GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
GitFlic - pg_expecto - статистический анализ производительности и ожиданий СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен
В настоящем исследовании проведен сравнительный анализ эффективности двух подходов к конфигурированию СУБД PostgreSQL 17 — рекомендаций Тантор Лабс и утилиты pgpro_tune. В качестве инструментария использовался диагностический комплекс pg_expecto, позволяющий выполнить статистический анализ производительности и ожиданий СУБД. Эксперимент проводился на идентичной аппаратной конфигурации (8 vCPU, 8 GB RAM) с фиксированной OLTP-нагрузкой. В ходе работы был выполнен анализ операционной скорости, временных рядов, корреляционных связей между метриками СУБД и инфраструктуры, а также распределения ожиданий по типам и запросам. Полученные данные свидетельствуют о том, что конфигурация pgpro_tune обеспечила прирост медианной производительности на 12% при сопоставимом уровне ожиданий. Вместе с тем, в обоих случаях зафиксировано критическое узкое место дисковой подсистемы, выразившееся в доминировании IO-ожиданий (99,9%), при этом 85% всех ожиданий пришлось на единственный запрос. В статье изложены результаты сравнительного анализа и обозначены направления дальнейшей оптимизации.
Входные данные для конфигураторов
- CPU = 8
- RAM = 8GB
- Тип нагрузки = OLTP
- Платформа = Linux
- Версия PostgreSQL = 17
Конфигурация СУБД - Тантор Лабс
Конфигурация СУБД - pgpro_tune
Сводный отчет по производительности СУБД и инфраструктуры - "Тантор Лабс".
Сводный отчет по производительности СУБД и инфраструктуры - pgpro_tune.
Сводный сравнительный отчет по производительности СУБД и инфраструктуры
Эксперимент-1 (Конфигуратор Тантор Лабс)
- Дата и время сбора: 2026-03-05 18:09 – 20:31
- Версия PostgreSQL: 17.5
- Аппаратное обеспечение: 8 vCPU, 7.5 GB RAM, диски LVM (data – 100GB, wal – 50GB, log – 30GB)
Эксперимент-2 (Конфигуратор PGPRO_TUNE)
- Дата и время сбора: 2026-03-07 10:24 – 12:46
- Версия PostgreSQL: 17.5
- Аппаратное обеспечение: идентично Эксперименту-1
Общая информация
Конфигурационные параметры СУБД и VM
Основные различия в настройках PostgreSQL:
shared_buffers:
- Тантор: 1779 MB
- PGPRO: 1919 MB
effective_cache_size:
- Тантор: 5081 MB
- PGPRO: 3838 MB
work_mem:
- Тантор: 35 MB
- PGPRO: 32 MB
maintenance_work_mem:
- Тантор: 196 MB
- PGPRO: 479 MB
autovacuum_work_mem:
- Тантор: 189 MB
- PGPRO: 239 MB
max_connections:
- Тантор: 91
- PGPRO: 239
max_wal_size / min_wal_size:
- Тантор: 2021 MB / 1010 MB
- PGPRO: 4 GB / 2 GB
bgwriter:
- Тантор: delay = 54 ms, maxpages = 515, multiplier = 7.0
