Когда наш ИИ-эксперт по охране труда начал путать инструкции и выдавать опасные советы, мы поняли: дальше так нельзя. Пришлось полностью пересмотреть подход к данным, поиску и архитектуре. Спойлер: помогли иерархические чанки и LangGraph.
Что пошло не так
На старте мы, как и многие, собрали быстрый MVP на LangChain: ChromaDB, простая нарезка текста, LLM-реранкер. На десятке документов бот отвечал блестяще. Но когда база разрослась до тысяч файлов, система превратилась в «чёрный ящик»:
- Точность упала — векторный поиск тонул в шуме.
- Задержки выросли до 15–20 секунд из‑за LLM-реранкера.
- Юридическая экспертиза страдала — чанки обрывались на полуслове, терялась связь с заголовками.
С чего начали спасение
Первым делом переписали ETL. Отказались от тупой нарезки по символам — теперь каждый чанк «знает», из какого он раздела и пункта. Внедрили дедупликацию и перенесли базу в Qdrant (отдельный сервис, батчевая загрузка, метаданные). Это дало +40% точности при поиске шаблонов за счёт учёта названий файлов.
Гибридный поиск + Query Expansion — добавили BM25 к векторам и научились переформулировать запросы. Например, на «нужны ли каски на крыше» система теперь ищет и «СИЗ при работе на высоте».
Реранкер больше не тормоз
Заменили «тяжёлую» LLM на специализированную модель BAAI/bge-reranker-v2-m3 — скорость выросла в разы, а точность сортировки чанков стала стабильной. Для финальной проверки оставили лёгкую Gemma 3:12B, но только на топ‑3 кандидатах.
Логика на графах
Обычные цепочки LangChain перестали справляться — перешли на LangGraph. Теперь у нас есть узлы:
- retrieve — гибридный поиск,
- grade_documents — отсев «шума»,
- generate — генерация ответа Gemma 3:27B.
Если поиск ничего не дал, система не извиняется, а переформулирует запрос и ищет снова. Реальная память диалога хранится в PostgreSQL.
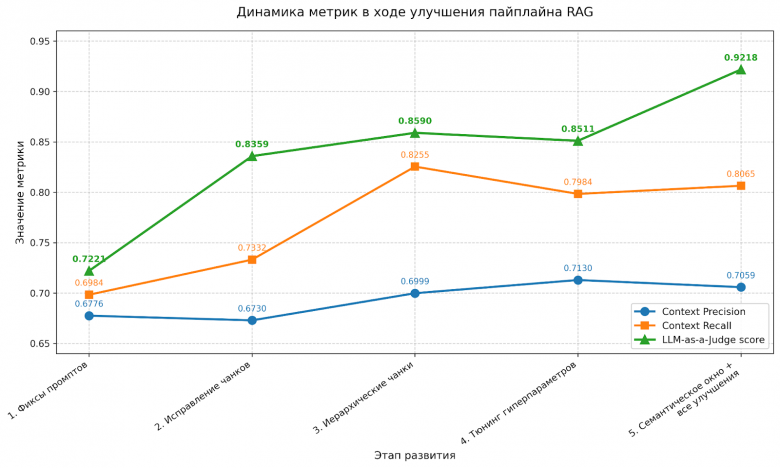
Цифры говорят сами за себя
Мы начали замерять качество поздно, но финальные тесты впечатляют:
- Иерархические чанки подняли оценку LLM-судьи с 0.72 до 0.83.
- А семантическое окно (LLM сама решает, где заканчивается чанк) в сочетании со всеми улучшениями дало 0.92 балла! Да, Precision немного просел, но ответы стали максимально полными и юридически выверенными.
Итог: чек-лист для смелых
Хотите такой же результат? Запомните:
- Данные важнее моделей — настройте чанкинг и метаданные.
- Гибридный поиск обязателен — векторы без BM25 не найдут точный номер приказа.
- Реранкер берите специальный — не мучайте LLM скорингом.
- Графы вместо линеек — LangGraph спасает, когда нужны циклы.
🚀 Хотите глубже?
В полной версии статьи на Хабре — схемы, графики, таблицы метрик и куски кода.
А попробовать нашего ИИ-эксперта «Марк» можно прямо сейчас в Telegram: @AI_assistantOT_bot
Нужен готовый ассистент под ваши задачи? Заходите на наш сайт: duc-technologies.ru/aiassistant