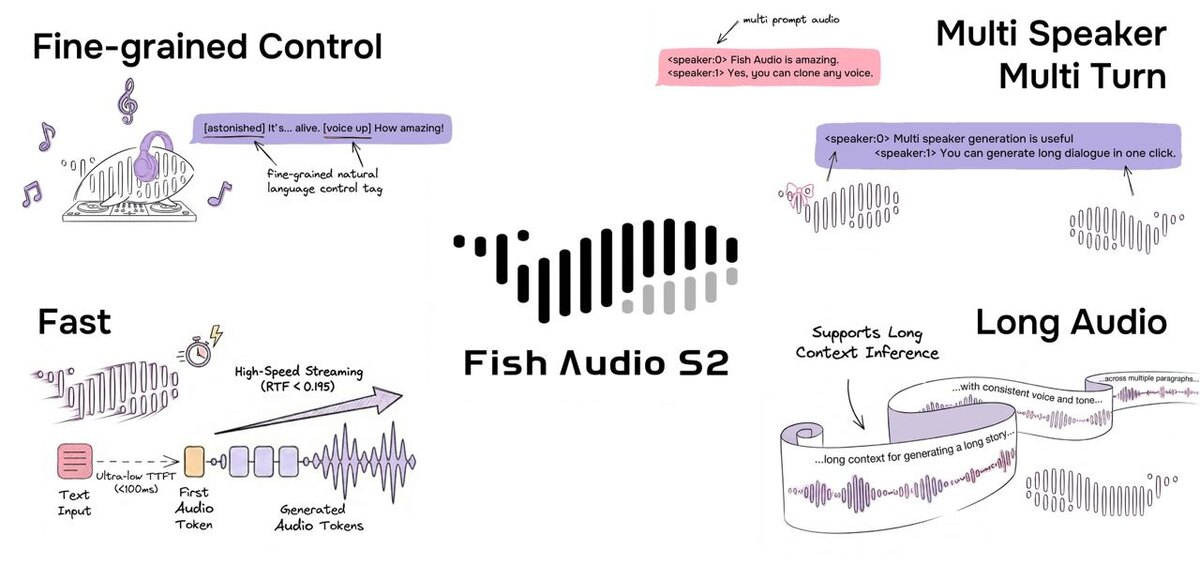
🎭 Свободное управление эмоциями и интонацией
Можно прямо в тексте задавать стиль речи:
[whisper]
[laughing]
[professional broadcast tone]
Поддерживается 15 000+ тегов, которые работают на уровне отдельных слов.
🌐 80+ языков
Основные языки высокого качества:
• английский
• китайский
• японский
⚡ Оптимизация для LLM-инфраструктуры
Модель нативно работает со стеком SGLang, поэтому поддерживает:
• continuous batching
• paged KV cache
• RadixAttention prefix caching
📊 Производительность
• RTF: 0.195 на Nvidia H200
• ~100 мс до первого аудио
• более 3000 акустических токенов/сек
Также разработчики выложили:
• веса модели
• код для fine-tuning
• движок для streaming inference
Модель: https://modelscope.ai/models/fishaudio/s2-pro
GitHub: https://github.com/fishaudio/fish-speech
#ai #tts #opensourсe