
n8n-сценарий превращает статьи в подкасты с голосом нейросети — настройка за час без кода | Марина Погодина, PROMAREN
n8n OpenAI интеграция в 2026 в РФ уже не про «игрушки с ИИ», а про очень приземлённую экономию: один час на настройку — против недель ручной озвучки и монтажа подкастов из статей.
Обновлено: 7 февраля 2026
Время чтения: 12-14 минут
- Как работает n8n и зачем он подкастам
- Что даёт OpenAI в этой связке
- Как превратить статью в подкаст с помощью AI
- Можно ли реально автоматизировать подкасты
- Почему команда в итоге выбирает n8n
В начале 2026 я поймала себя на странной мысли: люди по-прежнему часами монтируют подкасты вручную, хотя та же работа уже спокойно крутится на n8n в фоне. Кофе остывает, а кто-то всё ещё двигает маркеры в аудиоредакторе.
По опыту PROMAREN, связка n8n и OpenAI спокойно превращает статьи в подкасты за минуты, причём под 152-ФЗ, с контролем данных и в белой зоне. Я не обещаю магию, но покажу, как за час собрать систему, которая потом экономит десятки часов в месяц.
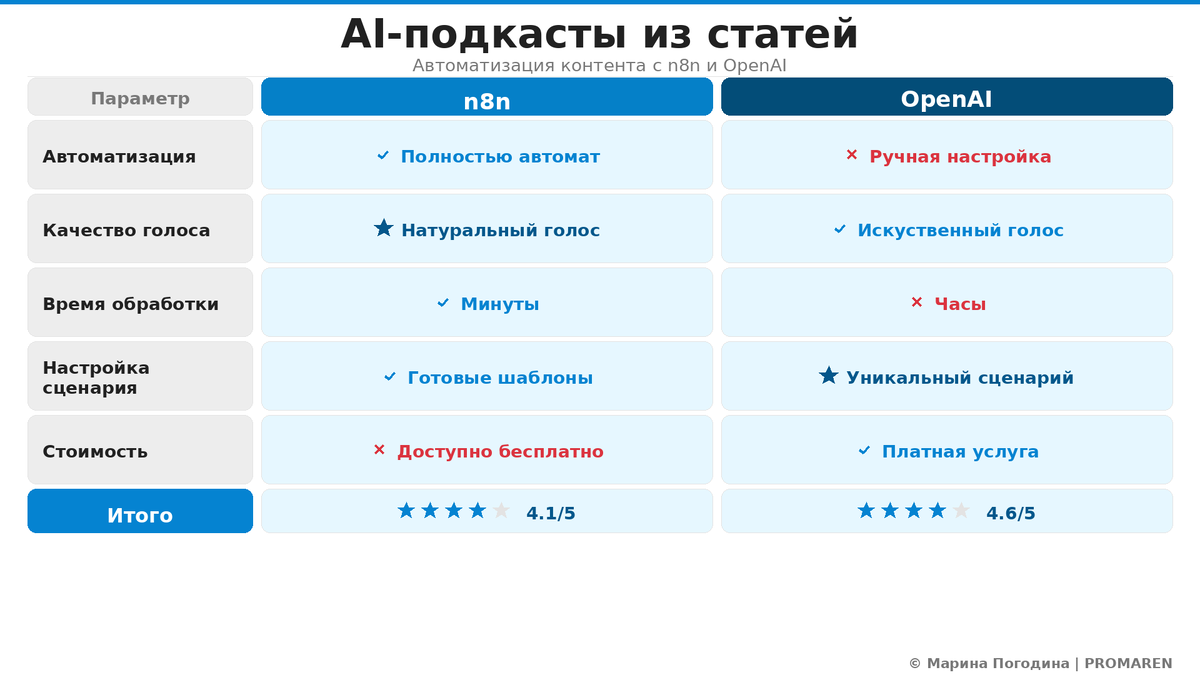
Как работает n8n и зачем он подкастам
3 из 5 рабочих процессов для подкастов в 2026 у моих клиентов собираются в n8n — это визуальный конструктор, который склеивает CMS, OpenAI, облака и Telegram в один поток без кода. Для подкаста это означает: вы один раз собрали схему и больше не думаете о рутине.
