Модель с триллионом параметров буквально «удалила половину своего мозга» и стала умнее.
Yuan3.0 Ultra**-— новая open-source мультимодальная **MoE-модель от Yuan Lab.
Всего 1010 млрд параметров, но при инференсе активны только 68.8 млрд.
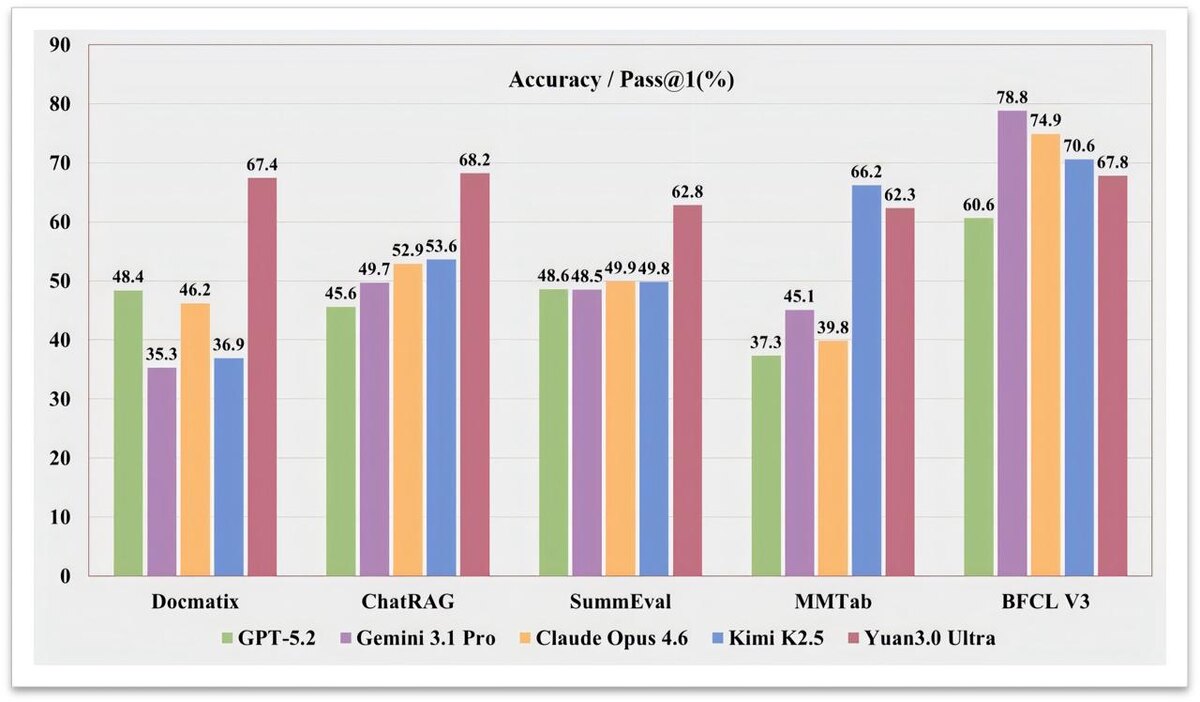
На бенчмарках RAG она обошла GPT-5.2, Gemini 3.1 Pro и Claude Opus 4.6 с заметным отрывом.
Например:
- 67.4% на Docmatix против 56.8% у GPT-4o
Что умеет модель:
- Enterprise RAG - 68.2% средней точности на 10 задачах поиска
- Анализ сложных таблиц - 62.3% на бенчмарке MMTab
- Text-to-SQL - 83.9% на Spider 1.0
- Мультимодальный анализ документов с контекстом 64K
Ключевая инновация — Layer-Adaptive Expert Pruning (LAEP).
Во время предобучения у MoE возникает сильный дисбаланс:
некоторые эксперты получают в 500 раз больше токенов, чем другие.
LAEP постепенно удаляет малоиспользуемых экспертов слой за слоем,
что позволяет:
- сократить 33% параметров
- увеличить эффективность обучения на 49%
Также исследователи улучшили метод “fast-thinking” RL.
Теперь система больше награждает ответы, которые:
- правильные
- используют меньше шагов рассуждения
Это позволило:
- уменьшить количество выходных токенов на 14.38%
- повысить точность на 16.33%
Главный сигнал из этого исследования:
MoE-модели начинают сжимать себя прямо во время обучения, а не после.
Если pruning станет частью pretraining, стоимость обучения триллионных моделей может резко снизиться.
https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra