🧠 Google придумали способ сделать AI-модели быстрее и легче без потери точности
В новом исследовании Google представили подход под названием Sequential Attention.
Идея простая по смыслу, но мощная по эффекту - модель учится фокусироваться только на действительно важных частях вычислений, а всё лишнее постепенно отбрасывает.
Почему это вообще проблема
Современные нейросети огромные. Они:
- считают слишком много
- используют кучу признаков и параметров
- тратят много памяти и энергии
При этом далеко не всё, что модель обрабатывает, реально влияет на итоговый ответ.
Но определить заранее, что важно, а что нет - математически очень сложно.
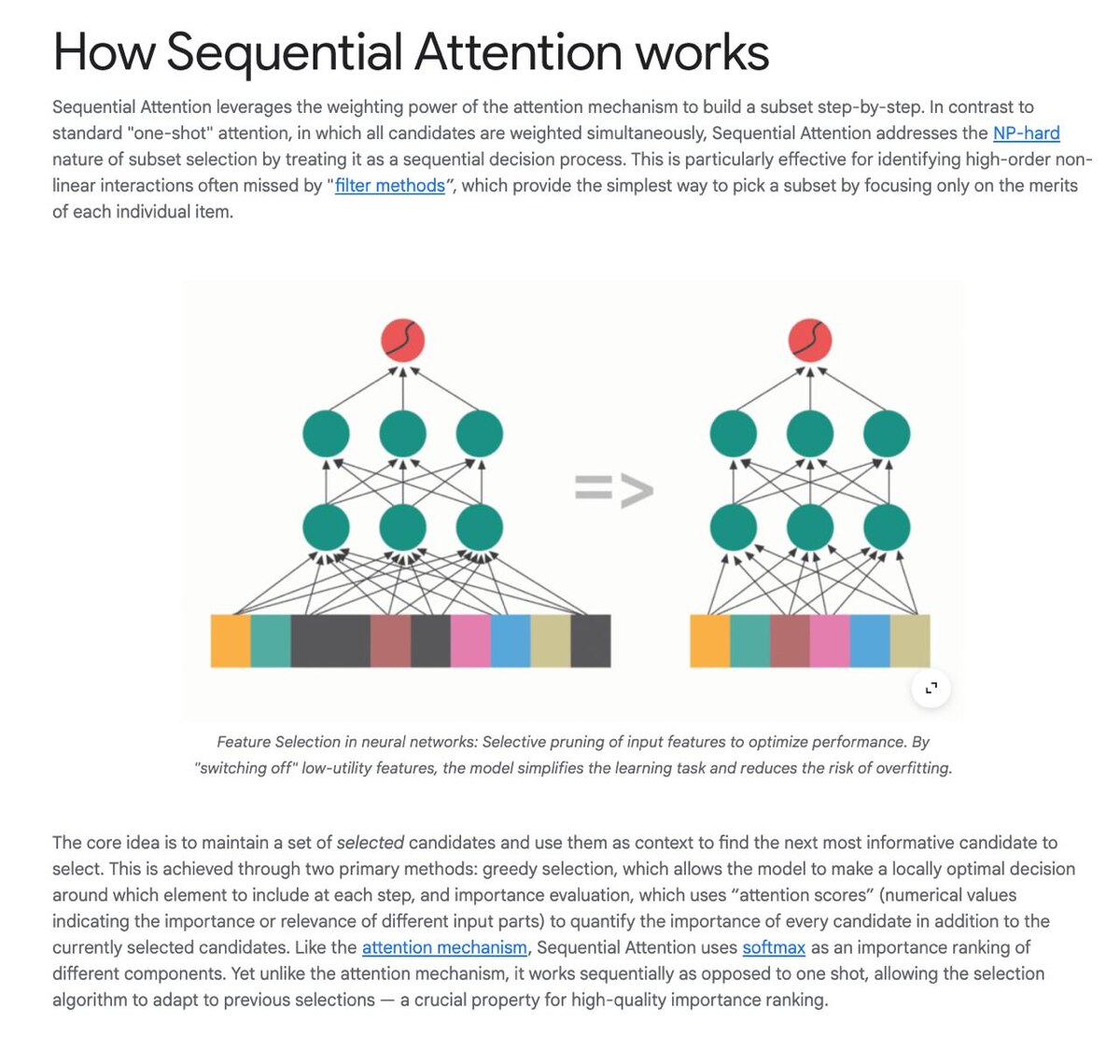
Что делает Sequential Attention. Метод работает пошагово.
