🚀 Google Research представила GIST — новый этап в “умной” выборке данных
Google Research опубликовала блог-пост о GIST — алгоритме, который помогает выбирать высококачественную подвыборку данных из огромных датасетов так, чтобы она была и разнообразной, и полезной для обучения моделей.
📌 Зачем это нужно
При обучении современных моделей (LLM, CV) данные становятся слишком большими, и обрабатывать всё сразу дорого по памяти и времени. Часто выбирают подмножество данных, но это непросто: нужно найти баланс между:
- разнообразием (не выбирать похожие примеры), и
- полезностью (высокая информативность выбранных точек).
📌 Как работает GIST
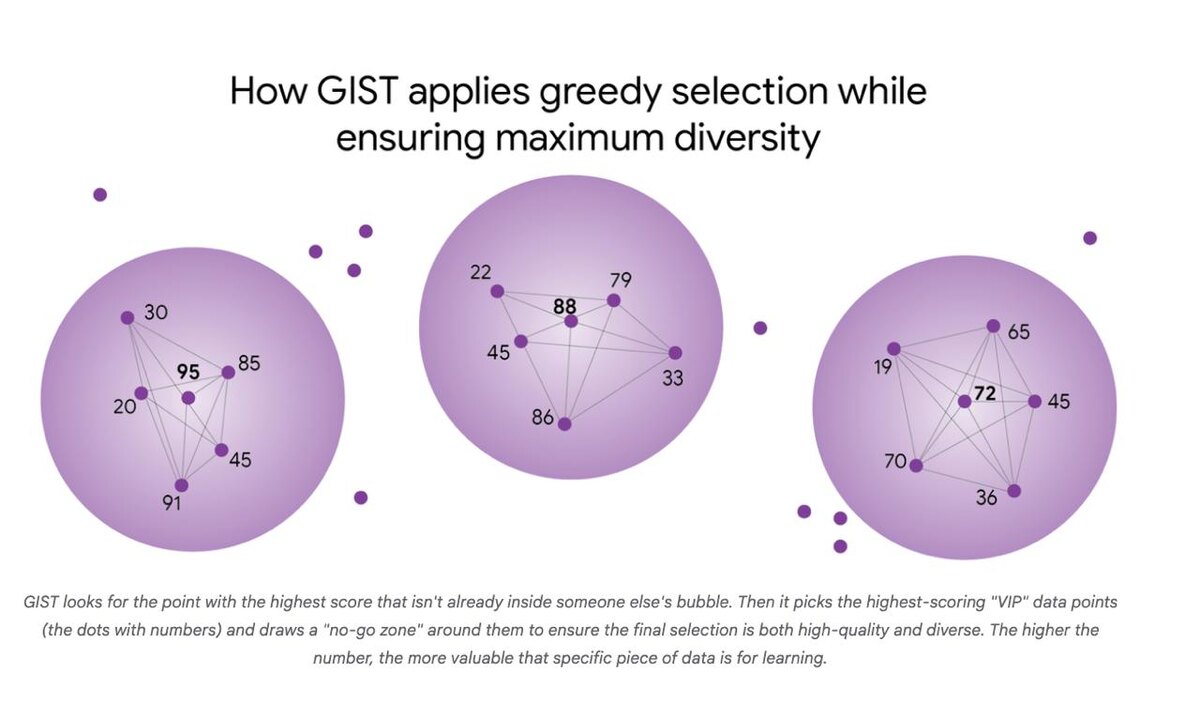
Алгоритм GIST (Greedy Independent Set Thresholding) формулирует задачу как сочетание двух целей — максимизации полезности и минимизации избыточности. Он:
- строит граф, где точки данных слишком близкие по расстоянию считаются “связанными”,
- затем находит независимые подмножества, которые максимизируют полезность, не выбирая очень похожие данные.
