
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
GitFlic - pg_expecto - статистический анализ производительности и ожиданий СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен
Введение
Представлены результаты углублённого анализа инцидента производительности в высоконагруженной продуктивной среде PostgreSQL, в ходе которого зафиксирован переход от относительной стабильности к комплексной деградации вычислительных ресурсов, подсистемы ввода-вывода и механизмов синхронизации ядра СУБД. Применение pg_expecto с акцентом на использование как инструмента комплексного статистического анализа производительности СУБД и инфраструктуры позволило не ограничиться констатацией снижения операционной скорости, а выявить критическую конкуренцию за буферный кэш (LWLock: BufferMapping), изменения паттернов работы расширений СУБД и скрытые проблемы дисковой подсистемы.
ℹ️Инцидент производительности СУБД
Подробнее о индикаторе инцидента производительности СУБД
Дашборд Zabbix
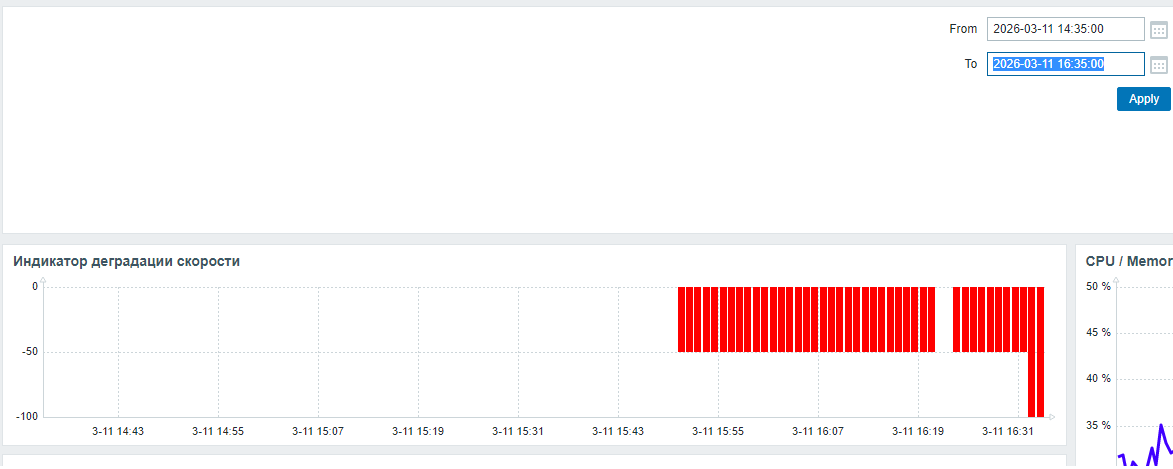
Дата и время инцидента: 11/03/2026 16:35
Производительность и ожидания СУБД в период 14:35 - 16:35
Операционная скорость
Рис.1 - График изменения операционной скорости в отрезке [время инцидента; время инцидента - 2 часа]. Рост производительности сменился снижением.
Ожидания СУБД
Рис.2 - График изменения ожиданий СУБД в отрезке [время инцидента; время инцидента - 2 часа]. Рост ожиданий СУБД в течении часа до иницидента.
Производительность и ожидания СУБД в период инцидента производительности СУБД
Операционная скорость
Рис.3 - Снижение операционной скорости в ходе инцидента. Коэффициент детерминации = 0.9
Ожидания СУБД
Рис.4 - Рост ожиданий СУБД в ходе инцидента. Коэффициент детерминации = 0.6
1. Сводный сравнительный отчет по производительности СУБД и инфраструктуры 2026-03-11 14:35 - 16:35
Общая информация
Объект анализа: СУБД PostgreSQL 15.13 (конфигурация из файла _1.settings.txt) и инфраструктура (vmstat).
Периоды сравнения:
- Инцидент: 2026-03-11 15:35 — 16:35 (файл _2.postgresql_vmstat.txt). Период, квалифицированный как инцидент производительности.
- Тест: 2026-03-11 14:35 — 15:35 (файл _2.1.test.postgresql_vmstat.txt). Период, взятый как тестовый отрезок для сравнения.
