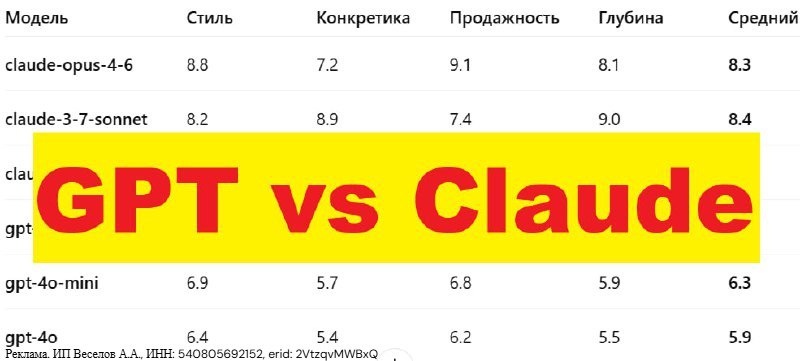
🔥 Кто пишет лучше: GPT или Claude?
Я протестировал 6 моделей ИИ на одном и том же массиве данных. Один промпт. Никаких поблажек.
Взял 4 разные компании:
🧂 Минерал — поставщик соли
🚚 Growex — международная логистика
💻 Кодерлайн — партнёр 1С (IT)
📈 Инженеры продаж — digital-агентство
Каждой модели «скормил» один и тот же промпт.
Задача — написать цепочки писем для B2B-аутрича.
Вот что они написали см. примеры писем 👇
https://docs.google.com/spreadsheets/d/1RdIewueh3DBBxZ2OPmRsDa5TuPnmmVw6jCIa6NEJ_VI/edit?gid=0#gid=0
📊 Что дальше?
Я попросил Deepseek, KIMI, ChatGPT и Gemini оценить письма — так же, одним и тем же промптом.
Но самое интересное началось потом 👇
Когда результаты разошлись,
я показал ChatGPT и Gemini рассуждения моделей,
с которыми они не совпали.
Они пересмотрели аргументацию.
Скорректировали оценки.
📌 Финальные результаты — на картинках (в первом комменте).
💥 Вывод?
Claude и GPT пишут по-разному. Где-то выигрывает агрессия и хантинг. Где-то — системность и глубина.
И это уже не субъективщина.
Это сравнение лоб в лоб.
Если вам нужен предсказуемый поток B2B-лидов — а не хаотичные ответы «вдруг повезёт» —
Соберу аутрич-систему под ключ: позиционирование, гипотезы, цепочки писем, логику касаний и контроль метрик.
Это не «рассылка ради рассылки». Это управляемая генерация лидов.
В работу беру ограниченное количество проектов.
Пишите 👉 @veselovandrei