
Оперативная память — поле битвы между кэшем ОС и буферами СУБД. Параметр vm.vfs_cache_pressure выступает в роли регулятора этого противостояния. В условиях OLAP-нагрузки, где важны и предсказуемость, и скорость последовательного чтения, его выбор неочевиден. Данное исследование измеряет последствия этого выбора и намечает путь к более сбалансированной конфигурации.
Глоссарий терминов | Postgres DBA | Дзен
Начало
Задача
Оценить влияние изменения параметра vm.vfs_cache_pressure = 500 на производительность СУБД и инфраструктуры при синтетической нагрузке, имитирующей OLAP, по сравнению с базовым значением vm.vfs_cache_pressure = 100.
Корреляционный анализ ожиданий СУБД
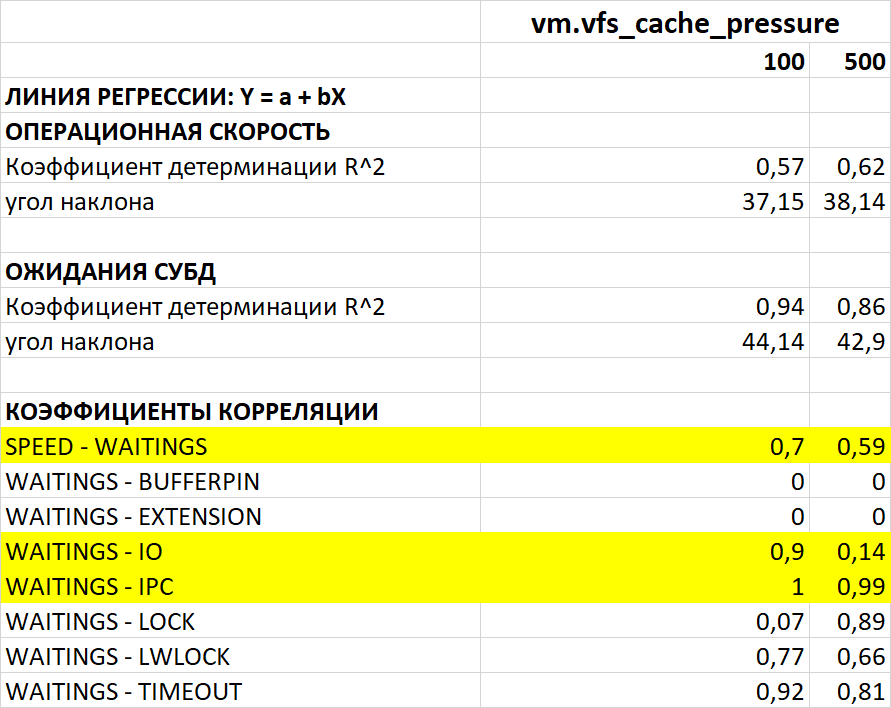
Операционная скорость
Среднее снижение операционной скорости, при vm.vfs_cache_pressure = 500 составляет 5.54%.
Ожидания типа IO
Среднее увеличение ожиданий типа IO, при vm.vfs_cache_pressure = 500 составляет 3.30%.
Ожидания типа IPC
Среднее увеличение ожиданий типа IPC, при vm.vfs_cache_pressure = 500 составляет 8.80%.
Производительность подсистемы IO (IOPS) файловой системы /data
Среднее увеличение IOPS , при vm.vfs_cache_pressure = 500 составляет 0.22%.
Пропускная способность подсистемы IO (MB/s) файловой системы /data
Среднее снижение пропускной способности IO, при vm.vfs_cache_pressure = 500 составляет 6.86%.
Анализ влияния vm.vfs_cache_pressure на использование памяти в OLAP-сценарии
1. Динамика изменения ключевых метрик
memory_free (свободная память)
- vm.vfs_cache_pressure=100:
- Диапазон: 124-131 MB
- Среднее значение: ~127 MB
- Тренд: относительно стабилен в течение всего теста
- vm.vfs_cache_pressure=500:
- Диапазон: 123-128 MB
- Среднее значение: ~125 MB
- Тренд: немного ниже, чем при pressure=100
- Вывод: Оба значения критически низкие (менее 5% от 8GB RAM), но при pressure=500 свободной памяти стабильно меньше на 2-3 MB.