Если коротко, n8n — это платформа автоматизации с визуальными workflow, где вы соединяете узлы: триггер, обработка текста, интеграция с AI, выгрузка аудио. Каждый узел делает одну понятную вещь, а в сумме выходит конвейер. n8n не привязан к какому-то одному вендору, поэтому в РФ его удобно ставить как нейтральный слой между локальными и зарубежными сервисами.
Рабочий день у такого workflow очень приземлённый: новая статья появилась в CMS, триггер в n8n её подхватил, текст уехал в OpenAI, вернулся сценарий, ушёл в сервис озвучки, результат сохранился в облако и тут же улетел в ваш Telegram-канал. Ни один человек не открыл редактор звука, максимум — посмотрел на лог и спокойно допил свой чай.
Что такое workflow в n8n на языке подкаста
Workflow в n8n — это цепочка шагов, где каждый шаг отвечает за свой кусочек: поймать текст, переписать, озвучить, разложить по полочкам. Мне нравится думать о нём как о внутреннем продюсере, который не устаёт и не забывает сохранить файл. Есть триггеры (вебхук, новая запись в Notion, письмо), есть ноды интеграций (OpenAI, Google Drive, Telegram), есть логика ветвлений, если что-то пошло не так.
В 2026 я всё чаще вижу, как компании перестают бояться автоматизации именно после первого визуального workflow в n8n — становится очевидно, что это не «чёрный ящик», а прозрачная схема. Когда ты видишь, куда уходит текст и откуда возвращается звук, доверия становится намного больше. Особенно если рядом лежит схема обработки данных под 152-ФЗ с пометкой legal approved.
Где тут место для OpenAI и голоса
В истории с подкастами n8n выступает не как ИИ, а как грамотный диспетчер: он знает, что OpenAI превращает сухую статью в живой сценарий, а сервис озвучки — в голос. Вы подключаете API OpenAI прямо из ноды или через HTTP-запрос, прописываете промпт, и текст статьи тает, превращаясь в диалог ведущего и эксперта. Дальше этот сценарий спокойно переезжает в ElevenLabs или другой TTS.
Это критично, потому что без честной архитектуры под 152-ФЗ весь красивый ИИ превращается в риск, а не в помощь. В подходе PROMAREN мы всегда рисуем карту потоков данных: какие поля попадают в OpenAI, что остаётся в контуре, где включается анонимизация. Стоп, про OpenAI как таковой расскажу отдельно — это следующий логичный шаг.
Что даёт OpenAI в этой связке
OpenAI в паре с n8n берёт на себя два тяжёлых блока — переписывание текста в сценарий и работу со звуком через Whisper, если вы идёте в обратную сторону. Это именно тот кусок, который раньше отнимал дни у редакторов и продюсеров.
Согласно документации OpenAI (официальный сайт), модели GPT умеют адаптировать стиль текста, а Whisper API — стабильно распознавать речь на русском. По данным McKinsey о влиянии генеративного ИИ на производительность (отчёт 2023), такие задачи как подготовка контента выигрывают до 40% времени.
Как я объясняю OpenAI не-айтишникам
OpenAI — это набор моделей, которые либо понимают текст и генерируют новый, либо переводят звук в текст и обратно. В кейсах с подкастами нас обычно интересуют GPT для сценариев и Whisper для транскрибации. Я обычно говорю так: «GPT — это ваш сценарист, Whisper — расшифровщик созвона, который никогда не устает и не просит аванс» (нет, лучше скажу иначе) — он просто очень терпеливый стажёр.
Когда подключаешь OpenAI к n8n, всё становится немного скучно в хорошем смысле: в ноде прописан промпт, указана модель, и дальше текст летает туда-обратно без участия человека. Самое сложное тут — не интеграция API, а формулировка промпта, чтобы сценарий подкаста звучал живо, а не как отчёт аудитора. Кстати, на сайте PROMAREN я иногда выкладываю рабочие промпты из проектов — сильно экономит время.
Голос: OpenAI или сторонние сервисы
С голосом в 2026 есть развилка: либо вы используете встроенные TTS-возможности OpenAI, либо подключаете ElevenLabs, Яндекс или другой сервис через API. По данным ElevenLabs из открытой документации, стартовые тарифы позволяют бесплатно озвучить несколько десятков минут в месяц, этого часто хватает на пилот. В n8n эти варианты выглядят одинаково — просто разные ноды HTTP.
