
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
GitFlic - pg_expecto - статистический анализ производительности и ожиданий СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен
Первоначальный вариант статьи:
Введение
Процесс начальной конфигурации сервера PostgreSQL, как правило, опирается на использование автоматизированных генераторов параметров (конфигураторов). Такие инструменты, включая широко применяемый конфигуратор компании «Тантор Лабс», предлагают готовый набор настроек на основе ограниченных входных данных — объёма оперативной памяти, количества ядер CPU и предполагаемого типа нагрузки. Однако на практике сгенерированная таким образом конфигурация не учитывает специфику реального рабочего профиля и особенности взаимодействия СУБД с аппаратным обеспечением, что может приводить к критическому снижению производительности, росту I/O wait и неэффективному использованию ресурсов.
Возникает закономерный вопрос: возможно ли выявить и устранить эти «узкие места» без модернизации оборудования, опираясь лишь на углублённый анализ статистических данных?
Настоящая работа представляет собой практический кейс оптимизации PostgreSQL 17 на сервере с ограниченными ресурсами (8 ядер CPU, 8 ГБ RAM). В качестве отправной точки используется конфигурация, сгенерированная конфигуратором «Тантор Лабс». Для диагностики и последующей настройки применяется комплексный подход, основанный на двух инструментах:
- pg_expecto — Open source комплекс для сбора и статистического анализа метрик производительности СУБД и операционной системы .
- Нейросеть DeepSeek — для автоматизированного анализа собранных данных, выявления неочевидных закономерностей и формирования рекомендаций по изменению параметров PostgreSQL и ядра ОС.
Цель эксперимента — не просто продемонстрировать прирост скорости на 40%, но и верифицировать гипотезу о том, что синергия статистического анализа и методов машинного обучения позволяет существенно повысить эффективность типовой конфигурации, приближая её к оптимальной для заданного профиля нагрузки. В статье подробно разбираются исходные и итоговые параметры, приводится сравнительный анализ метрик, а также фиксируются ограничения, которые не удалось преодолеть исключительно настройкой (дефицит оперативной памяти и неоптимизированный запрос). Полученные результаты формируют основу для дальнейших исследований, направленных на сравнение различных стратегий начальной генерации конфигураций PostgreSQL.
1.Условия эксперимента
Инфраструктура и СУБД
- CPU = 8
- RAM = 8GB
- Тип нагрузки = OLTP
- Платформа = Linux
- Версия PostgreSQL = 17
Методика нагрузочного тестирования
Для создания контролируемой синтетической нагрузки и сбора первичных метрик использовался открытый инструмент pg_expecto.
Параметры тестирования задавались следующим образом:
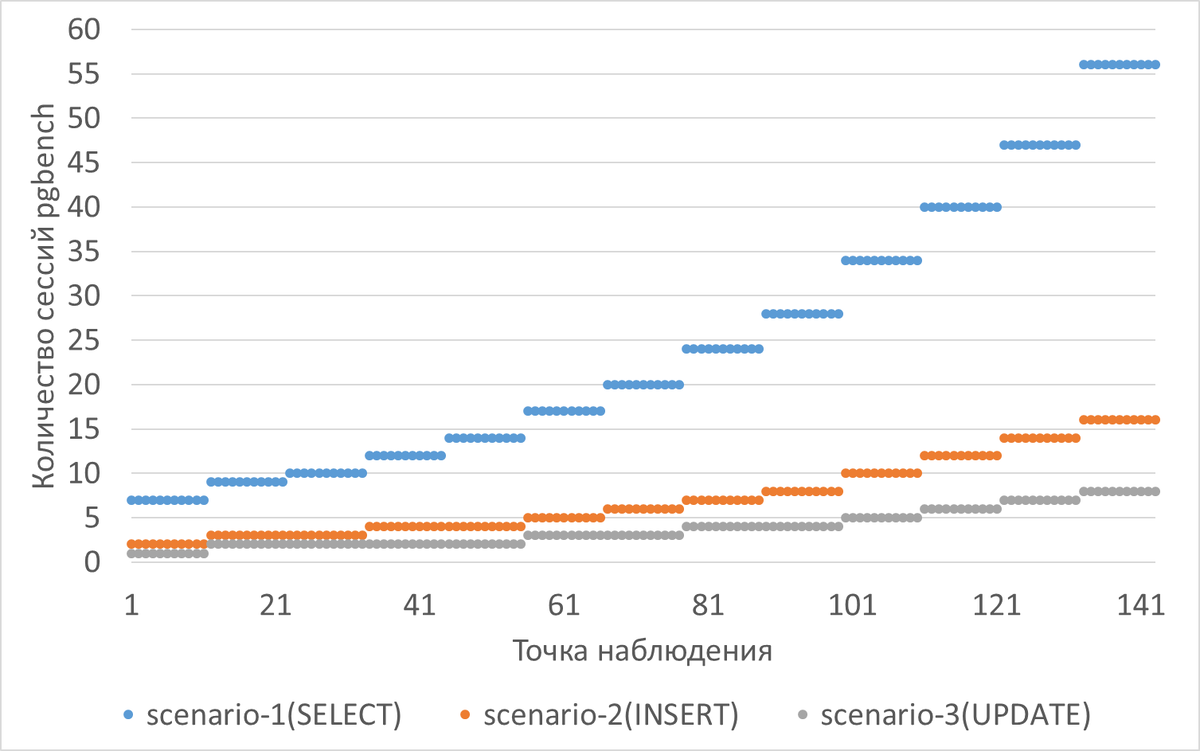
- Режим нагрузки: OLTP (сценарии с весами 0.7 / 0.2 / 0.1).
- Диапазон нагрузки: от 10 до 80 одновременных сессий.