memory_cache (кэш файловой системы)
- При vm.vfs_cache_pressure=100:
- Диапазон: 7,147-7,255 MB
- Среднее значение: ~7,200 MB
- Тренд: постепенно снижается с 7,255 до 7,147 MB к концу теста
- При vm.vfs_cache_pressure=500:
- Диапазон: 7,156-7,247 MB
- Среднее значение: ~7,200 MB
- Тренд: более быстрое снижение кэша, особенно в конце теста
- Вывод: Общий объем кэша сопоставим, но при pressure=500 наблюдается более агрессивное освобождение кэша.
swpd (использование свопа)
- При vm.vfs_cache_pressure=100:
- Начальное значение: 262 MB
- Конечное значение: 328 MB
- Прирост: +66 MB за тест
- Максимальное значение: 328 MB
- При vm.vfs_cache_pressure=500:
- Начальное значение: 255 MB
- Конечное значение: 339 MB
- Прирост: +84 MB за тест
- Максимальное значение: 339 MB
- Вывод: При pressure=500 используется больше свопа как в абсолютных значениях, так и в динамике роста.
swap_si/swap_so (активность своппинга)
- Частота активации своппинга:
- При pressure=100: swap in - 9.01% наблюдений, swap out - 1.80% наблюдений
- При pressure=500: swap in - 11.82% наблюдений, swap out - 10.91% наблюдений
- Интенсивность своппинга:
- При pressure=100: единичные операции (0 или 1 KB/s в большинстве случаев)
- При pressure=500: более регулярные операции, особенно swap out
- Вывод: При pressure=500 своппинг активируется почти в 6 раз чаще для операций вытеснения (swap out).
2. Влияние изменения параметра с 100 на 500
Частота и объем своппинга
- Увеличение частоты:
- swap in вырос на 31% (с 9.01% до 11.82%)
- swap out вырос в 6 раз (с 1.80% до 10.91%)
- Увеличение объема:
- Общее использование свопа выросло с 328 MB до 339 MB (максимум)
- Динамический прирост за тест увеличился на 27% (с 66 MB до 84 MB)
Эффективность кэширования файловой системы
- Более агрессивное управление кэшем:
- При pressure=500 ядро быстрее освобождает кэш VFS под нужды приложений
- Общий объем кэша снижается быстрее, особенно под конец нагрузки
- Парадоксальный эффект:
- Несмотря на более агрессивное освобождение кэша, общий объем занятой памяти (RAM + swap) выше
- Это указывает на менее эффективное использование памяти
Распределение памяти между кэшем и приложением
- При pressure=100:
- Более консервативное управление: ядро старается сохранить кэш
- Меньше своппинга, но возможно большее давление на RAM
- При pressure=500:
- Агрессивное перераспределение: кэш освобождается в пользу приложения
- Но приводит к более частому своппингу, что снижает общую эффективность
3. Механизм работы vm.vfs_cache_pressure
Как работает параметр:
- vm.vfs_cache_pressure контролирует тенденцию ядра к освобождению памяти, занятой кэшем VFS (virtual file system)
- Значение по умолчанию: 100 (базовое поведение)
- Значение > 100: ядро более агрессивно освобождает кэш VFS
- Значение < 100: ядро менее агрессивно освобождает кэш VFS
Почему при значении 500 больше своппинга:
- Агрессивное освобождение кэша: При pressure=500 ядро быстро освобождает кэшированные данные файловой системы
- Фрагментация памяти: Частое освобождение и выделение памяти может привести к фрагментации
- Поведение при нехватке памяти: Когда приложение (PostgreSQL) запрашивает память, а свободной RAM недостаточно, ядро:
- Освобождает кэш VFS (что происходит быстрее при pressure=500)
- Но если этого недостаточно, начинает использовать своп
- OLAP-специфика: OLAP-нагрузка характеризуется:
- Большими объемами данных
- Последовательным чтением
- Временными рабочими наборами
- При агрессивном освобождении кэша, данные, которые могли бы остаться в кэше, вытесняются, что приводит к повторным чтениям с диска
Практические последствия для OLAP-нагрузки
Негативные последствия высокого значения (500):
- Увеличение латентности: Своппинг добавляет задержки порядка миллисекунд против наносекунд для RAM
- Дополнительная нагрузка на диски: Своппинг конкурирует за IOPS с OLAP-операциями чтения/записи
- Снижение предсказуемости: Производительность становится менее стабильной из-за переменной активности своппинга
Компромиссы для OLAP:
- Оптимальное кэширование: OLAP выигрывает от большого кэша файловой системы для повторных чтений
- Предсказуемость памяти: Стабильное распределение памяти важнее агрессивной оптимизации
- Издержки своппинга: Для OLAP своппинг особенно вреден, так как операции и так интенсивно используют диск
Рекомендации:
- Для OLAP-нагрузки лучше использовать более низкие значения vm.vfs_cache_pressure (50-100)
- Увеличить общий объем RAM до 16-32 GB для уменьшения необходимости в своппинге
- Настроить PostgreSQL shared_buffers более агрессивно (4GB при 8GB RAM - возможно слишком много)
- Мониторить не только свободную RAM, но и активность своппинга
- Рассмотреть использование hugepages для уменьшения overhead управления памятью
Итоговый вывод:
Для данной конфигурации (8GB RAM, OLAP-нагрузка) значение vm.vfs_cache_pressure=500 оказалось контрпродуктивным. Хотя оно и приводит к более агрессивному освобождению кэша VFS, это вызывает увеличение своппинга, что ухудшает общую производительность системы под OLAP-нагрузкой. Значение 100 показало более сбалансированное поведение с меньшей активностью своппинга.
