Иногда взрослые, вполне здравомыслящие люди ловят себя на простой мысли: нейросети уже в телефоне, в работе, в переписке, в сервисах — а уверенности, что всё это “понято и разложено по полочкам”, нет.

И это нормально. В International AI Safety Report 2026 как раз честно проговаривается неприятная штука: системы становятся сильнее быстро, а вот надёжные доказательства про риски и способы их сдерживать появляются медленно. Это и называется “evidence dilemma” — дилемма доказательств: рано вмешаться страшно (можно закрепить плохие меры), поздно вмешаться страшно (можно прозевать ущерб).
Отчёт ценен тем, что он не пытается сыграть в “всё под контролем” и не продаёт простых ответов. Он предлагает взрослую оптику: где именно растут возможности, почему тестам нельзя верить как раньше, и как строить управление рисками, когда мир меняется быстрее отчётности.
Рывок идёт не только от “больше модели”, а от того, как она думает после обучения
В дискуссии про ИИ часто звучит идея: чем больше модель и чем больше вычислений на обучение, тем она круче. Отчёт не спорит, но добавляет важную деталь: возможности заметно растут ещё и за счёт масштабирования вычислений на этапе ответа — когда модели дают больше вычислений во время ответа (по сути, больше времени на рассуждение). На графике ниже показано, что увеличение вычислений на этапе тестирования заметно улучшает результат на задачах, где нужно рассуждать, а не просто “узнать по памяти”.
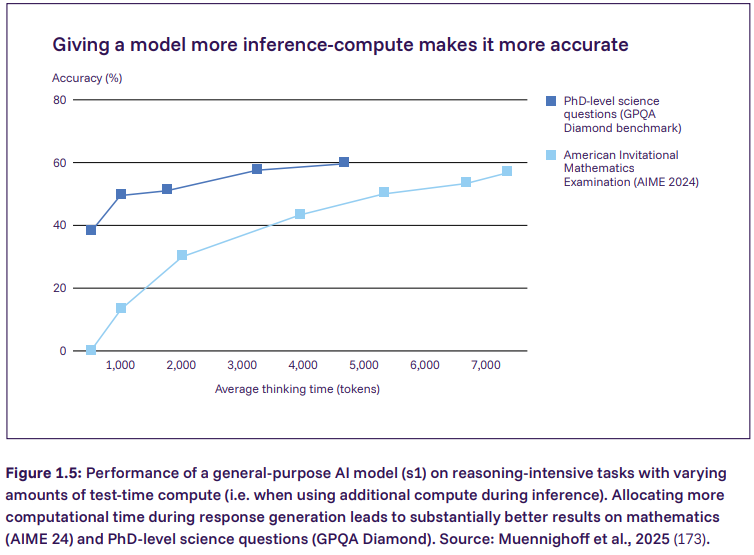
И здесь практический вывод очень приземлённый: “мощность ИИ” в реальном продукте — это не только то, что было в лаборатории, но и то, сколько вычислений ему дадут в проде. Значит, вопросы стоимости, скорости, лимитов, SLA и безопасности нельзя обсуждать отдельно от того, как именно система запускается и в каком режиме работает.
Разработка general-purpose AI — это цепочка стадий, и риски живут на каждой из них
Отчёт прямо фиксирует: general-purpose AI делается по стадиям — обучение, дообучение, интеграция, релиз, мониторинг и обновления; стадии могут идти итеративно и даже разными командами.
На схеме (1.2) это особенно полезно видно: риск-управление нельзя сводить к “проверим модель перед релизом”. Если контроль слабый на данных, если стимулы у команд разные, если мониторинг после релиза формальный — “узкое место” найдётся само. Ценность этой части отчёта в том, что она задаёт правильную рамку для корпоративных процессов: безопасность — это производственная цепочка, а не чек-лист в конце.
“Evaluation gap”: тесты перед релизом не предсказывают реальную пользу и реальный вред
Одна из самых сильных мыслей отчёта — наличие разрыва оценок: результаты на бенчмарках и предрелизных оценках не надёжно предсказывают, что будет в реальных условиях.
Причины там перечисляются спокойно и по делу: часть оценок устаревает, часть страдает от загрязнения обучающими данными, часть не отражает сложность “живых” задач, а ещё поведение моделей бывает “рваным” — в одном контексте блестяще, в другом странно и нестабильно.