- Объём тестовых данных: ~10 ГБ (scale = 685).
Нагрузка по сценариям в ходе тестирования
2. Формирование baseline: конфигурация «Тантор Лабс»
В качестве отправной точки (baseline) для эксперимента была выбрана конфигурация, сгенерированная онлайн-конфигуратором критически важных параметров PostgreSQL от компании «Тантор Лабс». Данный инструмент широко известен в профессиональном сообществе и предлагает быстрый способ получения стартового набора настроек на основе минимальных входных данных.
Результирующая конфигурация (фрагмент):
- shared_buffers = 1779MB
- max_wal_size = 2021MB
- checkpoint_timeout = 15min
- bgwriter_delay = 54ms
- bgwriter_lru_maxpages = 515
- bgwriter_lru_multiplier = 7.0
- track_io_timing = on
- logging_collector = on
Полный листинг конфигурации
Основная задача первого этапа заключалась не в достижении идеальной производительности, а в объективной фиксации поведения системы при «рекомендованной» конфигурации. Полученные данные формируют baseline — точку отсчёта, относительно которой будет оцениваться эффект от последующих оптимизаций.
Результаты первого этапа
Медианное значение скорости составило 383 994 , что само по себе является лишь констатацией факта, но не оценочной характеристикой.
Рисунок 1. Операционная скорость PostgreSQL 17 с конфигурацией «Тантор Лабс» (baseline). Наблюдается высокая вариативность, медианное значение ~384 000
Почему это важно?
Сформированный baseline позволяет перейти от субъективных ощущений («работает быстро» или «тормозит») к количественным показателям. Именно эти данные — метрики pg_expecto— послужили входной информацией для последующего анализа с участием нейросети DeepSeek. Конфигуратор выполнил свою функцию: предоставил стартовую точку. Вопрос в том, насколько далеко можно уйти от этой точки с помощью тонкой настройки, основанной на данных, а не на общих рекомендациях
3. Инструментарий: синергия pg_expecto и DeepSeek
Для проведения эксперимента требовался инструмент, который не просто собирает метрики, а позволяет установить причинно-следственные связи между состоянием операционной системы, внутренними событиями PostgreSQL и итоговой производительностью. Эту задачу решил комплекс pg_expecto(версия 7) .
3.1. pg_expecto: мост между СУБД и «железом»
В отличие от традиционных мониторинговых решений, pg_expecto сознательно фокусируется на статистических методах анализа и обеспечивает полную прозрачность процесса . Ключевые возможности, использованные в эксперименте:
- Сбор метрик операционной системы: Инструмент интегрируется с утилитами vmstat и iostat, что позволяет напрямую коррелировать нагрузку на диск, память и процессор с поведением базы данных . Это критически важно, так как многие проблемы производительности коренятся именно на уровне ОС.
- Детальный анализ ожиданий СУБД: pg_expectoвыполняет глубокий разбор событий ожидания (wait_event_type/wait_event), помогая установить, что именно тормозит запросы — чтение с диска (DataFileRead), блокировки (LWLock) или что-то иное .