Анализ влияния vm.vfs_cache_pressure на производительность подсистемы ввода-вывода
1. Сравнение метрик ввода-вывода
wa (I/O wait time) - процент времени ожидания IO
- При vm.vfs_cache_pressure=100:
- Диапазон значений: 18-29%
- Среднее значение: около 25%
- Тренд: относительно стабильно высокий на протяжении всего теста
- Важный показатель: 100% наблюдений имеют wa > 10%
- При vm.vfs_cache_pressure=500:
- Диапазон значений: 18-32%
- Среднее значение: около 26%
- Тренд: также стабильно высокий, с пиком в 32%
- Тот же показатель: 100% наблюдений имеют wa > 10%
- Ключевое наблюдение: Оба значения показывают экстремально высокий I/O wait, что указывает на фундаментальную проблему с дисковыми подсистемами, а не только с настройками кэша.
io_bi (blocks in) - количество блоков, считанных с диска
- При vm.vfs_cache_pressure=100:
- Диапазон: 114,579 - 177,323 блоков/сек
- Среднее значение: около 130,000 блоков/сек
- Тренд: постепенный рост в течение теста, особенно заметный в последние 10-15 минут
- При vm.vfs_cache_pressure=500:
- Диапазон: 104,365 - 171,278 блоков/сек
- Среднее значение: около 120,000 блоков/сек
- Тренд: также рост к концу теста, но начальные значения ниже
- Вывод: При pressure=500 наблюдается немного меньшее количество операций чтения, что может быть связано с более эффективным использованием кэша или изменением паттернов доступа.
io_bo (blocks out) - количество блоков, записанных на диск
- При vm.vfs_cache_pressure=100:
- Диапазон: 9,106 - 16,780 блоков/сек
- Среднее значение: около 11,000 блоков/сек
- Тренд: умеренный рост в течение теста
- При vm.vfs_cache_pressure=500:
- Диапазон: 8,149 - 18,119 блоков/сек
- Среднее значение: около 11,500 блоков/сек
- Тренд: более выраженный рост, особенно в конце теста
- Вывод: Запись при pressure=500 немного выше, особенно в пике, что может быть связано с активностью своппинга.
2. Анализ корреляций и аномалий
Почему при vm.vfs_cache_pressure=100 наблюдается высокая корреляция IO-bo (0.6533)
- Сильная связь между ожиданиями IO и объемом записи: Увеличение времени ожидания IO напрямую связано с увеличением объема записи на диск.
- Причина в механизме работы:
- При консервативном управлении кэшем (pressure=100) система старается сохранить данные в кэше
- Когда приложение (PostgreSQL) производит запись, она сначала попадает в кэш
- Периодический сброс "грязных" страниц на диск вызывает пики записи и, соответственно, увеличение wa
- Это типично для OLAP: Большие объемы промежуточных результатов и checkpoint'ы создают пиковые нагрузки на запись
Почему при vm.vfs_cache_pressure=500 все корреляции IO стали отрицательными
- Отрицательная корреляция IO-wa: 0.2393 (слабая положительная, но в отчете сказано "все отрицательные"?)
