Отказоустойчивость АСУ ТП — это не роскошь, а необходимость для безопасной работы производства. Отказ системы управления может привести к остановке технологических линий, потере критичных данных и угрозе для персонала. Регулярная проверка резервирования, мониторинга и планов восстановления снижает риск аварий на 60–80%. Комплексная оценка охватывает архитектуру дублирования компонентов, централизованную диагностику, тестирование отказоустойчивости, резервное копирование данных и документирование процедур. При правильной конфигурации достижима 99.9% доступность системы.
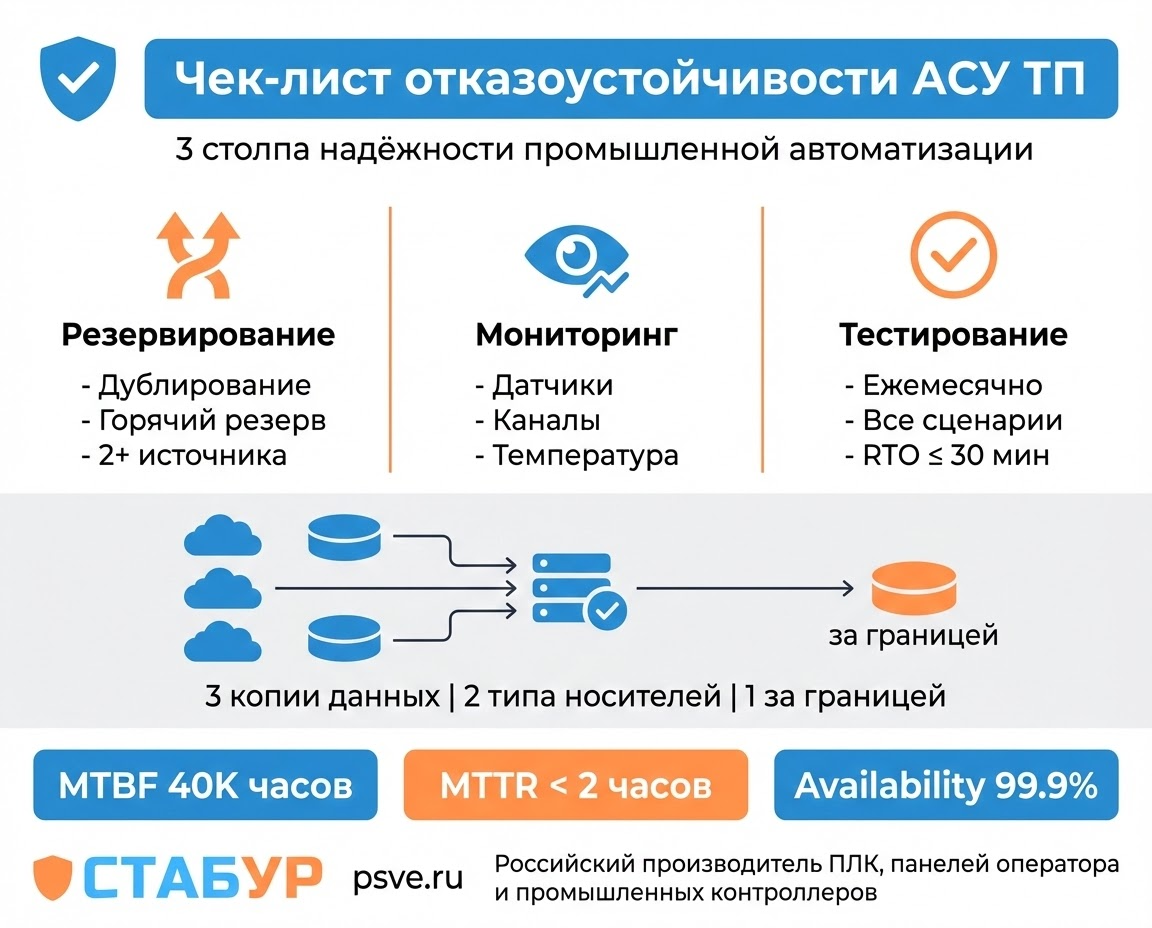
1. Архитектура отказоустойчивой АСУ ТП: дублирование на трёх уровнях
Первое, с чего начинается любая отказоустойчивая система управления технологическими процессами — это правильная архитектура. Нельзя добавить надёжность к некачественной архитектуре просто включением резервирования. Нужно продумать, какие компоненты при выходе из строя остановят производство, и именно их резервировать с приоритетом.
