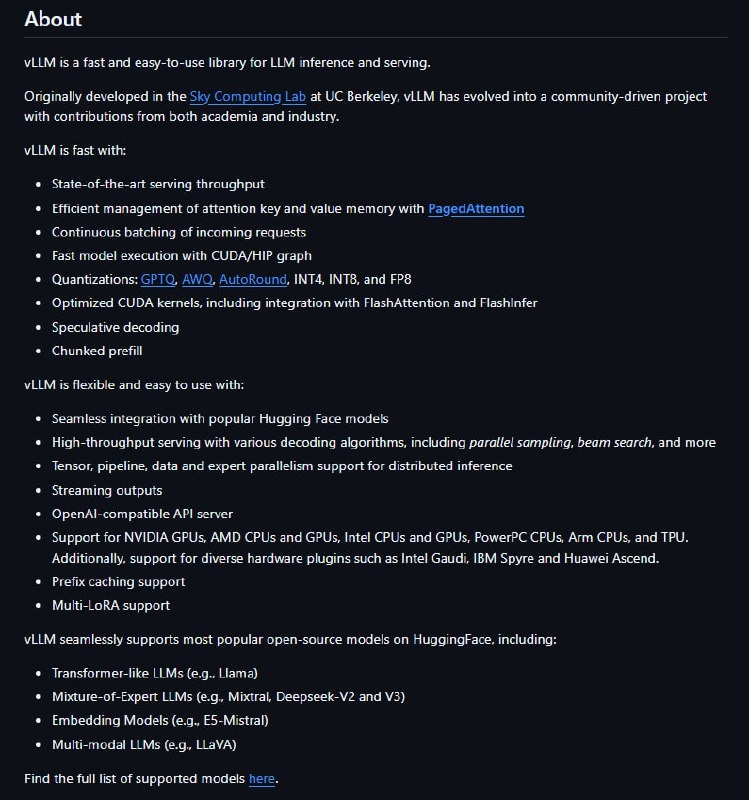
Предназначен для эффективного запуска LLM (LLaMA, Mistral, Qwen и др.) в продакшене и локально, особенно при большом количестве одновременных запросов. 📌 Основные особенности: 🔵Очень высокая скорость генерации текста 🔵Экономное использование видеопамяти 🔵Поддержка большого количества одновременных запросов 🔵Совместимость с OpenAI API 🔵Поддержка популярных языковых моделей 🔵Генерация ответов в реальном времени 🔵Стабильная работа под высокой нагрузкой 🔵Удобен для использования в продакшене 🔵Работает на GPU с CUDA ➡️Установка библиотеки: pip install vllm 📱 Репозиторий ⚙️ Документация ➡️Справочник Программиста. Подписаться
⚒️ vLLM — это высокопроизводительный движок инференса и сервинга больших языковых моделей, оптимизированный по памяти и скорости.
Предназначен для эффективного запуска LLM (LLaMA, Mistral, Qwen и др.) в продакшене и локально, особенно при большом количестве одновременных запросов.
📌 Основные особенности:
🔵Очень высокая скорость генерации текста
🔵Экономное использование видеопамяти
🔵Поддержка большого количества одновременных запросов
🔵Совместимость с OpenAI API
🔵Поддержка популярных языковых моделей
🔵Генерация ответов в реальном времени
🔵Стабильная работа под высокой нагрузкой
🔵Удобен для использования в продакшене
🔵Работает на GPU с CUDA
➡️Установка библиотеки: pip install vllm
⚙️ Документация
➡️Справочник Программиста. Подписаться