- Встроенное нагрузочное тестирование: Комплекс позволяет проводить тесты по гибким сценариям (в нашем случае — OLTP-нагрузка с тремя типами операций) и автоматически собирать статистику .
- Корреляционный анализ: pg_expectoрассчитывает зависимости между метриками (например, между ожиданиями ввода-вывода и состоянием процессов b в vmstat), что автоматически подсвечивает «узкие места» .
3.2. DeepSeek: аналитик, работающий с данными, а не с графиками
Сырые данные, собранные pg_expecto, были переданы нейросети DeepSeek для семантического анализа. Однако ключевой момент — формат передачи. Вместо того чтобы загружать графики или общее описание проблемы, мы использовали структурированные текстовые файлы, подготовленные pg_expecto. Этот подход многократно описан в сообществе как наиболее эффективный для интеграции с ИИ .
Формирование отчета по итогам нагрузочного тестирования
cd /postgres/pg_expecto/sh/performance_reports
./load_test_report.sh
Что получил DeepSeek на вход?
- _1.settings.txt — полный дамп настроек PostgreSQL и параметров ядра ОС (sysctl).
- _2.postgresql_vmstat.txt — результат комплексного корреляционного анализа метрик СУБД и vmstat за период теста.
3.3. «Золото» эксперимента: промпты для DeepSeek
Ниже приведены точные формулировки промптов, которые использовались для анализа. Именно детализация запроса позволила получить конкретные, а не общие рекомендации.
Промпт №1 (для анализа базовой конфигурации) — файл _3.1.prompt.txt
Промпт №2 (сравнительный анализ "До/После") — файл _3.3.prompt.diff.txt
3.4. Почему эта связка работает
Собранные pg_expecto данные представляют собой не просто сырые логи, а уже предварительно обработанный статистический материал с рассчитанными трендами и корреляциями . DeepSeek, получив такую структурированную информацию, выступает в роли эксперта, который способен:
- Сопоставить значения shared_buffers с давлением на диск (метрики bo из vmstat).
- Увидеть, что высокий bgwriter_lru_multiplier приводит к излишним сбросам и росту ожиданий LWLock.
- Сформулировать выводы на естественном языке, понятном инженеру.
В результате мы получаем не абстрактный совет «увеличить буферы», а точное предписание, валидированное на реальных данных нагрузочного тестирования. Именно этот подход позволил добиться прироста в +40%, сохранив при этом честность анализа и указав на оставшиеся ограничения.
4. Диагноз от ИИ и новая конфигурация
На основе анализа, выполненного DeepSeek (промпт №1), был сформирован следующий перечень рекомендаций, разделённый на параметры PostgreSQL и настройки ядра ОС.
Рекомендации по настройкам СУБД
- Увеличить shared_buffers (до 2–2.5 GB, учитывая 7.5 GB RAM), чтобы больше данных помещалось в кэш.
- Увеличить max_wal_size (например, до 4–5 GB), чтобы сгладить пики записи.
- Увеличить checkpoint_timeout (до 20–30 мин) .
- bgwriter_delay – увеличить с 54 мс до 100 мс.
- bgwriter_lru_maxpages – увеличить с 515 до 1000.
- bgwriter_lru_multiplier – рекомендуется снизить с 7.0 до 4.0–5.0.
Рекомендации по настройкам операционной системы
- Уменьшить vm.dirty_background_ratio до 2–3% (сейчас 10%).
- Уменьшить vm.dirty_ratio до 10–15% (сейчас 30%).
- Уменьшить vm.dirty_writeback_centisecs до 200–300 (сейчас 500) для более частого пробуждения flusher-нитей.
Полный отчет, подготовленный нейросетью:
Применение настроек СУБД и ОС, рекомендованных DeepSeek
Общая информация
Эксперимент‑1 (базовый) – настройки, сгенерированные «Тантор Лабс» (pgconfigurator).
Период наблюдения: 2026‑03‑05 18:09 – 20:31 (2 ч 22 мин, 143 точки).
Эксперимент‑2 (оптимизированный) – настройки, рекомендованные PG_EXPECTO + DeepSeek.
Период наблюдения: 2026‑03‑06 10:48 – 13:10 (2 ч 22 мин, 143 точки).
