Материал подготовлен для TG-канала «Поговорим о стратегии» с помощью естественного интеллекта.
Февраль 2026 года.
Павел Милосердов (с)
TG-канал «Поговорим о стратегии» (с)
Что такое ИИ (AI)?
Искусственный интеллект (Artificial Intelligence) – это набор инструментов, позволяющих решать задачи, требующие человеческого интеллекта: анализ данных, распознавание образов и речи, понимание языка, обучение и принятие решений.
С точки зрения круга решаемых задач на сегодня существует только Узкий искусственный интеллект (ANI, Artificial Narrow Intelligence). Его модели предназначены для решения конкретных задач: ведение диалога, распознавание изображений и тому подобное. Даже самые продвинутые языковые модели вроде DeepSeek или ChatGPT пока относятся к узкому ИИ: они хорошо решают отдельные задачи, но не обладают общим пониманием мира. Хотя некоторые исследователи отмечают, что языковые модели обладают признаками настоящего ИИ.
В перспективе нас ожидают:
- Общий искусственный интеллект (AGI, Artificial General Intelligence) — это гипотетический тип ИИ, способный решать широкий круг задач на уровне человека. Такой ИИ мог бы выполнять разные виды работы, осваивать новые навыки без дополнительного переобучения, управлять техникой, писать тексты и общаться с людьми. Некоторые исследователи предполагают, что для этого AGI потребуется способность самостоятельно ставить цели и адаптировать своё поведение в новых ситуациях, однако единого мнения по этому вопросу нет. На сегодняшний день общий искусственный интеллект не создан и остаётся предметом научных исследований и дискуссий.
- Искусственный суперинтеллект (ASI, Artificial Superintelligence) — это гипотетическая форма ИИ, которая превосходит человека по интеллектуальным способностям во всех или почти всех областях. Предполагается, что такой ИИ смог бы решать научные, технические и творческие задачи значительно эффективнее людей.
История развития ИИ
https://skillbox.ru/media/code/iskusstvennyi-intellekt/
1950–1970-й: Алан Тьюринг и появление термина
История искусственного интеллекта начинается в 1950 году с работы Алана Тьюринга «Вычислительные машины и разум». В ней он задаётся вопросом: могут ли машины мыслить?
Для этого он предложил тест: если машина с текстовым интерфейсом сможет обмануть человека, заставив его поверить, что он говорит с другим человеком, — значит, мы имеем право называть её разумной.
В 1956 году в США прошла Дартмутская конференция, среди участников которой были Клод Шеннон, один из создателей теории информации и основоположник цифровой связи, и Джон Маккарти, исследователь в области компьютерных наук. Они предложили ввести в использование термин «искусственный интеллект».
После этого область ИИ стала быстро развиваться. Например, в 1966 году появился чат-бот Eliza, который задумывался как психотерапевт, способный слушать пользователя, анализировать сказанное и задавать уточняющие вопросы.
В период с 1966 по 1972 год Центр искусственного интеллекта при Стэнфордском исследовательском институте разработал Shakey — мобильного робота, оснащённого датчиками и телевизионной камерой. С их помощью Shakey ориентировался и перемещался в различных условиях. Несмотря на странный внешний вид, он стал важной вехой в робототехнике.
1971–1980-й: застой искусственного интеллекта
К началу 1980-х стало ясно, что убедительная имитация разумного поведения человека ещё не означает настоящего мышления. Эту проблему чётко сформулировал философ Джон Сёрл в мысленном эксперименте «Китайская комната», показав, что система может правильно отвечать, не понимая смысла своих действий. Сёрл показал, что имитация разумного поведения не равна пониманию.
В 1973 году математик Майкл Джеймс Лайтхилл выпустил отчёт, в котором дал крайне сдержанную оценку развитию технологии, указав, что «ни в одной области ИИ достигнутые на тот момент результаты не оказали того значимого влияния, которое ранее обещалось». Отчёт Лайтхилла зафиксировал разрыв между обещаниями исследователей и реальными результатами — и стал формальным поводом сократить финансирование ИИ.
1981–2000-й: ИИ наносит ответный удар
Начавшаяся в 1970-х годах «зима ИИ» растянулась почти на два десятилетия. По-настоящему серьёзные инвестиции в исследования и разработки вернулись лишь к концу 1990-х.
При этом отдельные значимые эксперименты появлялись и раньше. В 1986 году немецкий учёный Эрнст Дикманн представил один из первых самоуправляемых автомобилей. Это был фургон Mercedes, оснащённый компьютерной системой и датчиками для анализа окружающей среды. Машина могла самостоятельно передвигаться по дорогам, однако только в условиях отсутствия других автомобилей и пешеходов.
