
В прошлом выпуске я писал про LM Studio — это красивый графический интерфейс для знакомства с локальными нейросетями, то Ollama — это профессиональный инструмент для разработчика и инженера. Это open-source платформа (лицензия MIT ), которая позволяет поднять полноценный AI-сервер на вашей машине за считанные минуты.
Сегодня мы не будем обсуждать "как просто поболтать с ИИ". Мы поговорим о том, как поднять API-совместимый с OpenAI бэкенд (bckend) и фронтенд (frontend), писать код для интеграции и использовать готовые решения из экосистемы.
Почему Ollama, а не просто llama.cpp?
llama.cpp — это гениальный инженерный подвиг, но работать с ним в лоб — это как писать сайты на чистом JS когда уже все есть. Ollama же предлагает абстракцию и экосистему:
- Простое управление моделями: Одна команда (ollama pull llama3) скачивает модель, квантует её и готовит к работе .
- REST API из коробки: Вам не нужно писать обертки. После запуска (ollama serve) вы получаете полноценный эндпоинт localhost:11434 .
- Поддержка GPU и CPU: "Из коробки" работает как с NVIDIA (CUDA), так и с Apple Metal, и с чисто CPU-инференсом .
- Реестр моделей: Сотни готовых к использованию моделей (от DeepSeek-R1 и Qwen 3 до специфических GGUF-сборок)
Так как мы говорим об искуственном интелекте, мы затрагиваем сложные слова, оно из которых - это "квантование". Все сложное буду пояснять и расширять ваши знания.
Квантование (Quantization) — что это простыми словами?
Представьте, что нейросеть — это огромная библиотека знаний. Каждое знание (вес нейрона) в оригинале записано с фантастической точностью — как число с 16 знаками после запятой (это называется float32 или float16).
Квантование — это процесс, когда мы говорим: "А давайте округлим эти числа до 2-3 знаков после запятой". Книга станет чуть менее точной, но займет в 4 раза меньше места на полке.
В контексте нейросетей это переводится так:
- Меньше места на диске (модель "худеет" с 70 ГБ до 4 ГБ)
- Меньше оперативной памяти нужно для работы
- Выше скорость генерации текста
- Немного хуже качество ответов (но часто это незаметно)
Рассмотрим табличные данные для примера
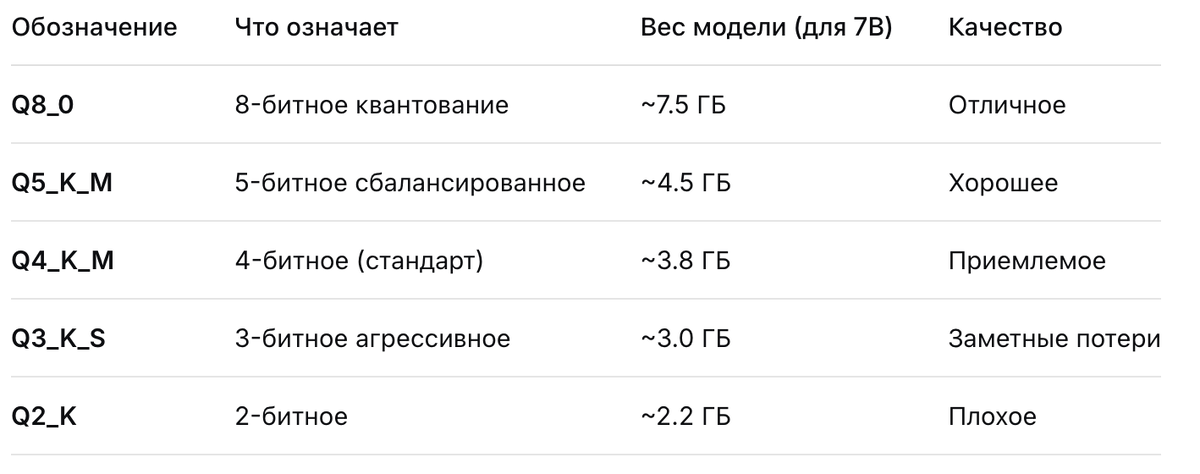
Как расшифровать описание модели и тонкости в моделях
Все модели имеют буквенное обозначние, к примеру Q4_K_M: Буква "K" означает, что используется метод квантования от llama.cpp, а "M" — средний (medium) размер, баланс между скоростью и качеством. Это применимо к любой модели, но в зависимости от производителя модели есть нюансы. Они обычно описаны в документации на модель.
Важное замечание к квантованию. Чем сильнее сжата модель, тем меньше контекста она может удержать. Модель в Q8 спокойно обработает "Войну и мир", а Q2 начнет "забывать" начало диалога уже через пару страниц текста.
Исследования (и опыт сообщества) показывают, что для 90% задач разница между Q8 и Q4 незаметна. Нейросети удивительно устойчивы к потере точности весов — как человек, который читает текст с опечатками, но все равно понимает смысл.
Более того, существует понятие перплексии (perplexity) — метрики "растерянности" модели. При Q4 она вырастает всего на 2-5%, а размер уменьшается на 60-70%.
Интеграция в код.
Давайте посмотрим, как использовать Ollama в реальной разработке. В отличие от LM Studio, где общение с нейросетью обычно заканчивается в окне чата, Ollama позволяет встроить AI прямо в логику вашего приложения.
Пример прямого вызовы к API (Curl)
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5",
"prompt": "Почему небо голубое?",
"stream": false
}'
Это все отработает в консоли и вы получите ответ. Привел его для понимания и тестирования. Но нас интересует более глубокая работа с LLM поэтому движемся дальше.
Управление моделями через API
Для технарей важно, что всем можно управлять программно. Захотелось скачать новую модель на прод-сервере ночью по расписанию? Без проблем, автоматизируем это через API Ollama - там это под капотом
curl http://localhost:11434/api/pull -d '{
"model": "mixtral:8x7b"
}'
Не буду расписывать код как это применить в рабочем контуре, в проекте GIT который в конце статьи все будет приложено.
Вместо вывода.
Для работы с LLM локально и безопасно в рамках серверных ресурсов Ollama идеальное решение. Развернуть систему достаточно просто, доступное API для работы позволяет решить очень много задач.