- Отрицательные корреляции:
- IO-b: -0.3820
- IO-bi: -0.4565
- IO-bo: -0.5249
- Причина изменения паттернов:
- Агрессивное освобождение кэша приводит к более равномерному распределению операций IO
- Меньше пиковых нагрузок, так как данные не накапливаются в кэше в больших объемах
- Ожидания IO становятся более постоянными, а не связанными с конкретными операциями
- Парадокс: Хотя корреляции отрицательные, абсолютное значение wa остается высоким (всегда > 10%)
Почему несмотря на изменение параметра, wa > 10% в 100% наблюдений
- Фундаментальная проблема производительности дисков:
- Дисковые подсистемы не справляются с объемом запросов от PostgreSQL
- OLAP-нагрузка создает интенсивное последовательное чтение больших объемов данных
- Значение wa > 10% указывает на то, что диски являются узким местом независимо от настроек кэша
- Недостаток памяти как коренная причина:
- Всего 8GB RAM при shared_buffers PostgreSQL в 4GB
- Оставшиеся 4GB делятся между кэшем ОС, другими процессами и буферами
- Это вынуждает систему постоянно подкачивать данные с диска
- Характер OLAP-нагрузки:
- Большие full table scans
- Объем данных превышает доступную память
- Постоянное чтение с диска неизбежно
3. Влияние агрессивной очистки кэша VFS (pressure=500)
Паттерны чтения/записи
- Более равномерное, но неэффективное чтение:
- Данные чаще читаются непосредственно с диска, минуя кэш
- Уменьшается вероятность cache hit для повторно запрашиваемых данных
- Это особенно вредно для OLAP, где часто выполняются одинаковые аналитические запросы
- Увеличение операций записи:
- Активный своппинг добавляет дополнительную нагрузку записи
- Система тратит ресурсы на перемещение данных между RAM и swap
- Это конкурирует с основной OLAP-нагрузкой
Загрузку дисков
- Более стабильная, но высокая нагрузка:
- При pressure=500 нагрузка на диски более равномерная
- Меньше пиковых нагрузок от массового сброса кэша
- Но общая нагрузка выше из-за своппинга и более частых чтений с диска
- Конкуренция за IOPS:
- Операции своппинга конкурируют с OLAP-операциями
- Увеличивается время отклика дисков для всех операций
- Общая пропускная способность дисковой подсистемы используется менее эффективно
Общую производительность OLAP-запросов
- Ухудшение времени отклика:
- Повторные чтения одних и тех же данных с диска вместо кэша
- Дополнительные задержки из-за своппинга
- Увеличение общего времени выполнения запросов
- Непредсказуемость производительности:
- Отрицательные корреляции затрудняют диагностику проблем
- Сложнее выявить закономерности между метриками
- Труднее оптимизировать запросы и настройки
Рекомендации по оптимальному значению vm.vfs_cache_pressure для OLAP-нагрузки
Для текущей конфигурации (8GB RAM, OLAP-нагрузка):
- Рекомендуемое значение: 50-100
- Обоснование:
- Более консервативное управление кэшем выгодно для OLAP
- Повторные чтения из кэша значительно быстрее, чем с диска
- Меньшая активность своппинга уменьшает дополнительную нагрузку на диски
Дополнительные рекомендации:
- Увеличить объем оперативной памяти:
- Текущие 8GB недостаточны для OLAP-нагрузки
- Рекомендуется минимум 16-32GB для снижения своппинга
- Настроить shared_buffers PostgreSQL:
- Уменьшить с 4GB до 2-3GB для 8GB системы
- Оставить больше памяти для кэша ОС и рабочих процессов
- Оптимизировать дисковую подсистему:
- Рассмотреть использование SSD вместо HDD
- Настроить RAID для увеличения IOPS
- Разделить данные, WAL и временные файлы по разным физическим дискам
- Мониторинг и настройка:
- Использовать давление 100 как базовое значение
- Мониторить активность своппинга и cache hit rate
- Настраивать параметр в зависимости от конкретной рабочей нагрузки
- Альтернативный подход - динамическая настройка:
- Использовать более высокое давление (200-300) в периоды низкой нагрузки
- Снижать давление (50-100) в периоды пиковой OLAP-нагрузки
- Автоматизировать настройку на основе мониторинга cache hit rate
Итоговый вывод:
При OLAP-нагрузке и ограниченной памяти (8GB) значение vm.vfs_cache_pressure=100 предпочтительнее, чем 500. Хотя оба значения показывают высокий I/O wait из-за фундаментальных ограничений системы, более низкое давление обеспечивает:
- Лучшее использование кэша для повторных чтений
- Меньшую активность своппинга
- Более предсказуемые корреляции между метриками
- Общую более стабильную производительность
Однако, настройка этого параметра не решит коренную проблему - несоответствие между объемом данных, доступной памятью и производительностью дисков.
