
Каждый раз, когда вы открываете приложение, расплачиваетесь картой или просто проходите мимо камеры в метро, вы оставляете цифровой след. В одиночку этот «след» почти ничего не значит, но когда такие данные собираются от миллионов людей ежесекундно, они превращаются в Big Data — один из самых мощных инструментов современности.
В этой статье мы не только расскажем вам о Big Data, об их особенностях и видах, но и поведаем, откуда приходят большие данные, а главное где и зачем они используются на реальных примерах.
Что такое Big Data?
Big Data, или большие данные, — это не просто «очень много информации». Это массивы разнородных данных такого объема и сложности, что обычный компьютер или привычная таблица Excel с ними не справятся. Представьте себе попытку сосчитать все капли в океане с помощью кухонного мерного стакана. Здесь нужны совершенно другие технологии — распределенные системы, облачные хранилища и сложные алгоритмы, которые могут не только обрабатывать гигабайты информации в минуту, но и находить смысл в хаосе.
Активное развитие Big Data началось в середине 2000-х годов, когда крупные интернет-сервисы столкнулись с огромным количеством пользовательского контента. Появились новые инструменты хранения и обработки, среди которых одной из первых масштабных платформ стала Apache Hadoop. Позже к ней добавились другие решения для распределенных вычислений и потоковой обработки данных.
*Apache Hadoop — это программная платформа для хранения и обработки очень больших объемов данных на множестве обычных серверов, объединенных в кластер. Вместо одного мощного компьютера Hadoop распределяет данные и задачи между десятками или сотнями машин: если одна выходит из строя, остальные продолжают работать. В ее основе лежат две ключевые идеи — распределенное хранение файлов и параллельная обработка данных по частям, что позволяет компаниям анализировать терабайты и петабайты информации быстрее и дешевле, чем при использовании традиционных систем.
Сегодня Big Data — это основа подхода data-driven, когда решения принимаются не на основе предположений, а на основе анализа фактов.
Data-driven — это подход к управлению и развитию бизнеса, при котором решения принимаются на основе анализа реальных данных, а не интуиции или личного опыта. Компания собирает информацию о клиентах, продажах, процессах и результатах, затем анализирует ее и только после этого запускает новые продукты, маркетинговые кампании или изменения в стратегии. Такой подход снижает риски, делает прогнозы точнее и позволяет быстрее реагировать на изменения рынка.
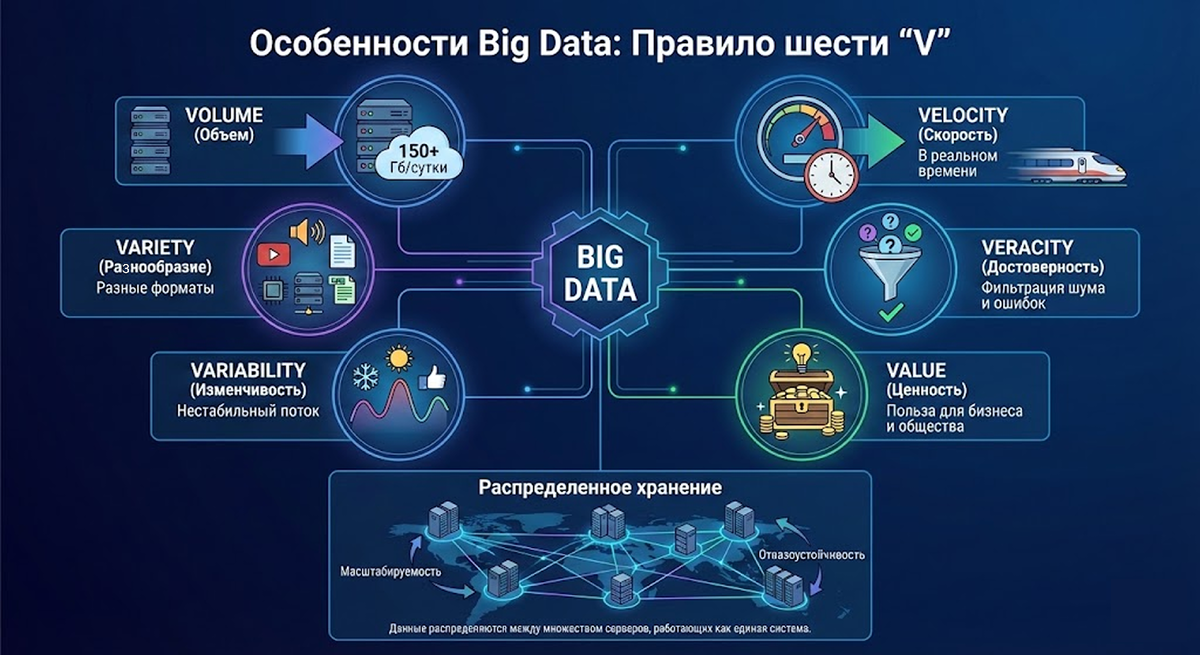
Особенности Big Data
Чтобы понять, где заканчиваются просто «данные» и начинается «Big Data», эксперты используют правило шести «V»:
- Volume (Объем): Это базовый признак. Считается, что если данных поступает более 150 Гб в сутки, это уже «биг дата».
