услышанного, а не просто распознавать текст. 📌 Основные особенности: 🔵Глубокий анализ аудио (речь, шумы, музыка), а не только распознавание текста 🔵Пошаговое рассуждение на основе звукового сигнала 🔵Улучшение качества при увеличении вычислений во время инференса 🔵Архитектура с аудио-энкодером и крупной языковой моделью 🔵Обучение с фокусом на понимание акустических особенностей, а не только транскрипции 🔵Открытый исходный код и доступные веса модели 🔵Поддержка запуска через Docker и vLLM 📱 Репозиторий ➡️Справочник Программиста. Подписаться
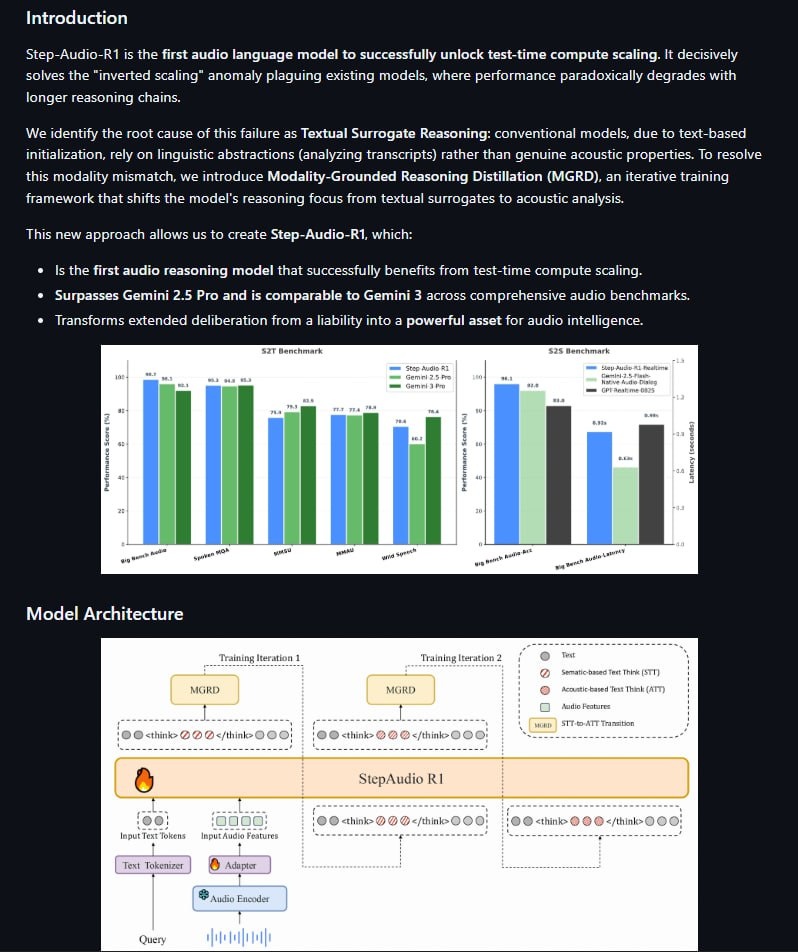
🔈 Step-Audio-R1 — это открытая аудио-языковая модель, которая умеет анализировать речь, звуки и музыку и «рассуждать» по шагам на основе услышанного, а не просто распознавать текст.
📌 Основные особенности:
🔵Глубокий анализ аудио (речь, шумы, музыка), а не только распознавание текста
🔵Пошаговое рассуждение на основе звукового сигнала
🔵Улучшение качества при увеличении вычислений во время инференса
🔵Архитектура с аудио-энкодером и крупной языковой моделью
🔵Обучение с фокусом на понимание акустических особенностей, а не только транскрипции
🔵Открытый исходный код и доступные веса модели
🔵Поддержка запуска через Docker и vLLM
➡️Справочник Программиста. Подписаться