🚀 Tencent мощно заходит в тему context learning.
Вышел open-source бенчмарк CL-bench - и это не просто очередной датасет, а попытка сдвинуть фокус всей индустрии.
Tencent HY совместно с Fudan University выпустили новую работу:
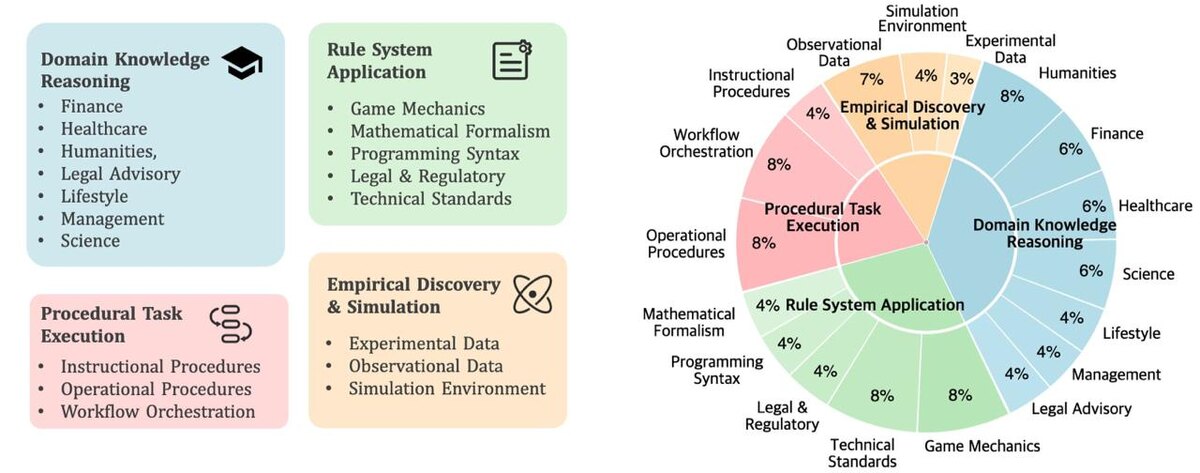
“CL-bench: A Benchmark for Context Learning” - системный бенчмарк для оценки того, *насколько модели реально умеют думать в контексте*, а не просто вспоминать выученное.
Это первый ресерч-релиз команды Vinces Yao после его перехода в Tencent - и по амбициям видно, что ребята метят в фундаментальные изменения.
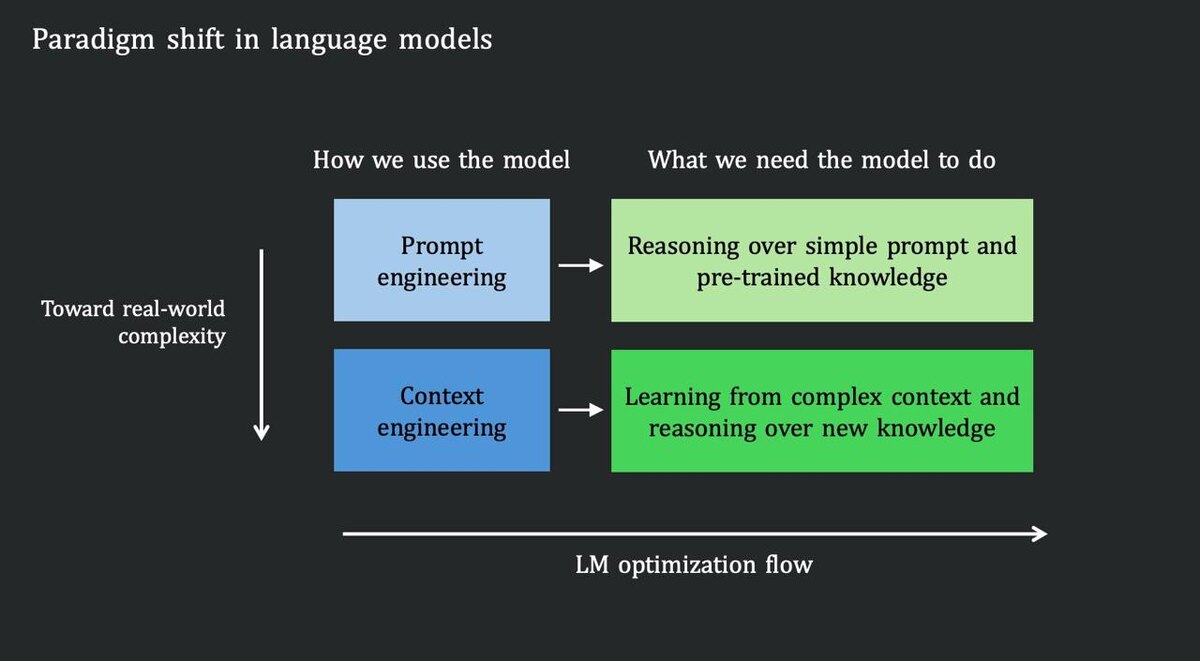
Сегодня большинство LLM живут по схеме:
огромные веса + запомненные паттерны = ответы
Но реальный мир - это не экзамен по памяти. Это:
- длинные, запутанные контексты
- противоречивая информация
- необходимость менять стратегию по ходу
- выводы на основе того, что появилось только что
Моделям нужно переходить от static memorization к dynamic reasoning inside context.
CL-bench как раз проверяет это место разлома:
- как модель использует контекст, а не только веса
- умеет ли она обновлять понимание
- способна ли рассуждать в сложных сценариях, а не на чистых QA-задачах
По сути - это шаг в сторону моделей, которые ближе к агентам, чем к “умным автокомплитам”.
Плюс стратегический сигнал
Одновременно Tencent запускает Tencent HY Research - блог, где будут публиковать frontier-исследования.
Это выглядит как заявка:
“Мы не просто треним большие модели. Мы хотим влиять на то, как их вообще оценивают.”
А это уже уровень влияния на направление всей области.
CL-bench - это не про +0.5% на лидерборде.
Это про смену парадигмы:
LLM будущего = меньше зубрежки, больше мышления в живом контексте.
И если эта линия выстрелит - именно такие бенчмарки будут решать, кто реально сделал “умную” модель, а кто просто раздул параметры.
🌐 Project Page: http://clbench.com
📖 Blog: https://hy.tencent.com/research