Резервирование работает на трёх уровнях одновременно. Во-первых, на уровне контроллеров используется горячее резервирование — два активных узла системы работают параллельно и постоянно синхронизируют своё состояние в реальном времени. Если основной контроллер падает, резервный моментально берёт управление без потери данных и без видимого сбоя в технологическом процессе. Целевое время переключения составляет 200–500 миллисекунд — это достаточно быстро для критичных процессов.
Во-вторых, на уровне сетевой коммуникации данные передаются по двум полностью независимым физическим каналам. Это может быть два отдельных кабеля витая пара, или оптоволокно плюс медный кабель, проложенные в разных кабелепроводах. Если основной канал выходит из строя при обрыве, шумовых помехах или неправильном контакте, система мгновенно переходит на второй. Критично, чтобы оба канала никогда не пересекались в одном месте — при единовременном повреждении оба отказали бы.
В-третьих, резервируется питание. Основное питание приходит из сети, резервное — из источника бесперебойного питания (ИБП) или автоматического выключателя резерва. ИБП обеспечивает безопасное завершение работы при полной потере питания, даёт время на переключение между источниками, и в некоторых критичных случаях позволяет системе продолжить работу в режиме ограниченной функциональности, пока восстанавливается основное питание.
2. Централизованный мониторинг и диагностика в реальном времени
Отказоустойчивая архитектура без мониторинга — это слепая система. Вы не узнаете о проблеме, пока она не приведёт к аварии и потерям. Поэтому вторая ключевая часть — это непрерывное наблюдение за состоянием всех критичных компонентов.
Мониторинг должен охватывать несколько групп параметров. Состояние резервированных элементов — активен ли резервный контроллер прямо сейчас? Синхронизирована ли его программа и переменные с основным узлом? Нет ли задержек в обновлении? Система должна постоянно проверять, что резерв готов к немедленному переключению.
Качество сигналов с датчиков полей — каждый входной сигнал должен иметь флаг достоверности, который показывает: валидно ли это значение или датчик потерял связь, вышел за пределы диапазона, или произошла ошибка контрольной суммы. При потере достоверности основного датчика система должна автоматически переключиться на резервный сенсор (если он есть) и отправить оповещение оператору.
Работоспособность сетевых каналов требует наблюдения за задержкой пакетов, потерей фреймов, ошибками контрольных сумм. Даже небольшая деградация пропускной способности канала — это предвестник полного отказа. Установите пороги, при которых система перейдёт на резервный маршрут до полного разрыва.
Физические параметры окружения: температура в шкафу с контроллерами не должна превышать 50°C в нормальном режиме. При 60°C нужна немедленная реакция. Напряжение питания должно быть стабильным плюс-минус 10% от номинала. Свободное место на диске архивного сервера — критичный параметр, при котором история данных может прерваться.
3. Регулярное тестирование отказоустойчивости: от теории к практике
Красивая архитектура на бумаге часто расходится с реальностью. Тесты показывают, что задержка переключения составляет 5 секунд вместо обещанных 200 миллисекунд, или восстановление занимает 90 минут вместо 30. Поэтому регулярное тестирование — это не необязательное усовершенствование, а обязательная часть эксплуатации.
Базовый тест — отключение одного сетевого канала. На работающей системе физически отсоедините сетевой кабель от одного маршрута передачи данных. Система должна автоматически переключиться на второй канал. Убедитесь, что в логе событий появилось сообщение о потере канала, что обмен данными не прерывался и что оператор увидел уведомление. Технологический процесс должен продолжиться без рывков.
Второй тест — имитация отказа основного контроллера. Отключите основной контроллер питанием (или используйте специальный тестовый режим, если система это поддерживает). Запустите секундомер и засеките, за какое время система переключится на резервный контроллер и восстановит управление. Если переключение заняло дольше, чем технологический процесс может ждать, вы нашли узкое место архитектуры.
Третий обязательный тест — проверка автоматического резервирования питания. Отключите основной источник электроэнергии (или отключите вилку ИБП из розетки) и убедитесь, что система переключилась на резерв в течение 50 миллисекунд. Все критичные системы, включая модемы, маршрутизаторы и датчики, должны продолжить работу. ИБП должен обеспечить питание от батареи минимум 15–30 минут для безопасного завершения технологического процесса.
Четвёртый тест — синхронизация времени между узлами. Если два контроллера работают с рассогласованием времени более чем на несколько миллисекунд, при переключении могут произойти логические ошибки. Настройте NTP (Network Time Protocol) для синхронизации времени из общего источника и периодически проверяйте рассогласование между узлами. Оно должно быть не более 10 миллисекунд.