Аппаратная конфигурация:
- CPU: 192 ядра (Intel Xeon Platinum 8280L), 4 NUMA-узла.
- RAM: ~1008 GB.
- Дисковая подсистема: Тома LVM на отдельных дисках для данных (/data, 56T), WAL (/wal, 1T), резервных копий (/backup, 2.9T) и логов (/log, 100G).
Итог по разделу "1. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД"
- Ключевое изменение: Основная нагрузка сместилась с Extension в тестовом периоде на LWLock в инциденте. Хотя Extension все еще имеют высокий приоритет, их вклад в общее время ожиданий снизился, в то время как вклад LWLocks остался критически высоким.
- В инциденте также появились и стали значимыми ожидания типов IO и Lock, которые в тестовом периоде не оказывали влияния. Это говорит о том, что система вошла в фазу комплексной деградации, затронувшей диск и блокировки транзакций.
Итог по разделу "2. СРАВНИТЕЛЬНЫЙ ТРЕНДОВЫЙ АНАЛИЗ ПРОИЗВОДИТЕЛЬНОСТИ vmstat"
- Главный сигнал инцидента: Резкое падение cpu_id (простоя CPU) при одновременном падении скорости БД. CPU начинает активно работать, но не на выполнении полезной нагрузки, а на обслуживании простоев (скорее всего, связанных с LWLocks и конкуренцией).
- В тестовом периоде CPU простаивал больше, очереди на выполнение (r) сокращались — система была сбалансирована.
- Проблемы с диском (b, wa), наблюдавшиеся в тесте, в инциденте пошли на спад, что подтверждает смещение фокуса проблемы с IO на CPU и блокировки.
Итог по разделу "3. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД и МЕТРИК vmstat"
- Основное различие в поведении Extension. В инциденте они стали значительно сильнее коррелировать с прерываниями (in), что может указывать на изменение их паттерна работы (например, увеличение частоты вызовов внешних API или обмен по сети).
- Модель зависимости блокировок (Lock) от очереди на CPU (r) в инциденте стала слабой, хотя связь осталась. Это значит, что в формирование очереди на CPU теперь вносят вклад и другие факторы, прежде всего LWLocks, которые не отслеживаются напрямую vmstat.
Итог по разделу "4. СРАВНЕНИЕ ДИАГРАММ ПАРЕТО ПО WAIT_EVENT_TYPE и QUERYID"
Усложнение структуры отказов: В инциденте к проблемам с Extension и transactionid (блокировки строк) добавились серьезные проблемы с:
- Конкуренцией за буферный кэш (LWLock: BufferMapping).
- Физическими чтениями данных (IO: DataFileRead).
- Синхронной записью WAL (IO: WALSync).
- Блокировками версий строк (Lock: tuple).
Концентрация нагрузки: Основные проблемные запросы — прежние, но теперь они создают более сложный и разнообразный профиль ожиданий. Появление новых запросов в топе по IO и Lock говорит о том, что либо начали выполняться новые, тяжелые операции, либо изменился план выполнения старых запросов.
Проблемы СУБД
1. Критическая конкуренция за буферный кэш (LWLock: BufferMapping): Является основной причиной падения скорости в инциденте. Процессы проводят время в очередях за доступом к страницам в shared_buffers.
2. Деградация работы расширений (Extension): Расширения стали работать иначе, вызывая всплески прерываний и нагружая CPU, что усугубляет общую ситуацию. Главные виновники — запросы -503898190... и -428029360....
3. Рост физических чтений с диска (IO: DataFileRead): Буферный кэш перестал эффективно кэшировать данные, что привело к падению производительности и росту IO-ожиданий.
4. Появление синхронных проблем с WAL (IO: WALSync): Указывает на то, что запись в WAL начала тормозить транзакции, вероятно, из-за исчерпания пропускной способности диска с WAL или из-за конкурентной записи.
5. Расширение спектра блокировок (Lock: tuple): К проблемам с блокировками транзакций (transactionid) добавились блокировки отдельных версий строк (tuple), что говорит о высоком конкурентном доступе к одному и тому же набору данных.