Аппаратная платформа (одинакова для обоих экспериментов):
- CPU: 8 ядер (Intel Xeon Skylake, виртуализация KVM)
- RAM: 7,5 GB
- Диски: LVM, отдельные тома для /data (pg_data), /wal, /log
Сравнение конфигурации СУБД и операционной системы
Изменённые параметры PostgreSQL
shared_buffers
- Эксперимент‑1: 1779 MB
- Эксперимент‑2: 3 GB
max_wal_size
- Эксперимент‑1: 2021 MB
- Эксперимент‑2: 5 GB
checkpoint_timeout
- Эксперимент‑1: 15 min
- Эксперимент‑2: 30 min
bgwriter_delay
- Эксперимент‑1: 54 ms
- Эксперимент‑2: 100 ms
bgwriter_lru_maxpages
- Эксперимент‑1: 515
- Эксперимент‑2: 1000
bgwriter_lru_multiplier
- Эксперимент‑1: 7,0
- Эксперимент‑2: 4,0
Изменённые параметры ядра (vm)
vm.dirty_background_ratio
- Эксперимент‑1: 10 %
- Эксперимент‑2: 2 %
vm.dirty_ratio
- Эксперимент‑1: 30 %
- Эксперимент‑2: 10 %
vm.dirty_writeback_centisecs
- Эксперимент‑1: 500
- Эксперимент‑2: 200
Остальные настройки (work_mem, maintenance_work_mem, wal‑уровни, автовакуум, etc.) остались без изменений.
5. Результаты и выводы
5.1. Количественные показатели (таблица + графики)
Граничные значения производительности и ожиданий СУБД
+40% на пике и в медиане по операционной скорости
Рисунок 2. Сравнение операционной скорости: базовая конфигурация (синий) и после оптимизации pg_expecto + DeepSeek (оранжевый). Медианный прирост составил 40,6%.
Ожидания IO
Рисунок 3. Динамика ожиданий ввода-вывода. Медианные ожидания снизились незначительно (на 2,2%), что указывает на сохранение проблемы с дисковой подсистемой.
5.2. Анализ узких мест (проблемы СУБД и инфраструктуры)
Общий анализ операционной скорости и ожиданий СУБД
Сравнительный анализ граничных значений операционной скорости (SPEED) и ожиданий СУБД (WAITINGS)
SPEED :
- Эксперимент‑1: минимум 375 955, медиана 383 994, максимум 683 866.
- Эксперимент‑2: минимум 472 713, медиана 539 761, максимум 749 919.
Медианная скорость выросла на 40,6 %.
WAITINGS :
- Эксперимент‑1: минимум 48 536, медиана 78 011, максимум 226 349.
- Эксперимент‑2: минимум 47 168, медиана 76 311, максимум 254 309.
Медианные ожидания снизились на 2,2 %, хотя максимальные выросли – возможно, из‑за более интенсивной нагрузки.
Сравнительный анализ трендов операционной скорости и ожиданий СУБД
Тренд SPEED
- Эксперимент‑1: R² = 0,77 (хорошая модель), угол наклона +41,33
- Эксперимент‑2: R² = 0,89 (очень высокая), угол наклона +43,29
- В обоих случаях скорость растёт, во втором эксперименте тренд чуть круче.
Тренд WAITINGS
- Эксперимент‑1: R² = 0,87 (очень высокая), угол +43,01
- Эксперимент‑2: R² = 0,86 (очень высокая), угол +42,90
- Ожидания также растут синхронно со скоростью.
Регрессия SPEED по WAITINGS
- Эксперимент‑1: R² = 0,97, угол +44,56
- Эксперимент‑2: R² = 0,99, угол +44,84
- Связь исключительно сильная, почти линейная.
1. Сравнительный статистический анализ ожиданий СУБД:
Основной источник задержек – операции ввода‑вывода. Прочие типы ожиданий не оказывают заметного влияния на общую нагрузку.
2. Сравнительный трендовый анализ производительности vmstat:
Система испытывает хроническую перегрузку по вводу‑выводу: более 50 % времени wa > 10 %, очередь процессов в состоянии b постоянно превышает количество ядер CPU.
3. Сравнительный статистический анализ ожиданий СУБД и метрик vmstat:
Увеличение shared_buffers и настройка контрольных точек позволили улучшить попадания в кэш и немного сгладить пики записи, однако фундаментальные проблемы с памятью (дефицит свободной RAM) и перегрузкой ввода‑вывода (процессы в состоянии b, высокий wa) остаются.