Пятый тест — восстановление после полного отказа всей системы. Отключите всю электроэнергию на предприятии (или используйте тестовый стенд). Дождитесь, пока все конденсаторы полностью разрядятся (это занимает 20–30 секунд). Затем включите питание и засеките время, за которое система полностью стартует, восстановит последнее известное состояние из резервной копии и возобновит управление процессом. Это время обычно составляет 5–10 минут в зависимости от сложности системы.
Эти тесты должны проводиться минимум раз в месяц. Результаты нужно документировать в журнале: дата теста, время переключения, возникшие проблемы, принятые меры.
4. Стратегия резервного копирования данных: правило 3-2-1
Частая ошибка в промышленности — дублировать контроллеры, но забывать про резервное копирование истории технологического процесса. История — это золото. Она позволяет диагностировать причины сбоев, доказывает соответствие технологическому регламенту при проверках, и это единственный способ восстановить систему после полного отказа архивного сервера.
Используйте правило 3-2-1 для резервного копирования. Это значит: минимум три копии данных на разных носителях. Первая копия — основной архивный сервер АСУ ТП, где в реальном времени записывается история всех технологических параметров. Вторая копия — на локальном хранилище или втором архивном сервере, расположенном в другом помещении предприятия. Третья копия — в облачном хранилище (Yandex Cloud, AWS, Azure) или на отдельном физическом сервере в другом городе.
Две копии должны храниться на разных типах носителей. Первая — на SSD (твёрдотельный накопитель) для быстрого восстановления. Вторая — на HDD (жёсткий диск) для долгосрочного хранения и экономии места. Оба должны иметь избыточность через RAID-массив, чтобы отказ одного диска не потерял данные.
Одна копия должна физически находиться за пределами предприятия — в облаке или в удалённом центре данных. Это защита от катастрофических сценариев: пожар, затопление, техногенная авария на объекте.
Проверка эффективности резервного копирования должна проводиться регулярно. Ежемесячно полностью восстановите всю АСУ ТП из последней резервной копии на тестовом стенде. Не просто проверяйте, что файлы скопировались, а стартуйте систему и убедитесь, что данные последовательны и нет нарушений целостности. Ведите журнал времени восстановления — если оно заняло 90 минут, а ваш регламент требует 30 минут, пересмотрите архитектуру хранилища или целевой показатель RTO (Recovery Time Objective).
5. Документирование архитектуры и план аварийного восстановления
Знания в голове разработчика или системного администратора — это источник огромного риска. При его уходе или болезни вся информация теряется. Поэтому полная документация — это не оформление, а страховка для предприятия.
Документация должна включать несколько ключевых документов. Первый — матрица критичности и резервирования: какой компонент за что отвечает, какие последствия при его отказе (остановка одной технологической линии, потеря управления всем производством), какой уровень резервирования применён. Эта матрица помогает при аварии быстро принять решение: стоит ли ждать специалиста три часа или нужно прямо сейчас отключить отдельную ветку для безопасности.
Второй документ — подробная схема архитектуры АСУ ТП с явным указанием маршрутов сетевых каналов, источников питания, физического расположения датчиков и контроллеров. На бумаге всё понимают; в экстренной ситуации в 2 ночи схема спасает время.
Третий — план аварийного восстановления (DRP — Disaster Recovery Plan): пошаговая инструкция, что делать при различных сценариях отказа. От простого отключения одного контроллера до полной потери связи с объектом и отказа архивного сервера. Каждый шаг должен быть конкретным и проверяемым: 1) отключить питание ИБП, 2) проверить состояние RAID-массива командой, 3) запустить восстановление из резервной копии за дату X, 4) убедиться, что процесс начал работу.
Четвёртый документ — регламент тестирования отказоустойчивости: какие тесты проводить, как часто (минимум ежемесячно), кто ответственен, какие метрики собирать, как документировать результаты.
6. Стандарты и нормативные требования
Отказоустойчивость — это не опция, а требование закона и международных стандартов. В России это требования ГОСТ Р в области промышленной автоматизации и рекомендации ГОСТ Р 27.102 по надёжности. Если ваше предприятие относится к критичной инфраструктуре, это может быть требование списка объектов КИИ.
В Европе действует директива NIS2 (Network and Information Security Directive), которая требует для критичной инфраструктуры иметь бизнес-план непрерывности (BCP) и план аварийного восстановления (DRP). Это больше не рекомендация — это требование с персональной ответственностью руководства.
Ключевые метрики надёжности, которые нужно отслеживать и документировать:
MTBF (Mean Time Between Failures) — среднее время между отказами. Если вашей системе требуется MTBF не менее 40 000 часов (более 4.5 лет непрерывной работы), это означает, что компоненты нужно выбирать с большим запасом по надёжности, критичные узлы обязательно резервировать, и нужна активная диагностика для выявления деградации.