Настоящим символом возвращения ИИ в публичное пространство стал шахматный поединок между человеком и машиной. В 1996 году компания IBM выставила свою систему Deep Blue против действующего чемпиона мира по шахматам Гарри Каспарова. Матч из шести партий завершился победой человека: ИИ удалось выиграть лишь одну партию. Однако уже в 1997 году, в реванше, Deep Blue одержал итоговую победу, завершив решающую партию всего за 19 ходов.
2001–2019-й: рост ИИ
В начале 2000-х искусственный интеллект стал выходить из лабораторий и работать в реальных условиях. Одним из символов этого периода стал робот Kismet — проект Лаборатории искусственного интеллекта MIT под руководством Синтии Бризил. Оснащённый датчиками, микрофоном и программной моделью эмоциональных процессов человека, Kismet мог интерпретировать эмоции и воспроизводить их, создавая впечатление живого взаимодействия.
В 2004 году NASA отправил на Марс два марсохода — Spirit и Opportunity. Оба аппарата были оснащены элементами ИИ, позволяющими им самостоятельно передвигаться по сложному каменистому рельефу и принимать решения в реальном времени, не полагаясь постоянно на команды с Земли. Эти проекты показали, что ИИ может работать вне строго контролируемых условий и решать практические задачи.
После успеха Deep Blue компания IBM в 2011 году представила суперкомпьютер — IBM Watson. Широкой аудитории он стал известен благодаря популярной американской телевикторине Jeopardy. IBM Watson установил новый рекорд по заработанной за программу сумме и значительно превзошёл соперников-людей по числу правильных ответов.
В том же году Apple представила виртуального ассистента Siri, а в 2014-м Amazon выпустил собственного виртуального помощника — Alexa. Обе системы использовали обработку естественного языка, понимая голосовые запросы и отвечая на них, что сделало ИИ привычным для пользователей повседневной техники.
Ключевым сдвигом в области ИИ стало появление нейросети AlexNet в 2012 году. Она выиграла конкурс по распознаванию изображений ImageNet и показала радикальное улучшение качества по сравнению с предыдущими подходами: по точности модель на 40% обгоняла ближайшего конкурента. Этот успех доказал, что при достаточном объёме данных и вычислительных ресурсов нейросети могут значительно превосходить традиционные алгоритмы.
Следующий крупный сдвиг произошёл в 2017 году, когда инженеры Google опубликовали статью Attention Is All You Need и представили архитектуру Transformer. Разработчики научили модель анализировать текст и делать на его основе выводы.
На базе «трансформеров» в последующие годы появились системы, способные не только распознавать информацию, но и генерировать связный текст, код и другие формы контента. Именно они стали основой для популярных моделей: GPT-4, LLama и других.
2020-й — настоящее время: эра генеративного ИИ
Последние годы характеризуются стремительным ростом интереса к генеративному ИИ — системам, создающим тексты, изображения и видео по текстовым запросам (промптам). В отличие от ранних решений, генеративные модели обучаются на огромных массивах данных и продолжают совершенствоваться с накоплением нового опыта, что расширяет их возможности далеко за рамки заранее заданных сценариев.
В 2020 году OpenAI представила модели GPT-3 и GPT-3.5 Turbo с 175 миллиардами параметров. Тексты, которые они генерировали, было сложно отличить от написанных человеком. На их основе в 2022 году появился чат-бот ChatGPT, ставший ключевым драйвером популярности генеративного ИИ и открывшим новую эпоху его практического использования.
Ключевая особенность эпохи, которая продолжается и сейчас, — демократизация ИИ. Продукты вроде ChatGPT или Claude сделали технологии, ранее доступные лишь исследовательским центрам и корпорациям, массовыми.
Генеративный ИИ начал трансформировать рынок труда, образование, медиа и разработку ПО, взяв на себя решение многих задач из этих сфер. Например, создание контента для социальных сетей или написание программного кода. Пока что это получается не идеально, но подобные модели появились совсем недавно, поэтому делать выводы о них рано.
Что «под капотом»?
Нейросеть — это программа, которая обучается на данных и примерах. Название связано с тем, что её архитектура напоминает структуру человеческого мозга: она состоит из «нейронов», соединённых между собой связями. «Нейроны» обычно организованы в слои, которые последовательно обрабатывают информацию.
- Машинное обучение (Machine Learning)– узкий круг задач, простая архитектура.
