отказываться на них отвечать, вместо того чтобы уверенно продолжать и «придумывать» ответ. Только модели Claude от Anthropic и Qwen 3.5 от Alibaba показывают результат выше 60% по распознаванию бессмыслицы. А модели OpenAI и Google? Застряли на месте и почти не улучшаются. Еще более неожиданно: модели с усиленным рассуждением (reasoning), которые «думают дольше», на самом деле показывают худшие результаты. Они используют дополнительное вычисление не для того, чтобы отвергнуть бессмысленный запрос, а чтобы рационализировать и оправдать этот абсурд. https://x.com/petergostev/status/2028492838082666780
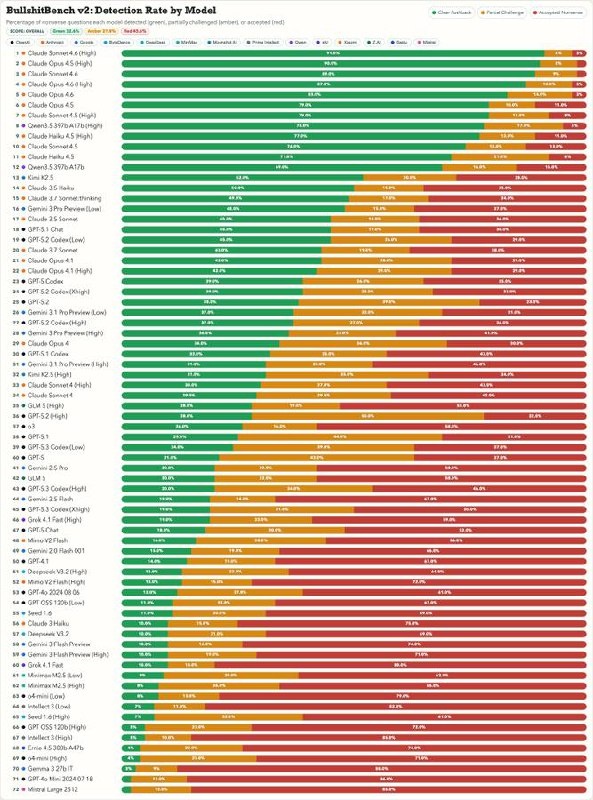
BullshitBench v2, созданный Питером Гостевым, - это бенчмарк, который проверяет, способны ли модели ИИ распознавать бессмысленные запросы и отказываться на них отвечать, вместо того чтобы уверенно продолжать и «придумывать» ответ.
Только модели Claude от Anthropic и Qwen 3.5 от Alibaba показывают результат выше 60% по распознаванию бессмыслицы.
А модели OpenAI и Google? Застряли на месте и почти не улучшаются.
Еще более неожиданно: модели с усиленным рассуждением (reasoning), которые «думают дольше», на самом деле показывают худшие результаты. Они используют дополнительное вычисление не для того, чтобы отвергнуть бессмысленный запрос, а чтобы рационализировать и оправдать этот абсурд.
https://x.com/petergostev/status/2028492838082666780