Проблемы инфраструктуры
1. Неэффективная утилизация CPU: Процессорное время уходит не на полезную работу, а на оверхед (прерывания, ожидания). Это подтверждается падением cpu_id при падении скорости БД.
2. Рост прерываний: Увеличение корреляции Extension с in (прерывания) указывает на возросшую нагрузку на ядро ОС.
3. Косвенные признаки дисковой проблемы: Хотя прямые метрики wa и b улучшились, появление IO: DataFileRead и WALSync в топе ожиданий СУБД говорит о том, что дисковая система перестала справляться с пиковыми нагрузками, даже если это не видно на уровне усредненных метрик vmstat.
4. Острый дефицит свободной памяти: В обоих периодах свободной RAM менее 5% (ALARM). Система постоянно работает на грани нехватки оперативной памяти, что увеличивает вероятность вытеснения страниц и усиливает конкуренцию за буферный кэш. Это фоновый хронический фактор, который, вероятно, и спровоцировал инцидент при изменении паттерна нагрузки.
Полный отчет:
2. Сводный сравнительный отчет по подсистеме IO 2026-03-11 14:35 - 16:35.
Список дисковых устройств
Анализ проводился для следующих дисковых устройств, входящих в состав LVM для хранения данных СУБД и WAL:
- vdg — физический диск, используемый для WAL (/wal) и раздела подкачки.
- vdh, vdi, vdj, vdk — физические диски, объединенные в LVM-том /data для хранения данных СУБД.
Сравнительный анализ граничных значений по дисковым устройствам
В данном разделе сравниваются минимальные, медианные и максимальные значения ключевых метрик за тестовый период и период инцидента.
Устройство vdg (WAL):
- Тест: Нагрузка на запись (w/s, wMB/s) стабильно низкая. Операции чтения практически отсутствуют. Утилизация устройства (device_util) минимальна (медиана ~5.9%).
- Инцидент: Резкий рост нагрузки на запись. Медиана w/s выросла с ~373 до ~689, а wMB/s — с ~7.75 до ~16.0. Несмотря на рост, утилизация устройства остается низкой (медиана ~10.2%), что говорит о его высокой производительности и малом влиянии на общую картину.
Устройства данных vdh, vdi, vdj, vdk:
Тест: На всех четырех дисках наблюдается высокая и стабильная смешанная нагрузка. Медианные значения составляют:
- r/s: ~12 200
- w/s: ~500
- Утилизация (device_util): ~87%
- Глубина очереди (aqu-sz): ~2.0
Инцидент: Нагрузка на диски данных значительно возрастает.
- r/s: медиана увеличивается до ~13 500.
- w/s: медиана удваивается, достигая ~1 100.
- wMB/s: медиана возрастает с ~4.8 до ~10.5.
- Утилизация остается на критическом уровне (медиана ~90%).
- Глубина очереди незначительно растет (медиана ~2.5).
Вывод: В период инцидента произошло существенное увеличение нагрузки на диски данных (vdh-vdk), особенно на операции записи (рост в 2 раза). Диск WAL (vdg) также испытал рост нагрузки на запись, но остался далек от насыщения.
Итог по разделу "СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ КОРРЕЛЯЦИЯ VMSTAT и IOSTAT по дисковым устройствам"
В тестовом периоде наблюдалась высокая нагрузка на диски данных, но механизмы кэширования и буферизации работали иначе. В период инцидента характер взаимосвязей изменился: главным фактором стало прямое влияние загрузки диска на ожидание процессов (wa). Ключевым ограничивающим фактором стала пропускная способность дисков, о чем свидетельствует появление сильных корреляций с метриками MBps.
Проблемы инфраструктуры по итогам сравнительного анализа
1. Хроническая перегрузка дисков данных: Диски vdh, vdi, vdj, vdk постоянно работают с утилизацией более 80-90% и глубиной очереди более 2, что является критическим состоянием.