- Глубокое обучение (Deep Learning) – большие объемы данных и решение сложных задач.
- Сверточные нейронные сети (Convolutional Neural Networks, CNN) — специально разработаны для обработки изображений, видео и других визуальных данных. Включают слои свертки, которые выделяют особенности изображений (например, края, текстуры). Применяются для распознавания лиц, диагностики медицинских изображений, анализа видео.
- Рекуррентные нейронные сети (Recurrent Neural Networks, RNN) — используются для работы с последовательными данными, такими как текст, аудио, временные ряды. Эти сети имеют циклические связи, что позволяет учитывать информацию из предыдущих шагов.
- LSTM (Long Short-Term Memory) — является усовершенствованной версией RNN. LSTM справляется с долгосрочными зависимостями в данных, которые традиционные RNN не могут эффективно обрабатывать из-за проблемы затухания или взрывного градиента.
- Генеративные модели (Generative Adversarial Networks, GAN) — модели, которые могут генерировать новые данные, похожие на те, что были использованы для их обучения. Состоят из двух компонентов: генератора, создающего новые данные, и дискриминатора, оценивающего их правдоподобие. Они не выбирают ответ из готовых вариантов, а пошагово формируют новый результат: текст, изображение или звук. Во время обучения такие модели учатся угадывать следующий элемент — слово, пиксель или ноту — на основе большого количества примеров из обучающих датасетов. Это позволяет создавать связный и реалистичный контент по запросу пользователя. К таким моделям относятся ChatGPT, Midjourney и их аналоги.
- Трансформеры (Transformers) — архитектура, которая революционизировала обработку текста. Трансформеры позволяют работать с текстами и последовательностями в параллельном режиме, что ускоряет обучение. Примеры таких моделей — BERT и GPT, применяемые в чат-ботах, переводчиках и поисковых системах.
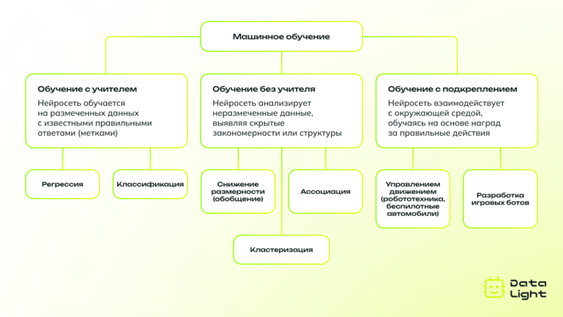
- Обучение с учителем — это наиболее распространенный способ обучения нейросетей. В этом случае нейросеть обучается на заранее подготовленных данных, которые содержат как входные данные, так и правильные ответы (метки). Задача нейросети — научиться распознавать закономерности между входными данными и их метками, чтобы на основе новых, ранее не встречавшихся данных, она могла сделать правильные предсказания. Требуются большие объемы размеченных данных. Применяется в задачах классификации, регрессии, распознавания речи и текста.
- Обучение без учителя — это метод, при котором нейросеть обучается на данных, не имеющих меток. В этом случае задача нейросети — самостоятельно выделить скрытые закономерности и структуру в данных. Обычно этот метод используется для кластеризации, снижения размерности или поиска скрытых шаблонов в данных.
- Обучение с подкреплением — это метод, при котором нейросеть учится на основе взаимодействия с окружающей средой. В отличие от обучения с учителем и без учителя, где данные фиксированы, в обучении с подкреплением нейросеть принимает решения и получает «награды» или «штрафы» за свои действия.
- Алгоритм обратного распространения ошибки (Backpropagation) — это основной алгоритм обучения нейросети, который позволяет корректировать ее внутренние параметры (веса) на основе допущенных ошибок. Благодаря этому алгоритму нейросеть может постепенно учиться выполнять задачи все лучше и точнее.
- Алгоритм упругого распространения (Resilient Propagation, RPROP) — это усовершенствованный метод обучения нейросетей, разработанный для устранения недостатков традиционного метода обратного распространения ошибки.
Ключевая идея RPROP заключается в том, чтобы учитывать только направление изменения (знак градиента ошибки), игнорируя его величину. Это позволяет избежать проблем, связанных с очень большими или слишком малыми значениями градиента, которые могут замедлять или дестабилизировать обучение. - Генетический алгоритм — это метод, который помогает нейросети находить лучшие решения, используя принципы, похожие на те, что действуют в природе. Он работает по аналогии с процессами естественного отбора: лучшие решения «выживают», а остальные отбрасываются или изменяются, чтобы постепенно улучшить результаты работы нейросети.