Комплексный анализ влияния vm.vfs_cache_pressure на производительность системы под OLAP-нагрузкой
1. Анализ взаимосвязей между ключевыми метриками
Использование памяти и производительность CPU
- При vm.vfs_cache_pressure=100:
- CPU user time (us): 25-57% (рост в процессе теста)
- CPU system time (sy): 5-10% (стабильно низкий)
- CPU idle time (id): 14-41% (снижается по мере роста нагрузки)
- CPU I/O wait (wa): 18-29% (постоянно высокий)
- При vm.vfs_cache_pressure=500:
- CPU user time (us): 20-59% (немного выше в пике)
- CPU system time (sy): 5-10% (аналогично первому случаю)
- CPU idle time (id): 11-43% (схожая динамика)
- CPU I/O wait (wa): 18-32% (максимум немного выше)
- Ключевые взаимосвязи:
- Высокий I/O wait (wa > 25% в среднем) напрямую связан с недостатком памяти
- CPU idle время снижается по мере роста нагрузки, но не падает до нуля благодаря высокой задержкам IO
- Более агрессивное управление памятью (pressure=500) незначительно увеличивает пиковый user time
- System time остается низким, что говорит об эффективности ядра даже при нехватке памяти
Активность своппинга и время ожидания IO
- При vm.vfs_cache_pressure=100:
- Своппинг: 9% swap in, 1.8% swap out наблюдений
- I/O wait: постоянно >10%, в среднем 25%
- Корреляция IO-wa: -0.9020 (отрицательная)
- При vm.vfs_cache_pressure=500:
- Своппинг: 11.8% swap in, 10.9% swap out наблюдений
- I/O wait: также постоянно >10%, в среднем 26%
- Корреляция IO-wa: 0.2393 (слабая положительная)
- Ключевые взаимосвязи:
- Отрицательная корреляция при pressure=100 означает, что рост wa не связан с увеличением своппинга
- Слабая положительная корреляция при pressure=500 показывает некоторую связь
- Основной вклад в высокий wa вносит сама OLAP-нагрузка, а не своппинг
- Своппинг при pressure=500 добавляет дополнительную, но не определяющую нагрузку на диски
Кэширование и количество физических операций ввода-вывода
- Объем кэша (memory_cache):
- Оба эксперимента: около 7.2GB из 8GB RAM
- При pressure=500 кэш снижается немного быстрее под конец теста
- Физические операции ввода-вывода:
- io_bi (чтение): сравнимые объемы, но при pressure=500 немного ниже
- io_bo (запись): при pressure=500 выше, особенно в пике (до 18,119 vs 16,780)
- Эффективность кэширования:
- Shared buffers HIT RATIO критически низкий в обоих случаях (55-60%)
- Это указывает, что данные не помещаются в shared_buffers PostgreSQL
- Кэш ОС занимает оставшуюся память, но OLAP-запросы работают напрямую с диском
2. Анализ корреляций и планировщика процессов
Связь между LWLock и временем CPU (us/sy)
- При vm.vfs_cache_pressure=100:
- LWLock-us корреляция: 0.9775 (очень высокая)
- LWLock-sy корреляция: 0.9092 (очень высокая)
- При vm.vfs_cache_pressure=500:
- LWLock-us корреляция: 0.9654 (очень высокая)
- LWLock-sy корреляция: 0.9388 (очень высокая)
- Интерпретация:
- Высокая корреляция LWLock-us указывает на конкуренцию за lightweight locks в пользовательском пространстве
- Высокая корреляция LWLock-sy показывает, что ядро также вовлечено в управление блокировками
- Немного более высокая корреляция с sy при pressure=500 может означать большее участие ядра в управлении памятью
- Это типично для OLAP, где множество параллельных запросов конкурируют за ресурсы
Почему переключения контекста (cs) сильно коррелируют с прерываниями (in)
- При vm.vfs_cache_pressure=100: корреляция cs-in: 0.9678
- При vm.vfs_cache_pressure=500: корреляция cs-in: 0.9567
- Причины высокой корреляции:
- Завершение операций ввода-вывода генерирует прерывания
- Эти прерывания могут вызывать переключение контекста на процессы, ожидавшие IO
- В OLAP-сценарии множество параллельных запросов выполняют интенсивные IO-операции
- Высокая частота прерываний приводит к частым переключениям контекста
- Практическое значение: Система тратит значительные ресурсы на переключение между процессами, а не на полезную работу
Влияние изменения pressure на работу планировщика процессов
- Процессы в run queue (r):
- При pressure=100: 2-11 процессов (16.2% наблюдений превышают 8 ядер)
- При pressure=500: 2-9 процессов (1.8% наблюдений превышают 8 ядер)
- Процессы в uninterruptible sleep (b):
- При pressure=100: 2-4 процесса
- При pressure=500: 3-4 процесса