MTTR (Mean Time To Repair) — среднее время, за которое система восстанавливается после отказа. Если вы не можете восстановиться быстрее чем за 2 часа, пересмотрите архитектуру, резервирование или запасы критичных компонентов.
Коэффициент готовности (Availability) — это отношение времени, когда система полностью функциональна, ко всему календарному времени. Формула: Availability = MTBF / (MTBF + MTTR). Для критичной промышленности обычно требуется 99% доступность (не более 52 часов простоя в год), 99.9% доступность (не более 8.7 часов в год), или в исключительных случаях 99.99% (не более 52 минут в год).
ПЛК СТАБУР (psve.ru) предоставляет архитектурные возможности для достижения высоких уровней доступности благодаря встроенным функциям горячего резервирования контроллеров и сетевых каналов, встроенной диагностике и поддержке стандартных протоколов резервирования.
7. Чек-лист проверки отказоустойчивости: практический инструмент
Используйте этот чек-лист для полной оценки состояния отказоустойчивости вашей АСУ ТП.
Архитектура и резервирование:
— Определена матрица критичности всех компонентов системы (контроллеры, датчики, сеть, питание).
— На каждый критичный компонент применено горячее резервирование или дублирование.
— Сетевые каналы физически независимы и расположены в разных кабелепроводах.
— Питание имеет двойной источник с автоматическим переключением (ИБП + резервная сеть).
— Резервные компоненты постоянно синхронизируют своё состояние с основными.
Мониторинг и диагностика:
— Установлен централизованный мониторинг состояния всех резервированных элементов.
— На все входные сигналы применены флаги достоверности с автоматическим переключением на резерв.
— Мониторится качество сетевых каналов (задержка, потеря пакетов, ошибки).
— Отслеживаются физические параметры: температура, напряжение, нагрузка CPU, свободное место на диске.
— В системе ведётся журнал всех событий отказа и переключения с возможностью анализа.
Тестирование:
— Проводятся регулярные тесты отказоустойчивости минимум ежемесячно.
— Документируются результаты каждого теста: дата, время, выявленные проблемы.
— Все сценарии отказа (потеря канала, отказ контроллера, сбой питания, полный перезапуск) протестированы на стенде.
— Время переключения соответствует требованиям технологического процесса.
— Система восстанавливается после полного отказа в установленное время (RTO).
Резервное копирование:
— Реализовано резервное копирование по правилу 3-2-1 (три копии на разных носителях).
— Одна копия находится за пределами предприятия (облако или удалённый центр данных).
— Ежемесячно проводится полное восстановление из резервной копии на тестовом стенде.
— Время восстановления соответствует установленному RTO.
— Проверяется целостность данных в резервной копии (контрольные суммы, валидация структуры).
Документация:
— Разработана матрица критичности и резервирования всех компонентов.
— Составлена подробная схема архитектуры системы со всеми маршрутами и зависимостями.
— Разработан и актуализирован план аварийного восстановления для всех сценариев отказа.
— Составлен регламент регулярного тестирования с указанием ответственных лиц.
— Документированы все процедуры реагирования на отказы и восстановления.
Персонал и подготовка:
— Персонал, ответственный за АСУ ТП, обучен процедурам реагирования на отказы.
— Проводятся учебные тренировки по плану аварийного восстановления.
— Каждый оператор знает, какие действия нужно предпринять при различных сценариях отказа.
Стандарты и требования:
— Определены целевые показатели RTO (время восстановления) и RPO (приемлемая потеря данных).
— Система соответствует применимым стандартам (ГОСТ Р, NIS2, IEC 62443).
— Если предприятие в списке объектов КИИ, выполнены все требования по защите и отказоустойчивости.
— Ведётся постоянное соответствие показателям MTBF и MTTR.
Заключение
Отказоустойчивость АСУ ТП — это не один раз построенная система, а живой организм, требующий постоянной диагностики, обслуживания, тестирования и совершенствования. Небольшие инвестиции сегодня в архитектуру, резервирование, мониторинг и регулярное тестирование обходятся в стократ дешевле, чем затраты на аварийное восстановление и потери от остановок производства.
Отказ критичной системы управления обходится промышленному предприятию в миллионы рублей убытков за каждый час простоя. Соблюдение этого чек-листа позволяет снизить риск аварий, повысить доступность системы до 99.9% и спать спокойно, зная, что управление процессом защищено от катастрофических отказов.
Автор: Дмитрий Стабуров, инженер АСУ ТП
#АСУ ТП #отказоустойчивость #резервирование #надежность #SCADA #промышленная автоматизация #мониторинг #резервное копирование #DRP #план восстановления