Я в проектах подкастов чаще беру именно внешний TTS, потому что там больше гибкости по голосам и контролю эмоций. Но если задача — быстро собрать MVP на внутренний подкаст компании, встроенный голос OpenAI звучит уже терпимо. И тут мы подходим к самому интересному: как из всего этого собрать конвейер «статья → подкаст» так, чтобы он не развалился на третьей итерации.
Как превратить статью в подкаст с помощью AI
Типичный конвейер «статья → подкаст» в n8n укладывается в 6-8 нод и реально собирается за час — если не зависать на выборе голоса и музыки. Дальше он тихо крутится неделями, пока редакция привыкает, что подкаст появляется почти сам.
Я протестировала несколько таких сценариев для клиентов PROMAREN, и паттерн всегда один: входящий текст, обработка через OpenAI, озвучка, сохранение. Детали сильно зависят от источника статьи — кто-то живет в Notion, кто-то в локальной CMS, кто-то вообще кидает тексты в Telegram-бота.
Логика процесса от статьи до аудио
В базовом варианте схема выглядит так: n8n ловит новую статью из CMS или Google Docs, забирает заголовок, тело и метаданные. Этот текст уезжает в ноду OpenAI с промптом в духе: «Преврати текст статьи в сценарий подкаста с двумя голосами, без перечислений и с живым разговорным стилем». На выходе у нас уже диалог, который гораздо легче слушать, чем исходный лонгрид.
Дальше сценарий отправляется в сервис голосовой озвучки: там вы один раз выбираете голос (или клонируете свой, если этически и юридически всё ок) и скорость речи. На выходе — mp3 или wav-файл, который n8n складывает в облако, кидает ссылку в рабочий чат и при необходимости публикует в RSS-фид подкаста. С человеческой стороны всё сводится к тому, что вы один раз пишете статью и нажимаете кнопку.
Какие ноды обычно входят в такой workflow
Здесь работает простой набор блоков, который почти не меняется от проекта к проекту:
- Триггер: вебхук, новая запись в CMS или команда боту в Telegram
- Нода получения текста: HTTP Request, Notion, Google Docs или база данных
- Нода OpenAI: GPT для переписывания статьи в сценарий
- Нода TTS: ElevenLabs, OpenAI TTS или локальный сервис
- Нода сохранения: Google Drive, Яндекс.Диск, S3-хранилище
- Нода доставки: Telegram, Email или публикация в RSS
Иногда я добавляю ещё один шаг — нормализацию громкости или склейку с джинглом, но это уже эстетика, а не необходимость. На странице с кейсами автоматизации у меня есть парочка таких схем, где видно, как выглядит реальный workflow, а не рисованный пример из презентации.
Кейс: внутренняя рассылка → еженедельный подкаст
Один из любимых кейсов PROMAREN — когда HR-рассылку в крупной компании хотели перевести в формат подкаста для сотрудников. Статьи уже существовали, времени на запись у спикеров не было совсем. Мы собрали workflow: письмо с текстом падает в отдельный ящик, n8n забирает его, OpenAI переписывает в дружеский монолог, голосовой сервис озвучивает «ведущего», и через 10 минут файл лежит в корпоративном приложении.
Смешно, но первый месяц люди искренне думали, что это записывает живой человек — настолько аккуратно шли паузы и интонации. Здесь сработала простая вещь: мы не пытались сделать идеально с первой попытки, а дали себе неделю на правки промптов и голоса. Дальше уже можно было думать, как автоматизацию масштабировать, и тут мы плавно подходим к вопросу: а насколько «полностью» можно это всё автоматизировать.
Можно ли реально автоматизировать подкасты
Короткий ответ — да, но не на 100%, если вы заботитесь о бренде, тоне и юридических рисках. На уровне технологий сейчас уже закрывается вся цепочка: от идеи до публикации, без участия человека в операционке.
По данным агентских кейсов, с которыми я сталкивалась в 2025-2026, автоматизация на платформе n8n вкупе с OpenAI снимает у контент-команды от 30 до 50 часов в неделю. Это подтверждают и глобальные обзоры автоматизации маркетинга, тот же Gartner регулярно пишет о росте доли no-code оркестраторов (официальный сайт Gartner). Но сухие цифры мало убеждают, пока не разложишь, из чего именно складывается эта экономия.