📌 Гарантии и результаты
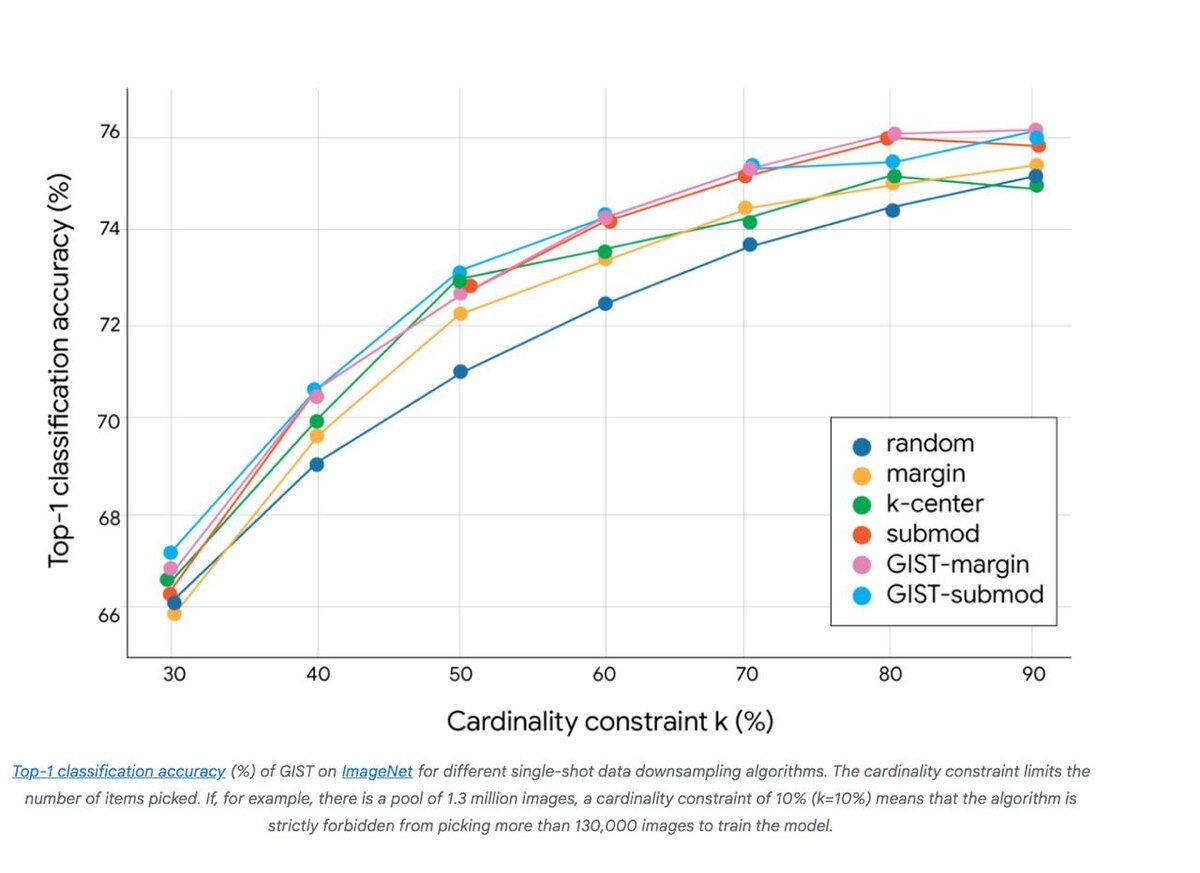
GIST — это не просто эвристика, а алгоритм с теоретическими гарантиями: он обеспечивает решение, близкое к оптимальному по комбинированной цели разнообразие+полезность. На практике он превосходит классические подходы на задачах вроде классификации изображений.
📊 Почему это важно
- Надёжная выборка данных критична для устойчивого обучения моделей.
- GIST помогает эффективно снизить объём данных, сохранив при этом ключевую информацию.
- Такой подход особенно ценен, когда данные дорогие или медленные для обработки.
✨ *GIST - шаг к более умной и гарантированной выборке данных, что может ускорить обучение крупных моделей и снизить затраты на вычисления при сохранении качества обучения.*
https://research.google/blog/introducing-gist-the-next-stage-in-smart-sampling/