2. Усугубление проблемы в период инцидента: На фоне и без того высокой нагрузки произошел скачок операций записи (в 2 раза), что превратило пропускную способность дисков в главное узкое место.
3. Неэффективность буферизации: В момент пика нагрузки корреляция буферов с дисковым вводом-выводом пропала, что говорит о возможной нехватке буферов или неоптимальном характере нагрузки для их использования.
4. Рост зависимости от кэша: Увеличение корреляции кэша с дисковыми операциями в период инцидента указывает на то, что система пытается компенсировать недостаток дисковой производительности за счет памяти, но это не решает проблему полностью.
5. Отсутствие запаса пропускной способности: Система данных СУБД уперлась в физический предел скорости чтения/записи дисков.
Полный отчет:
Рекомендации по оптимизации производительности
Критически высокое значение work_mem = 1GB
- Текущее значение является чрезмерно высоким. При большом количестве параллельных сессий это может приводить к исчерпанию оперативной памяти (RAM), увеличению конкуренции за буферный кеш и, как следствие, к сбросу данных на диск.
- Действие: Снизить work_mem до безопасного диапазона 128–512 МБ (рекомендуется начать с 256 МБ) и контролировать появление временных файлов (temp_files).
Проблемы с расширениями (Extension)
- Расширения (особенно pgpro_stats и pgpro_scheduler) являются основным источником проблем в период инцидента. Наблюдается сильнейшая корреляция с ростом времени пользователя (user time) и прерываниями. Ожидания типа Extension стали вторым по значимости фактором после LWLock.
- Действие: Провести детальный анализ запросов с идентификаторами: -5038981907002478858, -4280293605113329019, -1757223094415174739. Снизить частоту сбора статистики для pgpro_stats (уменьшить pgpro_stats.max). Проверить логику работы pgpro_scheduler.
Конкуренция за легковесные блокировки (LWLock)
- LWLock остается критическим фактором, тормозящим систему. Основные точки конкуренции: BufferMapping (борьба за буферный кеш), WALWrite (запись WAL), pgpro_stats (накладные расходы статистики) и LockManager.
- Действие:
- BufferMapping: Рассмотреть возможность увеличения числа буферных партиций или секционирования крупных таблиц для снижения конкуренции.
- WALWrite: Увеличить wal_buffers до 64–128 МБ и max_wal_size до 16–32 ГБ для сглаживания пиковых нагрузок и уменьшения частоты контрольных точек.
Критический дефицит свободной оперативной памяти (RAM)
- Свободная RAM составляет менее 5%. Хотя большой объем памяти занят под кеш ОС (buff/cache), такое состояние критично и повышает риск срабатывания OOM-Killer или вытеснения полезных страниц кеша.
- Действие: Проверить настройки huge pages (huge_pages=on), убедиться, что они корректно выделены в ОС. Проверить параметр ядра vm.min_free_kbytes и установить его в значение 2-5% от всей RAM (20-50 ГБ). Рассмотреть возможность увеличения физической памяти или перераспределения ее между СУБД и ОС.
Агрессивные настройки Autovacuum
- Параметры autovacuum_naptime = 1s, autovacuum_vacuum_scale_factor = 0.001 и autovacuum_analyze_scale_factor = 0.005 являются чрезмерно агрессивными. Они заставляют процесс автовакуума запускаться слишком часто, создавая дополнительную и, зачастую, ненужную нагрузку на систему.
- Действие: Увеличить autovacuum_naptime до 10–30 секунд. Увеличить масштабные коэффициенты до значений по умолчанию (autovacuum_vacuum_scale_factor = 0.01, autovacuum_analyze_scale_factor = 0.05) или выше.
Отключенные параллельные запросы
- Параметр max_parallel_workers_per_gather = 0 полностью отключает параллельное выполнение запросов на сервере с 192 ядрами. Это приводит к недоиспользованию вычислительных мощностей CPU и может увеличивать время выполнения тяжелых запросов.
- Действие: Включить параллельные запросы, установив max_parallel_workers_per_gather = 4 и контролируя нагрузку на систему.
