Qwen представили Qwen3-Max-Thinking, и по метрикам модель выглядит очень серьёзно Ключевые результаты бенчмарков: 🟡 HLE 30.2 — примерно уровень Claude Opus 4.5, а с test-time-scaling обещают ещё выше 🟡 SWE Verified 75.3 — немного ниже Opus, но на уровне Gemini 3 Pro 🟡 IMO 83.9 — обходит Gemini 3 Pro, сильный результат по сложному рассуждению Помимо цифр, заявлены улучшенный tool calling и стабильное следование инструкциям, даже при работе с длинным контекстом. Попробовать модель: https://chat.qwen.ai/ #нейросети... #AI #aiбезграниц #машинноеобучение
✴️ Вышла Qwen3-Max-Thinking — мощная модель frontier-уровня
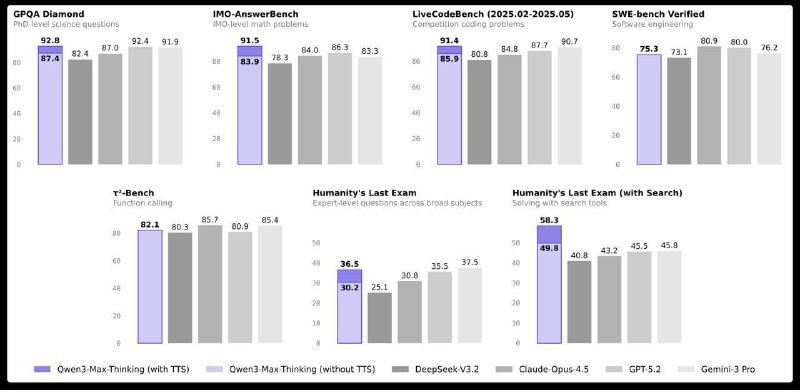
Qwen представили Qwen3-Max-Thinking, и по метрикам модель выглядит очень серьёзно
Ключевые результаты бенчмарков:
🟡 HLE 30.2 — примерно уровень Claude Opus 4.5, а с test-time-scaling обещают ещё выше
🟡 SWE Verified 75.3 — немного ниже Opus, но на уровне Gemini 3 Pro
🟡 IMO 83.9 — обходит Gemini 3 Pro, сильный результат по сложному рассуждению
Помимо цифр, заявлены улучшенный tool calling и стабильное следование инструкциям, даже при работе с длинным контекстом.
Попробовать модель:
#нейросети... #AI #aiбезграниц #машинноеобучение