Где автоматизация действительно экономит время
Я поняла, что основной выигрыш не в самом факте «ИИ-голосов», а в том, что исчезают скучные повторяющиеся шаги. Редакторы перестают править одни и те же формулировки, продюсеры не ждут, когда диктор освободится, и не следят за выгрузкой на платформы. n8n в этом смысле просто аккуратно собрал всё, что раньше было размазано между людьми и сервисами.
Если разнести по полочкам, то выигрыши обычно такие: AI сразу пишет сценарий в нужном формате, не приходится переписывать под устную речь; голос генерируется автоматически, без студии и микрофонов; публикация в Telegram и подкаст-платформы уходит в фоновый режим. Получается, что человеческое время тратится только на отбор тем и редкие правки, а не на транскрибацию и экспорт файлов.
Какие элементы я всё же оставляю человеку
Конечно, очень хочется нажать одну кнопку и уйти гулять, пока подкаст штампуется сам 😅 Но на практике я всегда закладываю минимум одну точку human review. Это может быть короткий чек-лист: сценарий не противоречит политике компании, нет фактологических ошибок, тон общения соответствует бренду. В n8n это реализуется через узел, который ждёт подтверждения в интерфейсе или в Telegram.
Кроме того, все истории с клонированием голоса я проговариваю с юристами клиента: кто владеет правами, есть ли письменные согласия, как это описано в договорах. Я раньше думала, что достаточно устного согласия спикера, но после пары консультаций с юротделами крупнейших компаний в РФ стала гораздо аккуратнее. И вот на этом фоне становится видно, почему многие команды в итоге выбирают именно n8n как оркестратор всей этой красоты.
Этап Что делает n8n Что делает человек Текст → сценарий Отправляет в OpenAI, получает сценарий Иногда корректирует промпт Сценарий → аудио Шлёт текст в TTS, сохраняет файл Выбирает голос и стиль Публикация Раскладывает по платформам Утверждает финальную версию
Почему команда в итоге выбирает n8n
В начале 2025 я думала, что выбор между n8n и другими платформами автоматизации будет упираться в «что дешевле». После десятка проектов с подкастами стало ясно — в реальности побеждает тот инструмент, который спокойно живёт в инфраструктуре компании и не требует жертвоприношений от ИТ.
У n8n здесь оказалось несколько очень приземлённых, но сильных сторон: его можно развернуть на своём сервере, под управлением своих админов; он гибко работает с любыми API (включая OpenAI и локальные модели); и он достаточно прозрачен для внутреннего аудита. Для меня, как бывшего аудитора, это прямо аргумент, который сложно переоценить.
Что решает выбор в пользу n8n в 2026
На практике компании сравнивают n8n с Make.com, Zapier и кастомной разработкой. Zapier часто отваливается из-за ограничений в РФ, кастомная разработка дорога в сопровождении, Make.com нравится дизайном, но хуже вписывается в on-premise. n8n при этом можно крутить у себя, подчинять своим правилам и интегрировать хоть с OpenAI, хоть с локальной LLM через HTTP.
Здесь работает простое правило: если автоматизация подкастов становится частью серьёзной контентной машины, оркестратор должен принадлежать вам, а не внешнему облаку. По опыту PROMAREN, это особенно чувствуется в компаниях с жёсткими требованиями по 152-ФЗ и внутренним политикам ИБ — там даже мелкие подкасты относятся к данным всерьез.
Гибкость и масштабируемость без боли
Вторая причина популярности n8n — его модульность. Когда вам нужно заменить OpenAI на Яндекс.GPT или внутреннюю модель, вы меняете одну ноду, а не переписываете полпроекта. То же самое с голосами, хранилищами, каналами доставки. Инфраструктура подкастов живёт, как живой организм, но при этом не рассыпается от каждого нового сервиса.
На канале PROMAREN у меня есть разбор одного проекта, где сначала был только Telegram-бот, потом добавился сайт на Cursor, потом CRM-интеграция — а ядро на n8n не пришлось переписывать. Хотела сделать идеально сделала «достаточно гибко», и это неожиданно стало конкурентным преимуществом. Если хочется посмотреть, как такие штуки выглядят в жизни, можно заглянуть в раздел про лендинг на Cursor с интеграцией — логика оркестрации там очень похожа.
Сколько времени это реально занимает
Честный тайминг из практики: первый рабочий сценарий n8n OpenAI интеграция для подкаста обычно занимает 40-60 минут от чистого листа. Да, потом вы ещё пару дней шлифуете промпты и голоса, но уже с работающей основой. Для команды, которая привыкла тратить по 2-3 часа на выпуск одного эпизода, это прям смена реальности.