- Velocity (Скорость): Данные не просто копятся, они прибывают с огромной скоростью. Их нужно обрабатывать в режиме реального времени, иначе они потеряют актуальность (например, данные о пробках через час уже никому не нужны).
- Variety (Разнообразие): Это не только цифры. Это видео, аудио, текстовые посты, данные с датчиков и логи серверов. Все это имеет разный формат.
- Veracity (Достоверность): Среди огромного потока информации много «шума» и ошибок. Умение отфильтровать правду от искажений — критически важная черта.
- Variability (Изменчивость): Поток данных нестабилен. Он зависит от времени года, погоды или хайпа в соцсетях.
- Value (Ценность): Самый важный пункт. Данные собираются не ради процесса, а ради пользы — будь то маркетинговые кампании или спасение жизней.
Еще одна важная особенность Big Data — данные не хранятся в одном месте, а распределяются между множеством серверов и дата-центров, которые работают как единая система. Благодаря этому объем хранения можно увеличивать по мере необходимости, а сбой одного узла не останавливает работу всей системы.
Как отличить большие данные от обычных?
Самый простой способ понять разницу — посмотреть на примеры. Обычные данные — это, например, таблица в Excel со списком сотрудников компании и их зарплатами. Большие данные — это записи всех звонков огромного колл-центра за месяц, включая длительность разговора, время ожидания, тему обращения, интонацию клиента, частоту упоминания конкретных проблем, соблюдение скриптов и тд.
Еще пример: обычные данные — расписание автобусов по области. Большие данные — где именно сейчас находятся тысячи такси, сколько людей ждут машину в этом районе и как меняется спрос каждые пять минут. Если информация поступает из множества источников одновременно, постоянно обновляется, занимает огромные объемы и требует специальных технологий для обработки — это уже большие данные.
Виды больших данных
Большие данные бывают трех основных типов в зависимости от степени упорядоченности.
- Структурированные данные — это то, что уже разложено по полочкам (базы данных, где у каждого поля есть свое место).
- Полуструктурированные (частично структурированные) данные имеют некие маркеры или теги, которые помогают их опознать (например, письма в электронной почте, где есть отправитель, тема и время, но само содержание текста может быть любым).
- Неструктурированные данные — это самый сложный и объемный пласт (около 80% всей информации в мире). Сюда входят фотографии, видео, аудиозаписи, сообщения в социальных сетях, записи звонков и потоковое видео с камер. Программе очень сложно «понять» содержание картинки или смысл гневного отзыва без специальной обработки нейросетями.
Этапы работы с большими данными
Работа с Big Data — это не разовое действие, а сложный конвейер, который состоит из нескольких ключевых стадий:
- Сбор (Ingestion): Данные извлекаются из источников. Для этого используются инструменты вроде Apache Kafka, которые умеют «ловить» миллионы событий в секунду.
- Очистка (Data Cleaning): Удаление дублей, исправление ошибок и приведение информации к единому стандарту. Без этого этапа анализ превратится в «мусор на входе — мусор на выходе».
- Хранение: Для Big Data не подходят обычные диски. Используются Data Lakes («озера данных»), куда информация стекается в сыром виде, или Data Warehouses (DWH) — структурированные хранилища для бизнес-отчетов.