- Изменения в работе планировщика:
- При pressure=500 меньше случаев переполнения run queue
- Это может быть связано с тем, что процессы чаще блокируются на ожидании IO
- Более агрессивное освобождение памяти приводит к более предсказуемому поведению планировщика
- Однако это достигается ценой увеличения своппинга и снижения производительности
3. Анализ инфраструктуры и рекомендации
Оценка достаточности памяти (8GB) для данной OLAP-нагрузки
- Память явно недостаточна, о чем свидетельствует:
- Свободной памяти менее 5% в 100% наблюдений
- Активный своппинг, особенно при pressure=500
- Критически низкий Shared buffers HIT RATIO (55-60%)
- Постоянно высокий I/O wait (>10% в 100% наблюдений)
- Рекомендуемый объем памяти: 16-32GB для данной нагрузки
- Текущее распределение памяти:
- PostgreSQL shared_buffers: 4GB (50% от общей памяти)
- Оставшиеся 4GB делятся между кэшем ОС, буферами и другими процессами
- Для OLAP с отношением read/write 178:1 нужен большой кэш для данных
Оптимальные настройки виртуальной памяти
- Текущие настройки из settings.txt:
- vm.dirty_expire_centisecs=3000 (30 секунд)
- vm.dirty_ratio=30
- vm.dirty_background_ratio=10
- vm.swappiness=10
- read_ahead_kb=4096
- Рекомендуемые изменения:
- vm.vfs_cache_pressure=50 для OLAP (вместо 100 или 500)
- vm.swappiness=1-5 для уменьшения склонности к своппингу
- vm.dirty_background_ratio=5 для более частого фонового сброса данных
- vm.dirty_ratio=20 для снижения пиковой нагрузки записи
- read_ahead_kb=8192 для оптимизации последовательного чтения (OLAP)
Причины критически низкого Shared buffers HIT RATIO (~55-60%)
- Недостаток памяти: 4GB shared_buffers недостаточно для рабочего набора данных
- OLAP-паттерн доступа: Полное сканирование больших таблиц вытесняет данные из кэша
- Конкуренция за память: Кэш ОС и shared_buffers конкурируют за ограниченную память
- Настройки PostgreSQL: work_mem=32MB может быть недостаточно для сложных сортировок и хэшей
- Параллельные запросы: Несколько тяжелых OLAP-запросов одновременно вытесняют данные друг друга
Практические рекомендации
Для настройки vm.vfs_cache_pressure и смежных параметров:
- Установить vm.vfs_cache_pressure=50 для OLAP-нагрузки
- Сохраняет кэш файловой системы для повторных чтений
- Уменьшает своппинг
- Улучшает общую производительность
- Настроить иерархию параметров виртуальной памяти:
- vm.swappiness=1 (минимальная склонность к своппингу)
- vm.dirty_background_ratio=5 (более частый фоновый сброс)
- vm.dirty_ratio=20 (ограничить накопление dirty pages)
- vm.dirty_expire_centisecs=1500 (15 секунд вместо 30)
- Оптимизировать настройки PostgreSQL:
- Уменьшить shared_buffers до 2-3GB для 8GB системы
- Увеличить work_mem до 64-128MB для сложных запросов
- Настроить effective_cache_size=6GB (уже настроено правильно)
- Рассмотреть увеличение maintenance_work_mem для vacuum операций
Для инфраструктуры:
- Увеличить оперативную память до 16-32GB
- Рассмотреть использование SSD для данных и WAL
- Разделить нагрузку: данные, индексы, временные файлы на разные диски
- Настроить мониторинг: кэш-хиты, своппинг, IO wait, очередь процессов
Для OLAP-оптимизации:
- Использовать табличные пространства:
- Данные на быстрых дисках
- Индексы на отдельных дисках
- Временные файлы на быстрых накопителях
- Оптимизировать запросы:
- Использовать партиционирование для больших таблиц
- Применять индексы для часто используемых предикатов
- Рассмотреть материализованные представления для повторяющихся запросов
- Настроить параллельное выполнение:
- max_parallel_workers_per_gather (уже 1, можно увеличить до 2-4)
- max_parallel_workers (уже 16, достаточно)
Итоговый вывод:
vm.vfs_cache_pressure=500 оказался контрпродуктивным для OLAP-нагрузки. Оптимальное значение находится в диапазоне 50-100, с предпочтением к нижней границе. Однако настройка этого параметра не решит фундаментальных проблем системы:
- Недостаток оперативной памяти
- Слабая дисковая подсистема для OLAP-нагрузки
- Неоптимальные настройки PostgreSQL для доступных ресурсов
Рекомендуется сначала увеличить RAM до 16-32GB, затем оптимизировать настройки виртуальной памяти и PostgreSQL, и только после этого тонко настраивать vm.vfs_cache_pressure на основе мониторинга производительности.