- PGPRO: delay = 20 ms, maxpages = 4000, multiplier = 4.0
effective_io_concurrency:
- Тантор: 128
- PGPRO: 200 (комментарий для NVMe)
random_page_cost: оба 1.1 (NVMe SSD)
jit:
- Тантор: включён
- PGPRO: выключен
checkpoint_timeout:
- Тантор: 15 min
- PGPRO: не указан (вероятно, по умолчанию 5 min)
Общий анализ операционной скорости и ожиданий СУБД
Сравнительный анализ граничных значений операционной скорости (SPEED) и ожиданий СУБД (WAITINGS)
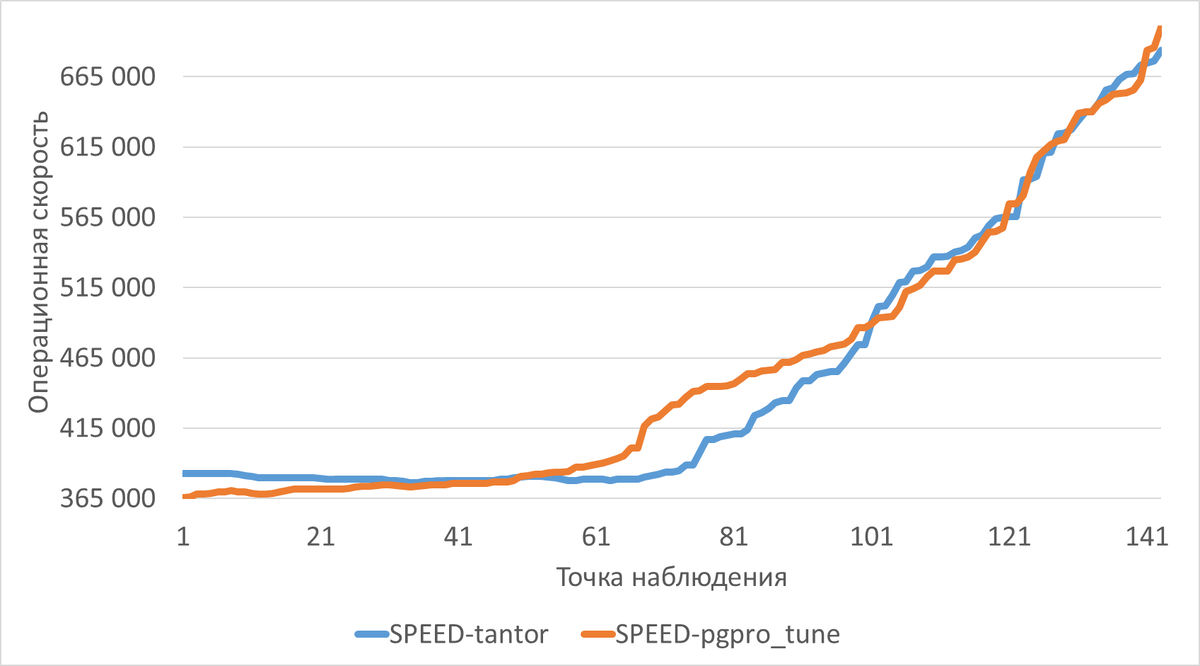
Операционная скорость (SPEED):
Минимальное значение:
- Тантор: 375 955
- PGPRO: 365 651
Медианное значение:
- Тантор: 383 994
- PGPRO: 431 390 (на ~12% выше)
Максимальное значение:
- Тантор: 683 866
- PGPRO: 700 651
Ожидания СУБД (WAITINGS):
Минимальное значение:
- Тантор: 48 536
- PGPRO: 49 679
Медианное значение:
- Тантор: 78 011
- PGPRO: 79 032
Максимальное значение:
- Тантор: 226 349
- PGPRO: 240 293
Медианная скорость в эксперименте PGPRO выше на ~12% при незначительно более высоких медианных ожиданиях.
Разброс значений (max–min) в обоих экспериментах сопоставим.
Сравнительный анализ трендов операционной скорости (SPEED) и ожиданий СУБД (WAITINGS)
Тренд SPEED (по времени):
- Тантор: R² = 0.77 (хорошее качество), угол наклона +41.33 – модель достоверно описывает рост скорости.
- PGPRO: R² = 0.86 (очень высокое), угол наклона +42.89 – более сильная и прогностичная модель.
Тренд WAITINGS (по времени):
- Тантор: R² = 0.87, угол +43.01
- PGPRO: R² = 0.87, угол +43.07 – практически идентичные показатели, рост ожиданий устойчив.
Регрессия SPEED по WAITINGS:
- Тантор: R² = 0.97, угол +44.56 – исключительно сильная связь.
- PGPRO: R² = 0.99, угол +44.83 – практически функциональная зависимость.
Вывод: в обоих экспериментах операционная скорость жёстко привязана к объёму ожиданий (вероятно, из-за доминирования IO-ожиданий). PGPRO демонстрирует более высокую детерминированность модели.
1. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД
Интегральный приоритет типов ожиданий:
- В обоих экспериментах единственный значимый тип – IO с приоритетом 0.6271.
Остальные типы (IPC, Lock, LWLock, Timeout) имеют статистически значимые корреляции, но их взвешенная корреляция (ВКО) < 0.01, поэтому они игнорируются.
- BufferPin и Extension – корреляция отсутствует или отрицательная.
Качество регрессионной модели для IO:
- Оба эксперимента: R² = 1.00, угол +45.00 – идеальная линейная зависимость общих ожиданий от IO-ожиданий.
Итог по разделу:
Основной источник ожиданий – операции ввода-вывода. Нагрузка полностью IO-ориентирована.