- Обработка и анализ: Здесь в игру вступают такие инструменты, как Hadoop (для распределенного хранения) и Apache Spark (для мгновенных вычислений). Данные дробятся на части и обрабатываются на сотнях серверов одновременно.
- Визуализация: Финальный этап, когда сухие цифры превращаются в красивые графики и понятные выводы в системах вроде Power BI или Tableau.
Где хранятся большие данные и какие ресурсы нужны?
Большие данные хранятся в распределенных системах — это тысячи и десятки тысяч физических серверов, расположенных в крупных дата-центрах по всему миру. Почти всегда компании, использующие Big Data, прибегают к облачным платформам, потому что самостоятельно построить и содержать такую инфраструктуру невероятно дорого и сложно. Облако — это не «воздух», а очень большое, профессионально организованное железо, которым управляет провайдер (IT-гиганты вроде Yandex Cloud, Amazon Web Services, Google Cloud и другие). Когда объем данных резко растет или нужна срочная обработка, провайдер за секунды или минуты добавляет дополнительные серверы из своего общего пула — именно поэтому облако так удобно для работы с большими данными. Для всего этого требуются колоссальные вычислительные мощности, быстрые диски, гигантские объемы оперативной памяти, бесперебойное электричество и мощные системы охлаждения. Крупные технологические корпорации, такие как Google, Amazon и Яндекс, потребляют столько электроэнергии для своих дата-центров, что ее объемы сопоставимы с энергопотреблением небольших городов, поэтому в мире уже рассматриваются проекты строительства собственных электростанций, включая атомные, для обеспечения растущих вычислительных нагрузок.
Тотальный сбор: откуда приходят данные?
Мы живем в эпоху, когда данные собирает буквально все, что включено в розетку или имеет аккумулятор. Вот список основных источников, из которых поступает информация:
- Социальные сети и медиа: Ваши лайки, репосты, комментарии, время просмотра видео на YouTube или TikTok, поисковые запросы.
- Мобильные приложения: Геолокация (где вы находитесь), фитнес-показатели (пульс, шаги), список контактов и история покупок.
- Городская инфраструктура: Камеры в метро и общественных местах с функцией распознавания лиц, датчики движения, системы учета проезда.
- Связь и интернет: Публичные точки Wi-Fi (фиксируют ваше устройство и его перемещения), логи интернет-провайдеров и сотовых операторов.
- Интернет вещей (IoT): Умные чайники, холодильники, промышленные станки на заводах, метеостанции и спутники.
- Транзакционные данные: Оплата картой в магазине, переводы в онлайн-банке, использование карт лояльности в супермаркетах.
- Медицина: Результаты МРТ, анализы крови, цифровые медицинские карты.
По сути, если что-то можно измерить или зафиксировать в цифровом виде — это уже потенциальный источник больших данных.
Где и зачем используют Big Data: от кофейни до большой политики
Big Data давно вышла за пределы IT-лабораторий и сегодня управляет реальностью.
В бизнесе это помогает, например, выбрать идеальное место для открытия нового кафе. Анализируются «тепловые карты» перемещения людей (по данным мобильных операторов), количество чеков в соседних заведениях и даже демография района. Если алгоритм видит, что в этом месте по утрам проходит 5000 платежеспособных любителей латте, риск прогореть значительно ниже.
В политике большие данные позволяют предсказывать итоги голосования с поразительной точностью. Анализируя настроения в соцсетях, лайки и комментарии, политтехнологи понимают, какие темы волнуют людей в конкретном городе, и адаптируют лозунги кандидатов под эти ожидания.
В экономике Big Data помогает прогнозировать курсы валют и котировки акций, анализируя не только графики, но и новости, твиты крупных бизнесменов и даже отчеты о погоде (которые влияют на урожай и цены на продукты).
В социальной сфере это незаменимо для создания «умных городов»: алгоритмы регулируют работу светофоров для борьбы с пробками, предсказывают районы с потенциально высокой преступностью и помогают врачам выявлять эпидемии на ранних стадиях, замечая всплеск запросов в аптеках по определенным лекарствам.