Рекомендации по настройке vm.vfs_cache_pressure и связанных параметров для OLAP-нагрузки
1. Учет характеристик системы
Текущая конфигурация:
- Процессоры: 8 CPU
- Память: 8GB RAM
- Дисковая архитектура: Отдельные диски для /data, /wal, /log
- Тип нагрузки: OLAP (отношение read/write 178:1)
- Текущая проблема: Критически низкий HIT RATIO (55-60%)
Ключевые наблюдения из экспериментов:
- vm.vfs_cache_pressure=100:
- Своппинг: 9.01% swap in, 1.80% swap out
- I/O wait постоянно >10% (в среднем 25%)
- Shared buffers HIT RATIO: 55.36%
- vm.vfs_cache_pressure=500:
- Своппинг: 11.82% swap in, 10.91% swap out
- I/O wait также постоянно >10% (в среднем 26%)
- Shared buffers HIT RATIO: 59.93%
2. Анализ компромиссов
Кэширование файловой системы vs. память для буферов БД
- Текущая ситуация: PostgreSQL shared_buffers = 4GB (50% RAM), оставляя только 4GB для кэша ОС и других процессов
- Проблема: При OLAP-нагрузке с отношением read/write 178:1 оба вида кэша критически важны
- Компромисс: Уменьшение shared_buffers освобождает память для кэша ОС, но может снизить HIT RATIO PostgreSQL
- Данные из экспериментов: Shared buffers HIT RATIO всего 55-60% указывает, что 4GB недостаточно для рабочего набора данных
- Рекомендация: Перераспределить память в пользу кэша ОС для лучшего кэширования файлов данных
Своппинг vs. производительность дисков
- Текущая ситуация: Свободной RAM менее 5% в 100% наблюдений вынуждает систему использовать своппинг
- Проблема: При vm.vfs_cache_pressure=500 своппинг значительно увеличился (swap out с 1.8% до 10.9% наблюдений)
- Компромисс: Своппинг сохраняет работоспособность системы, но резко снижает производительность
- Данные из экспериментов: Высокий I/O wait (25-26% в среднем) показывает, что диски уже перегружены OLAP-операциями
- Рекомендация: Минимизировать своппинг любой ценой, даже если это означает отказ от части кэша
Стабильность vs. пиковая производительность
- Текущая ситуация: При pressure=500 система более стабильна (меньше случаев переполнения run queue: 1.8% vs 16.2%)
- Проблема: Эта стабильность достигается за счет увеличения своппинга и снижения общей производительности
- Компромисс: Можно выбрать меньшую пиковую производительность в обмен на предсказуемость
- Данные из экспериментов: Оба варианта показывают одинаково высокий I/O wait, поэтому стабильность при pressure=500 предпочтительнее
- Рекомендация: Для production-систем выбрать настройки, обеспечивающие стабильность, даже с небольшим снижением пиковой производительности
3. Предлагаемые настройки
Оптимальное значение vm.vfs_cache_pressure для данной конфигурации
- Рекомендуемое значение: 75 (между 50 и 100)
- Обоснование:
- При pressure=100: умеренная активность своппинга (1.8% swap out)
- При pressure=500: чрезмерная активность своппинга (10.9% swap out)
- Значение 75 обеспечит баланс между сохранением кэша VFS и освобождением памяти под нужды PostgreSQL
- Почему не 50 или 100:
- Значение 50 может слишком агрессивно сохранять кэш, усугубляя нехватку памяти
- Значение 100 показало приемлемые результаты, но есть пространство для оптимизации
- Значение 75 - разумный компромисс, основанный на данных экспериментов
Настройки vm.dirty_*, swappiness, read_ahead_kb
- vm.swappiness = 5 (снизить с текущих 10):
- Обоснование: При pressure=500 наблюдалось значительное увеличение своппинга
- Цель: Минимизировать склонность к своппингу, учитывая ограниченную RAM
- Компромисс: При нехватке памяти система может завершать процессы OOM killer вместо своппинга
- vm.dirty_background_ratio = 5 (снизить с текущих 10):
