
В прошлой статье мы разобрались, что такое рекурсия и как она работает в Python. Мы узнали, что рекурсия — это когда функция вызывает сама себя, разбивая большую задачу на более мелкие подзадачи. Познакомились со стеком вызовов — специальным местом в памяти, где хранится информация о каждом вызове функции. А ещё выяснили, что в Python есть ограничение на глубину рекурсии — по умолчанию 1000 вызовов.
Мы научились обходить это ограничение с помощью setrecursionlimit(), но поняли, что это опасно: можно получить ошибки Segmentation Fault или Out of Memory. Это как разгонять машину до 200 км/ч на городских улицах — технически возможно, но не стоит так делать, мягко говоря.
Но что делать, если задача действительно требует глубокой рекурсии? Неужели отказываться от рекурсии вообще?
Нет! Есть гораздо более правильный и безопасный способ — оптимизация рекурсии. И сегодня мы научимся делать рекурсивные функции быстрыми и эффективными.
Проблема избыточных вычислений
Рекурсия может быть красивым и эффективным решением, но у неё есть серьёзная проблема: рекурсивные функции часто выполняют одни и те же вычисления многократно.
Давайте разберём это на примере чисел Фибоначчи — одной из самых известных рекурсивных последовательностей.
Вспомним, как устроена эта последовательность. Каждое число равно сумме двух предыдущих:
F(0) = 0
F(1) = 1
F(n) = F(n-1) + F(n-2)
Получаем последовательность: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34…
Напишем простую рекурсивную функцию:

Выглядит просто и понятно! Всего три строчки. Но давайте посмотрим, что происходит при вызове этой функции.
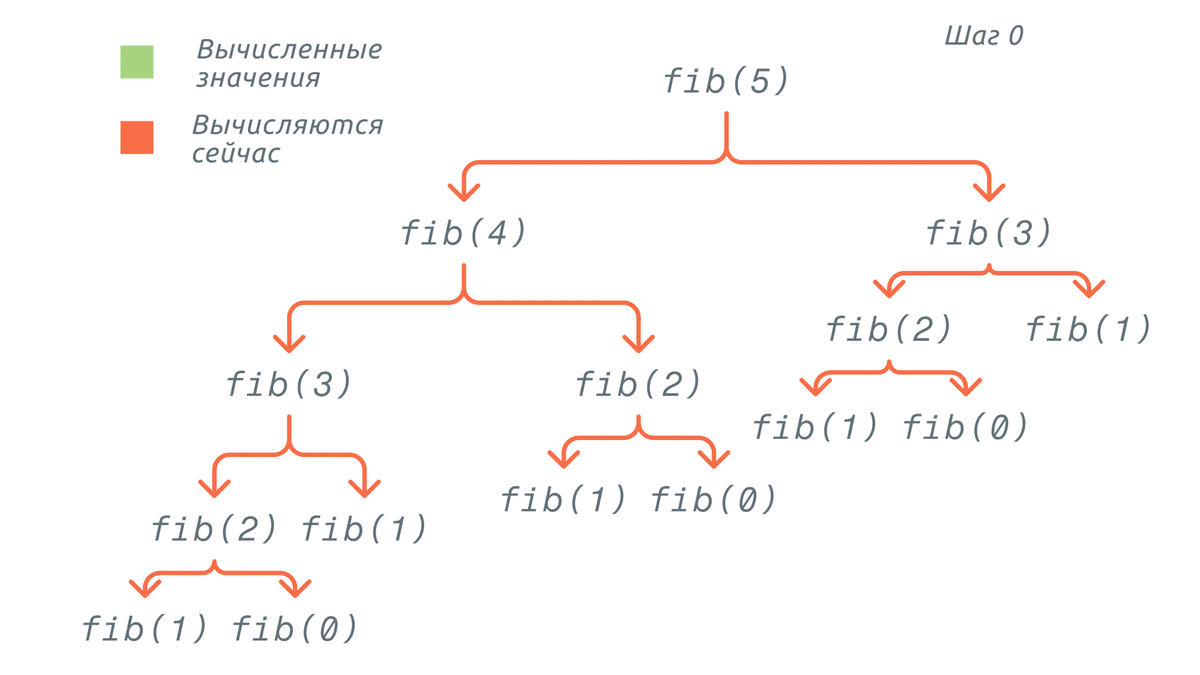
Представим, что мы хотим найти пятый элемент последовательности Фибоначчи. Вызываем fib(5) — для нахождения пятого элемента нам необходимо:
- Определить значение третьего и четвёртого элемента
- Для получения четвёртого элемента требуется найти значение третьего и второго
- Снова определить значение третьего, для чего необходимо повторно найти значение второго и значение первого (оно уже известно и равно 1)
Вызов функции fib(5) можно представить в виде такого дерева:
Обратите внимание на повторения:
- fib(3) вычисляется 2 раза
- fib(2) вычисляется 3 раза
- fib(1) вычисляется 5 раз
- fib(0) вычисляется 3 раза
И это только для пятого элемента! Представьте, что будет с тридцать пятым.
Насколько это медленно? Давайте проверим на практике. Вычислим 35-й элемент ряда Фибоначчи:
На обычном компьютере это займёт несколько секунд! А ведь мы просто складываем числа.