Великая сила примера: Big Data в истории
Теория звучит красиво, но именно реальные кейсы показывают, как большие данные меняют судьбы стран и корпораций.
В политике самым громким примером стал 2012 год, когда команда Барака Обамы использовала Big Data для победы. Они создали систему «Dash», которая собирала данные о миллионах избирателей: какие шоу они смотрят, что покупают, в каких группах в соцсетях состоят. Это позволило делать «микротаргетинг» — рассылать разные письма разным людям. Одному обещали реформу образования, другому — поддержку малого бизнеса, попадая точно в цель. Позже Дональд Трамп и компания Cambridge Analytica использовали похожий подход, анализируя психотипы людей по их лайкам в Facebook, чтобы показывать им максимально убедительную политическую рекламу. Этот кейс стал поводом для глобальных дискуссий о регулировании персональных данных.
В бизнесе классикой стал кейс торговой сети Target. Анализируя покупки, алгоритм научился определять беременность покупательниц на ранних сроках. Однажды отец школьницы устроил скандал в магазине, потому что его дочери прислали купоны на одежду для младенцев. Позже выяснилось, что молодая девушка действительно была беременна, а алгоритм узнал об этом раньше ее семьи, заметив, что она перешла на покупку лосьонов без запаха и витаминов с магнием.
Крупные бренды используют данные для создания хитов. Например, Coca-Cola создала новый вкус «Cherry Sprite» после того, как проанализировала данные с интерактивных автоматов самообслуживания, где люди сами смешивали напитки. Компания увидела, какая комбинация популярнее всего, и выпустила готовый продукт, опираясь на оценке больших данных. Кстати, именные бутылки также были выпущены благодаря анализу Big Data. Это увеличило продажи на 2% в США и укрепило лояльность к бренду Coca-Cola.
Компания Netflix использует Big Data для анализа предпочтений зрителей. На основе просмотров, пауз, перемоток и оценок сервис принимает решения о создании новых проектов. Сериал «House of Cards» был запущен в том числе благодаря анализу данных, показавших высокий интерес аудитории к определенному жанру, режиссеру и актеру.
Для государства и социальной сферы Big Data стала спасением. В Нью-Йорке система PredPol анализирует данные о прошлых преступлениях, погоде и праздниках, чтобы предсказать «горячие точки», куда полиции стоит отправить патруль заранее. Это позволило снизить преступность на десятки процентов. В медицине данные помогают отслеживать распространение гриппа по поисковым запросам в Google: если в районе Х люди стали чаще искать «лекарство от температуры», врачи узнают об эпидемии за 2 недели до официальных отчетов из больниц.
Важно понимать, что большие данные не принимают решения за людей. Они становятся инструментом поддержки — помогают выявить закономерности, снизить риски и оценить потенциал идей, но окончательные решения о запуске продукта, политической кампании или социальной программы принимаются экспертами с учетом профессионального опыта, контекста и целей, которых необходимо достичь.
Плюсы и минусы больших данных
Как и любой мощный инструмент, Big Data имеет свои сильные и слабые стороны. К неоспоримым плюсам можно отнести невероятную точность прогнозов. Мы перестаем гадать и начинаем знать. Компании лучше понимают клиентов, быстрее реагируют на изменения, создают более удобные и полезные продукты, экономят ресурсы и иногда даже спасают жизни.
Однако есть и серьезные минусы. Первый — это сложность и дороговизна: не каждая компания может позволить себе штат дата-сайентистов, большие счета за облако и огромное потребление электричества. Второй — проблема приватности. В мире Big Data понятие личной жизни размывается: алгоритмы порой знают о нас больше, чем мы сами. И, наконец, безопасность: чем больше ценной информации собрано в одном месте, тем выше риск утечки и тем строже требования законодательства к защите персональной информации.
Заключение
Big Data — это не технология будущего, а реальность, в которой мы уже живем. От маршрута такси и рекомендаций в стриминговом сервисе до выбора места для открытия бизнеса или разработки социальной программы — за многими решениями сегодня стоит анализ огромных массивов данных. А станет ли это безусловным благом или источником новых рисков — вопрос остается открытым.
Подписывайтесь на нас в социальных сетях — там еще много интересного.