2. СРАВНИТЕЛЬНЫЙ ТРЕНДОВЫЙ АНАЛИЗ ПРОИЗВОДИТЕЛЬНОСТИ vmstat
Ключевые метрики и их тренды:
procs -> r (очередь на выполнение):
- Тантор: R² = 0.74 (хорошая модель), угол +40.74 – негативный тренд, высокая скорость изменения (коэф. 30.21). Требует анализа CPU/планировщика.
- PGPRO: R² = 0.18 (непригодная модель), изменения статистически незначимы – игнорируется.
procs -> b (процессы в uninterruptible sleep, ожидание IO):
- Тантор: R² = 0.87, угол +42.95 – очень сильный рост, коэф. 37.23. Сигнал к исследованию дисковой подсистемы.
- PGPRO: R² = 0.87, угол +43.00 – аналогично, коэф. 37.39.
cpu -> wa (процент простоя CPU в ожидании IO):
- Тантор: R² = 0.03 – модель бесполезна, тренд отсутствует.
- PGPRO: R² = 0.24 (слабая модель), угол +26.12 – слабый, но положительный тренд. Рекомендовано фоновое наблюдение.
cpu -> id (процент полного простоя CPU):
- Тантор: R² = 0.91, угол -43.66 – сильное падение, коэф. 39.74.
- PGPRO: R² = 0.96, угол -44.41 – ещё более выраженное падение, коэф. 42.60.
- Оба эксперимента требуют выяснения причин снижения полезной работы CPU.
Итог по разделу:
- В эксперименте Тантор дополнительно наблюдается рост очереди процессов на выполнение (procs r), что может указывать на возросшую конкуренцию за CPU или неэффективность планировщика.
- Главная общая проблема – стремительный рост числа процессов, заблокированных в IO (procs b), и падение idle CPU, что свидетельствует о нарастающем IO-узком месте.
3. СРАВНИТЕЛЬНЫЙ СТАТИСТИЧЕСКИЙ АНАЛИЗ ОЖИДАНИЙ СУБД И МЕТРИК vmstat
Относительные показатели:
- us+sy > 80%: 0% в обоих – нагрузка не перегружает CPU вычислениями.
- r превышение числа ядер CPU: 0% – очередь на выполнение не превышает 8.
- sy > 30%: 0% – доля системного времени в норме.
- free RAM < 5%: 100% в обоих экспериментах – свободной оперативной памяти постоянно менее 5%. Потенциальный риск нехватки памяти, хотя свопинг отсутствует.
- swap in/out: 0% – подкачка не используется.
- wa > 10%: 100% – CPU постоянно простаивает в ожидании IO более 10% времени.
- b превышение числа ядер CPU: 100% – количество процессов в состоянии uninterruptible sleep постоянно превышает 8 (ядер CPU).
Корреляционный анализ (ключевые отличия):
IO и bi (блоки чтения):
- Тантор: corr = 0.55 (высокая), R² = 0.31 (слабая модель).
- PGPRO: corr = 0.67 (высокая), R² = 0.45 (удовлетворительная). Связь IO с чтениями в PGPRO выражена сильнее и лучше объясняется моделью.
IO и bo (блоки записи):
- Оба: corr ~0.85-0.86, R² ~0.72-0.74 – сильная связь, хорошее качество.
Shared buffers hit ratio:
- Тантор: мин 96.09%, медиана 96.64%, макс 98.36%
- PGPRO: мин 96.29%, медиана 96.87%, макс 98.56% – у PGPRO hit ratio немного выше.
Корреляция скорости с прочитанными блоками:
- Тантор: corr = 0.58 (высокая), R² = 0.34 (слабая) – warning: производительности IO недостаточно.
- PGPRO: связь отсутствует (отрицательная или незначимая).
Корреляция hit ratio с прочитанными блоками:
- Тантор: отсутствует.
- PGPRO: corr = -0.73 (очень высокая отрицательная), R² = 0.53 – чем больше чтений с диска, тем ниже hit ratio (логичная обратная связь). В PGPRO кэширование работает предсказуемо.
Корреляция записанных блоков с bo:
- Тантор: corr = 0.88, R² = 0.77 (хорошая)
- PGPRO: corr = 0.90, R² = 0.80 (очень высокая) – сильная связь, указывает на необходимость настройки контрольных точек и bgwriter.
Корреляция dirty pages с b (процессы в uninterruptible sleep):
- Оба: corr ~0.99, R² ~0.98-0.99 – ALARM: размер грязных страниц практически линейно связан с блокировкой процессов в IO. Подтверждение системного IO bottleneck.