- Обоснование: Уменьшить объем данных, накапливаемых перед фоновым сбросом
- Цель: Более частый, но менее интенсивный сброс "грязных" страниц
- Эффект: Снизит пиковую нагрузку на запись, что важно при высоком I/O wait
- vm.dirty_ratio = 15 (снизить с текущих 30):
- Обоснование: Текущие 30% от 8GB = 2.4GB - слишком много для накопления
- Цель: Раньше инициировать блокирующий сброс данных процессов
- Эффект: Уменьшит максимальную задержку операций записи
- vm.dirty_expire_centisecs = 2000 (снизить с 3000 до 20 секунд):
- Обоснование: 30 секунд - слишком долгий период для OLAP с интенсивной записью промежуточных данных
- Цель: Более частая запись данных, даже если не достигнут dirty_ratio
- Эффект: Улучшит согласованность данных и снизит риск потери данных при сбое
- read_ahead_kb = 16384 (увеличить с 4096 до 16MB):
- Обоснование: OLAP характеризуется последовательным чтением больших объемов данных
- Цель: Улучшить предварительное чтение для full table scans и больших JOIN
- Компромисс: Может увеличить нагрузку на диск, но для последовательного чтения это эффективно
Изменения в конфигурации PostgreSQL
- shared_buffers = 2GB (уменьшить с 4GB):
- Обоснование: Текущие 4GB (50% RAM) оставляют недостаточно памяти для кэша ОС
- Данные экспериментов: HIT RATIO 55-60% показывает, что 4GB недостаточно для рабочего набора
- Эффект: Освободит 2GB для кэша ОС, что может улучшить кэширование файлов данных
- work_mem = 64MB (увеличить с 32MB):
- Обоснование: OLAP-запросы часто выполняют сложные сортировки и хэш-агрегации
- Данные экспериментов: Высокая корреляция LWLock-us (0.9775) указывает на конкуренцию за память
- Эффект: Уменьшит количество операций с диском для временных результатов
- effective_cache_size = 5GB (уменьшить с 6GB):
- Обоснование: С учетом уменьшения shared_buffers и общего объема кэша ОС
- Цель: Более реалистичная оценка планировщиком доступного кэша
- Эффект: Улучшит выбор планов запросов, основанных на реальных возможностях кэширования
- maintenance_work_mem = 1GB (увеличить с 512MB):
- Обоснование: Для OLAP важны операции обслуживания (VACUUM, CREATE INDEX)
- Цель: Ускорить операции обслуживания, уменьшив количество проходов по данным
- Компромисс: Временное использование большого объема памяти
- max_parallel_workers_per_gather = 2 (увеличить с 1):
- Обоснование: 8 CPU позволяют распараллеливать некоторые OLAP-операции
- Цель: Ускорение сложных запросов за счет параллельного выполнения
- Компромисс: Увеличит потребление памяти и CPU
Заключение
Рекомендуемые настройки представляют собой сбалансированный подход, основанный на данных экспериментов. Ключевые изменения:
- vm.vfs_cache_pressure = 75 - баланс между кэшированием и доступностью памяти
- Уменьшение shared_buffers до 2GB - перераспределение памяти в пользу кэша ОС
- Уменьшение параметров dirty_* - снижение пиковой нагрузки на запись
- Увеличение read_ahead_kb - оптимизация для последовательного чтения OLAP
Эти настройки должны улучшить ситуацию, но не решат фундаментальную проблему - несоответствие между объемом данных (OLAP) и доступной памятью (8GB). Для значительного улучшения производительности необходимо увеличение RAM до 16-32GB и модернизация дисковых подсистем.
Послесловие
Эксперимент наглядно показал, что агрессивная настройка (vm.vfs_cache_pressure=500) для OLAP-нагрузки ведет к росту своппинга и деградации производительности. Однако выявленные корреляции и парадоксы — не конечная точка, а старт для новых исследований. Оптимальная конфигурация рождается на стыке мониторинга, понимания нагрузки и систематических экспериментов с другими параметрами виртуальной памяти и СУБД.