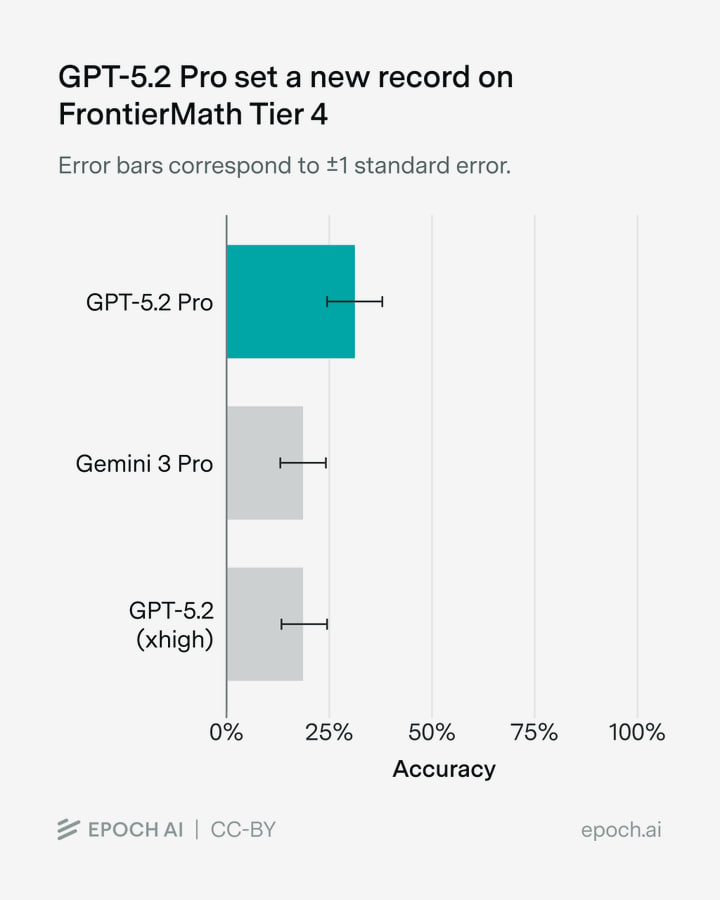
На бенчмарке FrontierMath, в четвёртом уровне сложности, зафиксирован новый рекорд: GPT-5.2 Pro набрал 31 %, заметно превысив предыдущий максимум в 19 %. Но сухая цифра здесь — не самое интересное. Куда важнее то, как этот результат был получен и что именно модель смогла решить.
Команда Epoch AI провела оценку вручную, напрямую через интерфейс ChatGPT. Причина довольно прозаична: при тестировании через API возникали проблемы с тайм-аутами, и, чтобы не искажать картину, исследователи решили временно отказаться от автоматического прогона. Это важная деталь: тестирование не было «оптимизировано под результат», а, напротив, проводилось в более жёстком и прозрачном режиме.
До этого ни одна модель не решала 13 задач четвёртого уровня. GPT-5.2 Pro справился с 11 из них, а также решил ещё несколько задач из общего пула. В итоге результат текущего раунда — 15 решённых задач из 48, то есть те самые 31 %. Если же учитывать все задачи четвёртого уровня, которые когда-либо удавалось решить любой модели, суммарный показатель теперь составляет 17 из 48, или 35 %.

Отдельно подчёркивается вопрос переобучения. OpenAI имеет эксклюзивный доступ к 28 задачам четвёртого уровня и их решениям, тогда как у Epoch остаются 20. GPT-5.2 Pro решил лишь 5 задач (18 %) из общего набора, но 10 задач (50 %) из выделенного. Такая асимметрия как раз говорит против гипотезы, что модель просто «знает ответы заранее»: если бы дело было в утечке или переобучении, картина выглядела бы иначе.
В процессе оценки были обнаружены и технические огрехи: две задачи изначально были некорректно засчитаны. После перепроверки результаты обновили, и баллы были распределены более точно между версиями GPT-5.2 и GPT-5.2 Pro.
Особый интерес вызывают отзывы самих математиков — авторов задач.
Одна из недавно решённых проблем была предложена Джоэлом Хассом, специалистом по низкоразмерной топологии и геометрии. После первого успеха он усложнил формулировку, по сути проверяя, не была ли удача случайной. GPT-5.2 Pro справился и с более жёсткой версией.
Задача от известного теоретика чисел Кена Оно была решена как GPT-5.2 (с очень высоким уровнем доступа), так и GPT-5.2 Pro. Оно в целом положительно оценил решение, но отметил, что текст объяснения местами не дотягивает по строгости — формально верно, но изложено не так аккуратно, как ожидал бы человек-математик.
Ещё одну задачу, предложенную Дэном Ромиком, модель решила так, что сам автор остался впечатлён результатом. В других случаях, например с задачами аналитической комбинаторики от Джея Пантона, решения оказались корректными, но использовали численные обходные пути, которых автор не закладывал в исходную идею задачи. Это не ошибка, но симптом: модель часто ищет кратчайший рабочий путь, а не «красивое» или концептуально ожидаемое решение.
Интересен и список нерешённых задач. По крайней мере один автор считает, что модели застревают из-за характерной слабости: они делают правдоподобное предположение и идут дальше, не пытаясь его доказать. Сам автор, работая над этой задачей, столкнулся с тем, что попытка доказательства разрушает интуитивную гипотезу и открывает более сложную картину. Модели до этого шага пока не доходят.
В итоге FrontierMath всё отчётливее перестаёт быть тестом «на знание формул». Это становится проверкой способности к исследовательскому мышлению: выдерживать неопределённость, проверять гипотезы, работать с неожиданными структурами. GPT-5.2 Pro ещё далёк от полноценного математика, но сам факт, что обсуждение идёт уже на этом уровне, — важный сдвиг.
Вопрос теперь не в том, может ли ИИ решать сложные задачи, а в том, какие формы математического мышления он осваивает первым — и какие пока остаются сугубо человеческими.
-----------------ПОДДЕРЖАТЬ АВТОРА ДОНАТОМ -------------------
- Много интересного - в телеграм "Математика не для всех"
- Взгляд на философию со стороны технаря - телеграм "Философия не для всех"