Корреляция dirty pages с bo:
- Оба: corr ~0.86-0.89, R² ~0.74-0.79 – ALARM: механизм обратной записи не успевает за генерацией dirty pages.
Корреляция dirty pages с sy (системное время):
- Оба: corr ~0.94-0.98, R² ~0.88-0.95 – ALARM: высокие накладные расходы ядра на управление памятью и IO.
Индекс приоритета корреляции (CPI):
В обоих экспериментах лидируют одни и те же пары: cs-in, cs-us, dirty-b, cs-sy, dirty-sy, dirty-bo. Значения CPI очень близки.
Итог по разделу:
- PGPRO демонстрирует более предсказуемую работу кэша (отрицательная корреляция hit с чтениями) и чуть лучший hit ratio.
- В Тантор операционная скорость заметно коррелирует с объёмом чтения с диска, что говорит о возможной нехватке кэширования или менее эффективном использовании буферов.
- Оба эксперимента страдают от тяжёлого IO-узкого места, подтверждённого множеством корреляций с dirty pages, b, wa и высокими накладными расходами ядра.
4. СРАВНЕНИЕ ДИАГРАММ ПАРЕТО ПО WAIT_EVENT_TYPE И QUERYID
Распределение по типам ожиданий:
- Тантор: IO – 99.84% (DataFileRead)
- PGPRO: IO – 99.94% (DataFileRead)
- Практически все ожидания приходятся на чтение файлов данных.
Топ запрос по ожиданиям IO:
- Тантор: queryid 8275902800498673318 (select scenario1()), calls = 16 816 525, waitings = 12 059 950 (85.04% от всех IO-ожиданий).
- PGPRO: queryid -1679588366130117659 (select scenario1()), calls = 16 583 534, waitings = 12 249 974 (85.21% от всех IO-ожиданий).
- В обоих случаях основной вклад вносит один и тот же запрос – вызов функции scenario1().
Список SQL-выражений идентичен:
select scenario1(), select scenario2(), select scenario3(). В Тантор дополнительно присутствует служебный запрос к pg_class.
Итог по разделу:
Нагрузка полностью определяется выполнением трёх сценариев, причём сценарий 1 генерирует более 85% всех IO-ожиданий. Целевая оптимизация должна быть направлена на этот запрос.
Детальный анализ – граничные значения и корреляции
Ожидания СУБД
- Доминирует тип IO, событие DataFileRead.
- Медианные ожидания: Тантор – 78 011, PGPRO – 79 032 (практически одинаково).
- Максимальные ожидания: Тантор – 226 349, PGPRO – 240 293 (немного выше у PGPRO, но и скорость выше).
Память и буферный кэш
- Shared buffers hit ratio: у PGPRO выше на ~0.2–0.3% (медиана 96.87% против 96.64%).
- Свободная RAM: в обоих экспериментах постоянно <5% – тревожный сигнал, но свопинг отсутствует. Возможно, это норма для выделенного сервера БД, где почти вся память занята кэшем.
- Корреляция hit с чтениями: в PGPRO сильная отрицательная (логично), в Тантор – отсутствует. Это может указывать на менее эффективное использование кэша в Тантор или на особенности сбора статистики.
Дисковая подсистема (I/O)
- Корреляция IO с bi/bo: сильная в обоих случаях, особенно с bo (запись). PGPRO немного лидирует по силе связи.
- Корреляция dirty pages с b и bo: очень сильная в обоих – явный признак того, что система не справляется с записью грязных страниц, процессы блокируются.
- wa > 10% в 100% времени – подтверждение постоянной высокой нагрузки на диск.
CPU и системные вызовы
- Корреляции cs с in, us, sy: очень высокие (R² > 0.95) в обоих экспериментах. Это нормально для многозадачной системы.
- В Тантор выше корреляция cs с sy (0.977 против 0.943), что может говорить о большем времени, тратимом ядром на переключение контекста.
- Падение idle CPU – закономерное следствие роста ожиданий.
Блокировки и ожидания LWLock
- Незначимы в обоих экспериментах (ВКО < 0.01). Блокировки не являются проблемой.
Анализ запросов (queryid)
- Главный потребитель – select scenario1() (около 85% всех IO-ожиданий). Именно его необходимо оптимизировать (индексы, переписывание, увеличение кэша).