Дальше всё зависит от амбиций: кто-то останавливается на одном автоматическом шоу, кто-то строит целый «завод» из текстов, рассылок, видео и подкастов. На боте с тестовым доступом можно как раз почувствовать, как это работает в режиме самообслуживания. А под финал давай соберём всё это в три мысли, чтобы не утонуть в деталях.
Когда подкаст делает конвейер, а не герой-энтузиаст
Я вижу одно и то же в разных компаниях: пока подкаст держится на одном человеке, он либо выгорает, либо превращается в редкий спецвыпуск. Как только в игру заходит n8n с OpenAI, формат вдруг становится устойчивым — не потому что нейросети «волшебные», а потому что система забирает на себя рутину.
Автоматизация не отменяет вкуса, этики и редакторского чутья, но перестаёт требовать от людей ночных посиделок в монтажке. Для кого-то это просто экономия часов, для кого-то — шанс наконец-то завести подкаст без страха, что «мы его не вывезем».
Если аккуратно отнестись к данным, правам на голос и точке human review, связка n8n и OpenAI получается очень рабочей. А дальше вопрос только в том, сколько процессов вокруг подкаста вы готовы отдать машине, чтобы самим вернуться к стратегии, а не к таймлайну в редакторе.
Обо мне. Марина Погодина, основательница PROMAREN и AI Governance & Automation Lead. С 2024 года помогаю в РФ строить автоматизацию на n8n, Make.com, Cursor, внедряю AI-агентов. Пишу в блоге и канале.
Если хочешь глубже разобрать автоматизацию подкастов или собрать свой контент-завод, можно начать с разборов и схем в блоге PROMAREN — они помогают понять архитектуру без погружения в код. А когда захочется практики, всегда можно дёрнуть меня или попробовать ботов с автоматизацией и AI-сценариями.
Что ещё важно знать про n8n и OpenAI для подкастов
Можно ли обойтись без OpenAI и взять только локальные модели
Можно, если у вас есть доступ к локальным LLM и TTS с приемлемым качеством речи. В таком случае n8n просто обращается не к OpenAI, а к вашему внутреннему API, логика workflow почти не меняется. Главное — чтобы модель умела писать сценарии, а голосовой сервис звучал достаточно естественно, иначе выигрыш по времени пропадёт на ручной доработке. Для закрытых компаний это часто единственный допустимый путь.
Что делать, если контент чувствительный по 152-ФЗ
Тогда первым делом нужно нарисовать карту данных и понять, какие поля вообще можно отправлять во внешние сервисы. n8n помогает здесь тем, что вы чётко видите, какой узел шлёт что и куда, и легко вставляете шаг анонимизации. Можно вынести всё, что попадает под 152-ФЗ, в отдельный контур и использовать OpenAI только для обезличенных текстов. При необходимости стоит подключить юристов и ИБ ещё на этапе проектирования.
Как контролировать затраты на API OpenAI и TTS
Самый надёжный способ — заложить ограничения прямо в архитектуре workflow. В n8n это можно сделать через переменные и условия: ограничить длину текста, считать вызовы в сутки, останавливать сценарий при превышении лимита. Параллельно имеет смысл завести простую табличку с расчётом стоимости минуты подкаста, чтобы видеть, сколько вы платите за один выпуск. Тогда разговор с финансовым директором становится гораздо спокойнее.
А если команда совсем не дружит с автоматизацией
В такой ситуации лучше не пытаться продать сразу «волшебную кнопку», а начать с одного понятного кейса. Например, автоматизировать только создание черновика сценария через OpenAI, а озвучку пока оставить людям. Когда команда увидит, что n8n не ломает процессы и даёт предсказуемый результат, можно добавлять TTS и публикацию. Пошаговое внедрение снижает сопротивление и даёт время всем привыкнуть к новой роли ИИ в работе.
Нужен ли отдельный человек под поддержку n8n-сценариев
Если у вас один-два простых workflow, обычно хватает пары часов в месяц того, кто их настраивал. Когда автоматизация подкастов превращается в большую фабрику с десятками веток, имеет смысл выделить ответственного за оркестратор. Это не обязательно программист, скорее продакт или тех-лид контент-направления, который понимает бизнес-логику. Его задача — следить за стабильностью, править промпты и планировать развитие схем.