Вместо того чтобы сразу использовать всё, алгоритм:
1. Выбирает один самый полезный компонент
2. Смотрит, что уже выбрано
3. Добавляет следующий, который даёт наибольшую пользу
4. Повторяет процесс последовательно
То есть модель как будто собирает себя заново-— из самых значимых частей, а не из всего подряд.
Что это даёт на практике
- Меньше вычислений - модель работает быстрее
- Меньше нагрузка на память и железо
- Ниже энергопотребление
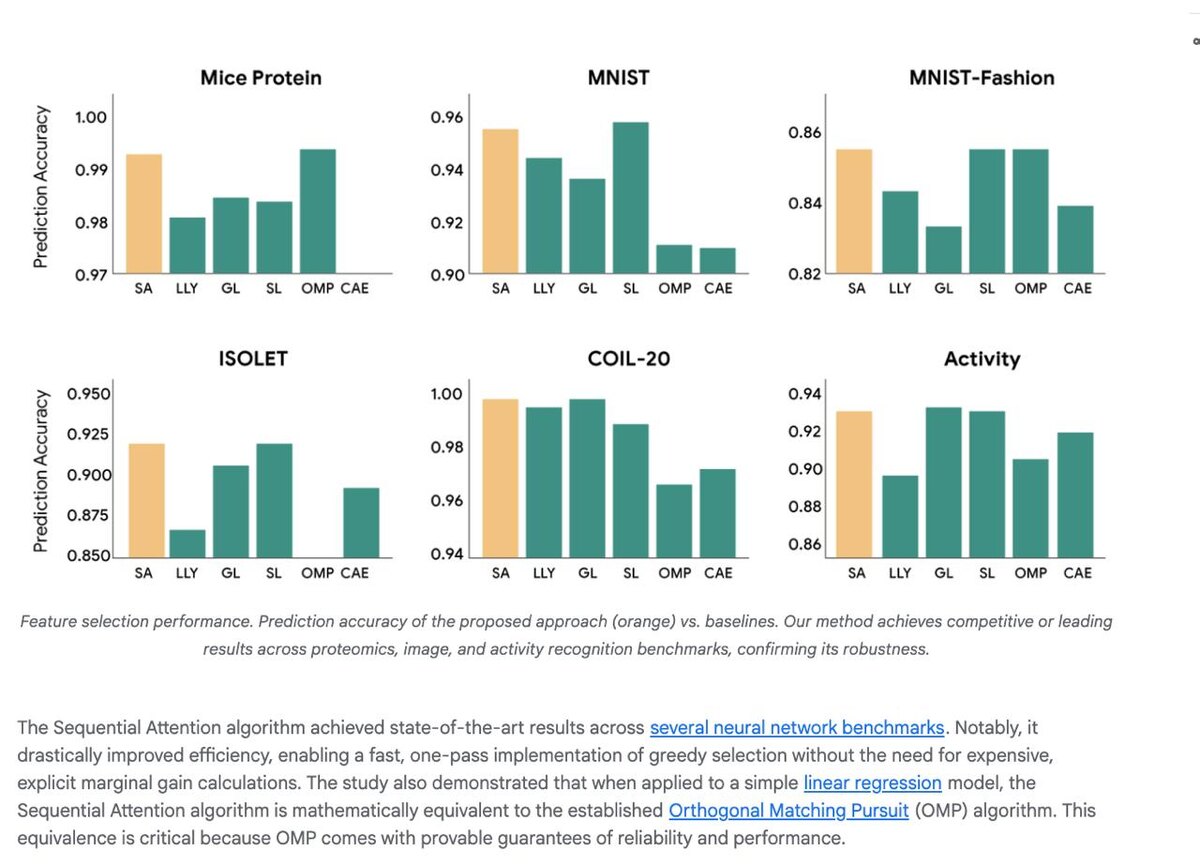
- И самое главное - точность почти не страдает
Это редкий случай, когда становится и быстрее, и дешевле, без серьёзных компромиссов по качеству.
Размеры моделей растут быстрее, чем инфраструктура. Поэтому ключевой тренд - не просто делать модели больше, а делать их умнее в плане вычислений.
Sequential Attention - это шаг в сторону “бережливого ИИ”, где:
- не каждая операция обязательна
- не каждый параметр нужен всегда
- модель учится экономить ресурсы сама
И чем крупнее системы, тем ценнее такие подходы.