4. Сравнение диаграмм Парето по wait_event_type и queryid:
Узкое место не изменилось – это по‑прежнему чтение данных с диска (DataFileRead), генерируемое запросом scenario1. Оптимизация не затронула логику самого запроса.
Ключевые проблемы для экспериментов
Эксперимент‑1 («Тантор Лабс»)
Проблемы СУБД
- Недостаточный размер shared_buffers (1,8 GB) – низкая эффективность кэширования.
- Слишком частые контрольные точки (checkpoint_timeout = 15 мин, max_wal_size = 2 GB) – пиковые нагрузки на запись.
- Агрессивная работа bgwriter (bgwriter_lru_multiplier = 7) могла вызывать лишние сбросы.
Проблемы инфраструктуры
- Свободной памяти <5 % в течение всего теста – риск вытеснения страниц.
- Высокий процент IO‑wait (wa >10 % всегда) и очередь процессов в состоянии b (превышение ядер CPU 100 % времени).
- Грязные страницы накапливаются до 18 MB, вызывая блокировки процессов.
- Высокие накладные расходы ядра (sy) из‑за управления памятью.
Эксперимент‑2 (PG_EXPECTO + DeepSeek)
Проблемы СУБД
- Основной запрос scenario1 не оптимизирован – по‑прежнему 85 % ожиданий приходится на чтение с диска.
- Несмотря на увеличение shared_buffers, hit ratio остаётся на уровне 97 %, что недостаточно для полного устранения дисковых чтений.
Проблемы инфраструктуры
- Дефицит свободной памяти усугубился (доступно ~3,5 GB вместо ~4,9 GB) – плата за увеличение shared_buffers.
- IO‑wait и блокировки процессов (b) остались на прежнем критическом уровне.
- Системные вызовы и переключения контекста по‑прежнему крайне высоки.
5.3. Итоговый вердикт (общий вывод)
Итоговый анализ влияния мероприятий
1. Производительность (скорость) выросла на 40 % – это главный положительный эффект.💥
Увеличение shared_buffers, размера WAL и интервала контрольных точек позволило эффективнее использовать кэш и сгладить пики записи.
2. Нагрузка на ввод‑вывод частично перераспределилась
- Корреляция IO с чтением (bi) стала сильнее – теперь чтения из файлов данных лучше отражаются в ожиданиях.
- Корреляция с записью (bo) немного ослабла – запись стала более равномерной.
3. Проблемы операционной системы не устранены
- Свободная память уменьшилась, и её дефицит сохраняется.
- Процессы в состоянии b и высокий IO‑wait остались на прежнем уровне.
- Переключения контекста и нагрузка на ядро не снизились.
4. Запрос‑виновник не оптимизирован
Более 85 % ожиданий по‑прежнему приходятся на select scenario1(). Без изменений в логике запроса или добавления индексов дальнейший рост скорости ограничен.
Общий вывод:
- Проведённая оптимизация дала значительный прирост производительности (медианная скорость +40,6 %) за счёт более эффективного использования памяти и сглаживания записи.
- Однако инфраструктурные ограничения (нехватка RAM, медленная дисковая подсистема) и неоптимизированный запрос остаются «узкими горлами».
- Для дальнейшего улучшения необходимы либо аппаратный апгрейд (больше памяти, более быстрые диски), либо глубокая оптимизация запроса scenario1 (индексы, рефакторинг).
Полный сравнительный анализ:
Послесловие
Проведённый эксперимент наглядно демонстрирует, что даже значительный прирост производительности (медианная скорость +40 %) не является пределом, если остаются нерешёнными фундаментальные проблемы — неоптимизированный запрос и аппаратные ограничения.
Тандем pg_expecto и DeepSeek позволил не только улучшить конфигурацию, но и точно локализовать корневые причины торможений.
На этом эксперименты не заканчиваются. В следующих статьях проверим, как покажут себя pgpro_tune и классический PgTune в аналогичных условиях. Цель — найти идеальный «фундамент» для PostgreSQL 17.
Цель — сравнить эффективность под нагрузкой и определить, какой подход даёт наилучший «фундамент» для последующей тонкой оптимизации с помощью pg_expecto.