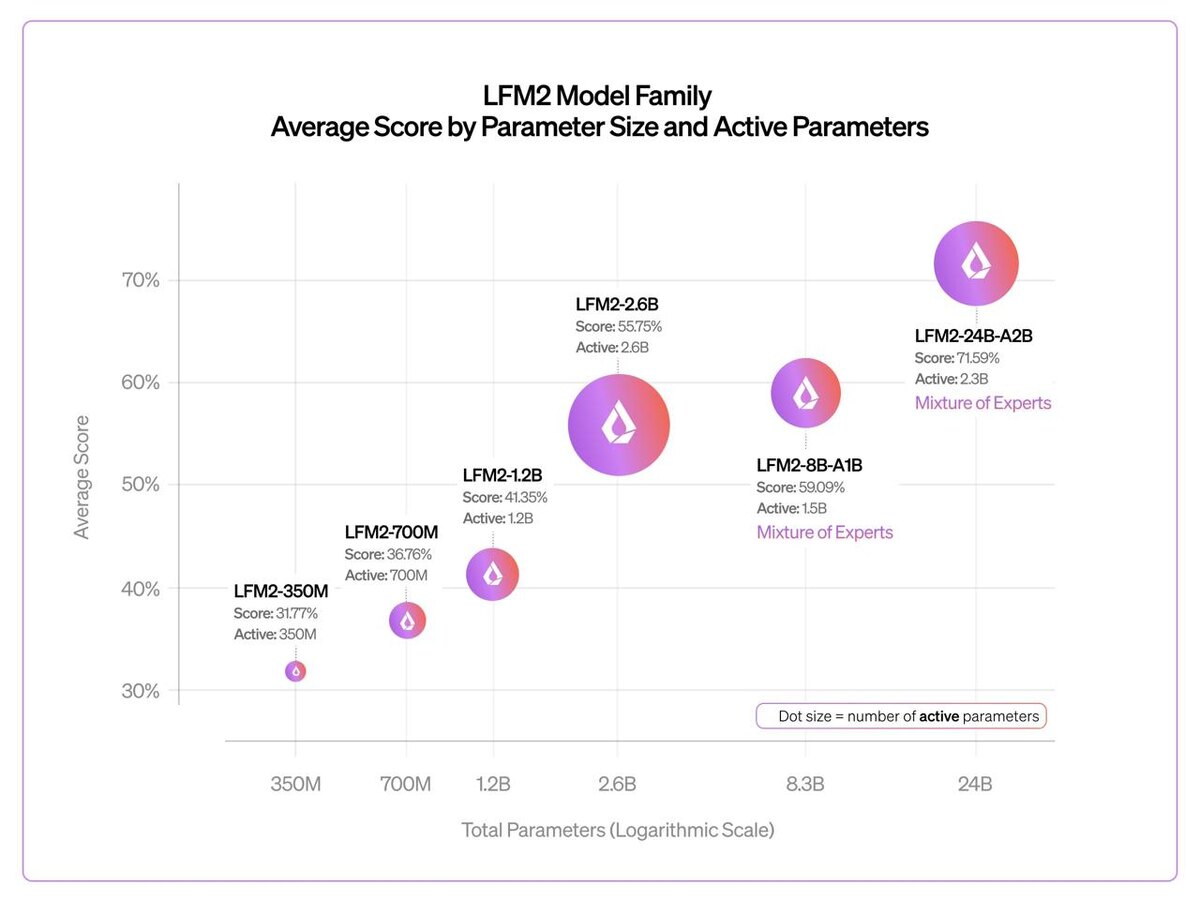
Liquid AI представила свою крупнейшую модель - LFM2-24B-A2B 🐘
- 24 млрд параметров всего
- активны только 2,3 млрд на каждый токен
- построена на гибридной, аппаратно-оптимизированной архитектуре LFM2
Модель сочетает быстрый и экономичный дизайн LFM2 с архитектурой Mixture of Experts (MoE), благодаря чему при работе задействуется лишь небольшая часть параметров.
Результат:
- высокая энергоэффективность
- быстрая работа на edge-устройствах
- предсказуемый лог-линейный рост качества
- полный запуск в пределах 32 ГБ памяти
С выходом этой версии линейка LFM2 теперь охватывает почти два порядка масштаба — от 350 млн до 24 млрд параметров, при этом каждое увеличение размера даёт стабильный рост качества на стандартных бенчмарках.
Модель специально оптимизирована так, чтобы помещаться в 32 ГБ RAM — её можно запускать на потребительских ноутбуках и рабочих станциях.
Стратегия масштабирования:
- увеличить глубину сети (с 24 до 40 слоёв)
- увеличить число экспертов (с 32 до 64 в каждом MoE-блоке)
- сохранить компактный активный путь вычислений
Итог — общее число параметров выросло в 3 раза, но вычислительная нагрузка осталась контролируемой.
LFM2-24B-A2B выпущена как instruct-модель (без трасс reasoning) и показывает лог-линейный рост качества на задачах:
GPQA Diamond, MMLU-Pro, IFEval, IFBench, GSM8K, MATH-500.
Модель получила поддержку «с первого дня» в:
- llama.cpp
- vLLM
- SGLang
Доступны квантованные версии (GGUF), работающие на CPU и GPU.
Например:
- на CPU (Ryzen AI, Q4_K_M) — около 93 токенов/с при контексте 8K
- высокий throughput и на GPU (H100)
Главный вывод: архитектура LFM2 демонстрирует предсказуемое масштабирование без «потолка качества» у малых моделей.
https://huggingface.co/LiquidAI/LFM2-24B-A2B-GGUF