Ценность вывода простая: если продукт строится на ИИ, то “сертификацией перед запуском” дело не заканчивается. Нужны наблюдаемость, метрики инцидентов, быстрый откат, регламент эскалаций и нормальный пост-мониторинг. Иначе компания будет жить в иллюзии безопасности, пока всё тихо.
Биориски: «реальное усиление возможностей» спорное, но контрольные задания уже подбираются к уровню экспертов
Отчёт аккуратно разводит два слоя. Первый: исследования про усиление возможностей (насколько ИИ реально повышает способность новичка делать опасные вещи) пока дают смешанные результаты и часто быстро устаревают.
Второй: контрольные задания и сравнения показывают рост результатов ведущих систем по задачам двойного назначения и близость к экспертному уровню на ряде направлений. Это видно на рисунке 2.8, где результаты привязаны к датам релизов и к экспертной базовой линии.
Ценность здесь не в нагнетании. Она в управленческом решении: даже если “в среднем” эффект не доказан, невозможность уверенно доказать отсутствие опасной способности становится отдельным риском (особенно на стыке науки, лабораторных протоколов и автоматизации). Это поддерживает идею “не ждать идеальных данных”, а строить защиту заранее и многослойно.
Скорость внедрения высокая, но польза и эффекты распределяются неравномерно
В отчёте показано, что ИИ внедряется быстро; есть сравнение темпов внедрения с интернетом и ПК в США (2.14).
И рядом важная оговорка: внедрение очень неравномерное — по странам, секторам и профессиям; а выигрыши чаще достаются более доходным когнитивным ролям.
Ценность для бизнеса и государства тут практическая: нельзя планировать изменения как “одну волну для всех”. Где-то будет рост эффективности и требований к навыкам, где-то почти ничего, а где-то появится раздражение и сопротивление, потому что “обещали пользу”, а её не видно.
Многослойная защита: один барьер не спасёт, а слои дают устойчивость
Самый взрослый и рабочий принцип отчёта — defence-in-depth, многослойная защита: технические меры, организационные решения, мониторинг после релиза и отдельный слой “societal resilience”. На диаграмме 3.5 прямо сказано: у каждого слоя есть изъяны, но вместе они дают гораздо более сильную защиту.
Ценность этого подхода — в его применимости. Он нормально ложится на реальные компании: можно распределять ответственность, строить контрольные точки, планировать затраты и не выдавать желаемое за действительное. И главное — перестать спорить, что важнее: техника или процесс. В отчёте ответ простой: важны оба, и ещё наблюдаемость.
Водяные знаки и «внедрение подсказок»: полезные технологии, но не «магическая кнопка»
В отчёте есть понятный блок про водяные знаки: водяные знаки и метаданные могут помочь различать AI-контент и поддерживать расследования (3.8).
Но рядом же — холодный душ по безопасности интеграций: атаки внедрения подсказок остаются успешными довольно часто. На рисунке 3.9 показано, что заявляемая доля успешных атак снижается со временем, но всё ещё «довольно высокая».
Ценность этого фрагмента в том, что он возвращает разговор на землю: если ИИ подключён к инструментам, документам, почте, внутренним базам, то безопасность — это не “попросить модель быть аккуратной”. Это архитектура доступа, изоляция, политика прав, журналирование, тесты атак и понятная реакция на инциденты.
Что в итоге дают эти выводы
Отчёт хорош тем, что помогает перестроить ожидания. Он не требует паники и не обещает спокойствия. Он предлагает понятную позицию: мир ИИ — это быстрые изменения + запаздывающие доказательства, и в таком мире выигрывают те, кто умеет управлять неопределённостью: строить процессы по стадиям (Рис. 1.2), признавать разрыв оценок, вкладываться в слои защиты (Рис. 3.5), и не закрывать глаза на “неприятные” области вроде биорисков и атак внедрения подсказок.
Если говорить совсем по-человечески, без пафоса: это отчёт про то, как не делать вид, что всё ясно, и при этом не тормозить развитие. А просто делать работу по-взрослому — с проверками, наблюдением, ответственностью и нормальными правилами игры.