Неоптимальные параметры WAL и контрольных точек
- max_wal_size = 8GB маловат для сервера с 1 ТБ RAM и высокой интенсивностью записи. Это может вызывать частые и резкие контрольные точки. wal_keep_size = 500GB чрезмерно велик и занимает лишнее дисковое пространство.
- Действие: Увеличить max_wal_size до 16-32 ГБ. Уменьшить wal_keep_size до 50-100 ГБ, если нет особых требований к репликации.
Блокировки транзакций (Lock)
- Ожидания transactionid и tuple указывают на конфликты при работе с одними и теми же строками или наличие длительных транзакций. Это связано с теми же проблемными запросами.
- Действие: Сократить время удержания блокировок (делать COMMIT раньше), проверить уровень изоляции транзакций (использовать READ COMMITTED), внедрить retry-логику на стороне приложения.
Проверка конфигурации Huge Pages
- Параметр huge_pages = on установлен, но нет гарантии, что ОС выделила необходимое количество huge pages. Несоответствие может привести к тому, что PostgreSQL будет использовать обычные страницы памяти, что увеличит нагрузку на управление памятью и снизит производительность.
- Действие: Проверить выделение huge pages в ОС (grep Huge /proc/meminfo) и, при необходимости, увеличить vm.nr_hugepages.
Возможные случайные ошибки
Рекомендации, которые противоречат общему мнению большинства. Скорее всего, это единичные ошибки модели.
Рекомендация: Увеличить work_mem с 1GB до 2–4GB (из test_performance10.txt).
- Причина ошибки: Модель, вероятно, интерпретировала высокую нагрузку на CPU от расширений как необходимость ускорить сортировки и хеш-соединения за счет увеличения памяти, не учтя контекст: катастрофический дефицит свободной RAM и высокую конкуренцию за буферный кеш. Это прямо противоположно консенсусу о необходимости снижения work_mem.
Рекомендация: Уменьшить shared_buffers со 246 ГБ до 150–200 ГБ (из test_performance7.txt и test_performance9.txt).
- Причина ошибки: Эта рекомендация основана на предположении, что освобождение памяти для кеша ОС может быть эффективнее. В условиях, когда основной проблемой является конкуренция за буферный кеш (LWLock: BufferMapping), уменьшение shared_buffers может усугубить проблему, заставив систему еще чаще обращаться к диску. Большинство отчетов либо оставляют значение без изменений, либо предлагают его немного увеличить. Это классический случай, где баланс между кешем БД и ОС неочевиден и требует более глубокого анализа hit ratio.
Рекомендация: Увеличить shared_buffers до 300-320 ГБ (из test_performance1.txt и test_performance6.txt).
- Причина ошибки: В данном случае модель могла переоценить пользу от увеличения буферного кеша для снижения BufferMapping, не принимая во внимание, что на NUMA-системах чрезмерно большой shared_buffers может сам стать источником проблем с производительностью из-за сложностей управления памятью между узлами. Консенсус говорит о том, что текущее значение и так велико, и проблема не в его размере, а в том, как он используется.
Примечание
Рекомендации получены с использованием метода "голосование" для снижения последствий недетерминированности ответов нейросети
Общий итог
Проведенный сравнительный анализ производительности СУБД PostgreSQL в периоды штатной работы и развития инцидента выявил комплексный характер деградации системы, непосредственной причиной которой стала критическая конкуренция за буферный кэш (LWLock: BufferMapping) на фоне измененных паттернов работы расширений, роста физических чтений и синхронных ожиданий записи WAL при хроническом дефиците оперативной памяти и перегрузке дискового массива (утилизация более 90%). Применение инструментария pg_expecto в данном исследовании продемонстрировало его эффективность для анализа высоконагруженных продуктивных систем: возможность сравнительного статистического анализа, трендового моделирования и корреляции метрик СУБД с показателями операционной среды позволила перейти от констатации факта падения скорости к выявлению первопричин деградации и сформировать научно обоснованные, верифицированные рекомендации по оптимизации, что подтверждает ценность данного инструмента для глубокой диагностики и постмортем-анализа промышленных инсталляций PostgreSQL.