Ключевые проблемы
Проблемы СУБД
- Критическая зависимость от IO: 99.9% ожиданий – DataFileRead. Скорость работы прямо пропорциональна объёму IO.
- Неэффективный запрос: scenario1() генерирует 85% всех ожиданий. Требуется анализ плана выполнения и оптимизация.
- Hit ratio высок, но не идеален (96–98%). Возможно, часть данных не помещается в shared_buffers.
- В Тантор дополнительно: операционная скорость коррелирует с чтениями с диска, что может означать недостаточный размер кэша или неоптимальное использование индексов.
Проблемы инфраструктуры
Системный IO bottleneck:
- Процессы массово блокируются в состоянии uninterruptible sleep (b >> ядер CPU в 100% времени).
- Высокий процент wa (всегда >10%).
- Размер dirty pages сильно коррелирует с b и bo – фоновые записи не успевают, процессы вынуждены ждать.
Высокие накладные расходы ядра: сильная корреляция dirty pages с sy (системное время) указывает на затраты CPU на управление памятью/IO.
Малый объём свободной RAM (<5%) – хотя свопинг не используется, это может приводить к вытеснению полезных страниц и дополнительным чтениям с диска.
Итоговый анализ влияния выбора конфигуратора на базовую производительность СУБД и инфраструктуры
Сходства:
- Оба эксперимента проведены на идентичном оборудовании с одинаковой тестовой нагрузкой (три сценария).
- Основной источник проблем – IO-подсистема, не справляющаяся с объёмом записи и чтения.
- Интегральный приоритет ожиданий (тип IO) и распределение по запросам практически идентичны.
Различия в производительности и эффективности:
Медианная скорость: PGPRO показал на 12% более высокую операционную скорость (431 390 против 383 994) при практически тех же медианных ожиданиях.
Качество кэширования:
- Hit ratio в PGPRO чуть выше.
- В PGPRO присутствует логичная отрицательная корреляция hit ratio с объёмом чтений с диска, что говорит о предсказуемой работе кэша. В Тантор эта связь отсутствует, что может указывать на менее эффективное использование shared_buffers или на другие факторы (например, включённый JIT).
Регрессионные модели: в PGPRO модели SPEED по времени и SPEED по WAITINGS имеют более высокие R², т.е. поведение более детерминировано.
Тренды vmstat: в Тантор обнаружен значимый рост очереди процессов на выполнение (procs r), что может быть следствием дополнительных накладных расходов (например, от JIT или менее агрессивного bgwriter). В PGPRO этот показатель стабилен.
Настройки bgwriter и контрольных точек: в PGPRO более агрессивный фоновый писатель (меньше delay, больше maxpages) и больший max_wal_size, что способствует более плавной записи и, возможно, снижает пиковые нагрузки. Это подтверждается чуть более сильной корреляцией записанных блоков с bo и лучшей моделью.
Вывод:
Конфигуратор PGPRO_TUNE обеспечил более высокую медианную производительность и лучшее использование буферного кэша при той же нагрузке. Его настройки (увеличенный shared_buffers, более агрессивный bgwriter, отключение JIT, больший max_wal_size) оказались эффективнее для данного сценария.
Тем не менее, фундаментальная проблема – недостаточная производительность дисковой подсистемы – остаётся нерешённой и требует либо модернизации hardware (более быстрые диски, NVMe), либо глубокой оптимизации запроса scenario1() для снижения объёма чтения с диска. Рекомендуется в первую очередь исследовать план выполнения проблемного запроса и рассмотреть возможность увеличения индексов или партиционирования.
Послесловие
Проведенное исследование подтвердило, что выбор конфигуратора СУБД оказывает статистически значимое влияние на операционную скорость PostgreSQL 17 в условиях OLTP-нагрузки: применение pgpro_tune обеспечило прирост медианной производительности на 12% по сравнению с рекомендациями Тантор Лабс. При этом в обоих экспериментах зафиксировано критическое узкое место дисковой подсистемы, о чем свидетельствуют доминирование IO-ожиданий (99,9%), устойчивый рост числа процессов в состоянии uninterruptible sleep и высокие корреляции между объемом «грязных» страниц и блокировками процессов. Выявлено, что 85% всех ожиданий приходится на единственный запрос (scenario1), что делает его оптимизацию первоочередной задачей. Полученные результаты могут служить основой для выработки рекомендаций по настройке PostgreSQL и модернизации инфраструктуры с целью устранения выявленных ограничений.