Почему так медленно? Количество вызовов функции растёт экспоненциально:
- fib(10) — 177 вызовов
- fib(20) — 21 891 вызов
- fib(30) — 2 692 537 вызовов
- fib(35) — около 18 миллионов вызовов
- fib(40) — более 331 миллиона вызовов!
Сложность алгоритма: O(2ⁿ) — это катастрофически плохо.
Проблема: мы постоянно вычисляем одни и те же значения снова и снова.
Решение: нужно сохранять уже вычисленные результаты, чтобы не считать их повторно. Эта техника называется кеширование или мемоизация.
Кеширование
Для начала разберёмся, как работает кеширование. Вы с кешем сталкиваетесь каждый день, но при этом можете даже не подозревать о его работе. Разберём самый типичный пример использования кеша — кеширование страниц веб-сайтов.
Когда вы первый раз заходите на сайт, браузер загружает все изображения, видео, стили, скрипты с удалённого сервера. Это может занять несколько секунд. Пока всё загружается, вы видите «заглушки» — серые прямоугольники вместо картинок.
Но при повторном посещении этого же сайта страница загружается мгновенно! Почему?
Браузер сохранил все эти файлы на вашем компьютере в специальное место — кеш. Теперь вместо того, чтобы снова скачивать всё с сервера, браузер просто берёт файлы из кеша.
Или можем рассмотреть такой пример: пользователь запрашивает у приложения какие-то данные из базы данных. Что при этом происходит внутри приложения?
Без кеширования:
- Пользователь нажимает на товар (запрос к приложению)
- Приложение отправляет запрос к базе данных
- База данных ищет информацию
- Данные передаются обратно в приложение
- Приложение показывает информацию пользователю
Всё это может занять 1-2 секунды.
С кешированием:
- Пользователь нажимает на товар
- Приложение проверяет: «А может, я уже загружал эту информацию?»
- Если да — сразу показывает из кеша (порядка 0,01 секунды)
- Если нет — загружает из базы и сохраняет в кеш
При повторном обращении к тому же товару ответ приходит мгновенно.
Теперь мы готовы дать определение термину «кеширование». Кеширование — это техника ускорения доступа к данным путём их временного хранения в быстродоступном месте.
Основная идея:
- При первом обращении — получаем данные из медленного источника и сохраняем в кеше
- При повторном обращении — берём данные из кеша (это быстро!)
- Экономим время и ресурсы
Мемоизация
Мемоизация — это частный случай кеширования, который применяется для оптимизации вычислений в функциях.
Простыми словами: если функция с одними и теми же аргументами всегда возвращает один и тот же результат, зачем вычислять его заново? Можно просто запомнить результат при первом вызове и потом брать из памяти.
Давайте применим мемоизацию к нашей функции вычисления чисел Фибоначчи.
Идея:
- Мы будем добавлять в кеш (в нашем случае — просто в словарь) значения уже вычисленных элементов
- Получается, что мы доходим до вызова функции fib(0) и добавляем её результат в словарь
- Аналогично будет и с fib(1)
- Далее для вычисления значения fib(2) мы уже не будем вызывать функции fib(1) и fib(0), а просто возьмём значения из нашего словаря
И так будем проделывать с каждым вызовом вплоть до нужного значения. Таким образом, значительно снизим не только количество вызовов функций, но и время выполнения всей программы. Весь этот процесс проиллюстрирован ниже:
Давайте реализуем это в коде. Алгоритм у нас будет следующий:
- Создание кеша. В нашем случае это будет просто словарь, в который мы помещаем результаты работы функций. Ключами в словаре будут аргументы функции.
- Проверка кеша. При вызове функции проверяем, есть ли в словаре значение с ключом, равным аргументу функции.
- Если значение в кеше найдено – возвращаем его. Если нет, то вычисляем.
- После вычисления возвращаем полученное значение, перед этим сохранив его в кеше.
Получаем такую программу:
Разница колоссальная! Вместо нескольких секунд — доли миллисекунды.
Почему так быстро? Потому что теперь каждое число Фибоначчи вычисляется ровно один раз. Вместо 18 миллионов вызовов — всего 35!
Встроенные инструменты Python для кеширования
Мы научились делать кеширование вручную, но это не очень удобно. Нужно создавать словарь, проверять его, сохранять результаты… Много кода.
К счастью, в Python уже есть готовые инструменты для кеширования! Они находятся в модуле functools.
functools — это встроенный модуль Python, который содержит полезные утилиты для работы с функциями.
Вот некоторые из них:
Для кеширования:
- @lru_cache — декоратор для кеширования с LRU-стратегией
- @cache (Python 3.9+) — упрощённая версия без ограничения размера
Для работы с функциями:
- wraps — сохраняет метаданные при создании декораторов
- partial — создаёт новые функции с частично применёнными аргументами
- reduce — применяет функцию ко всем элементам последовательности
Сейчас мы сосредоточимся на @lru_cache — готовом декораторе для мемоизации
Декораторы
Прежде чем использовать @lru_cache, нужно понять, что такое декоратор.
Декоратор — это специальная функция, которая изменяет поведение другой функции, не меняя её код.
Представьте, что у вас есть обычная функция:
А теперь вы хотите, чтобы она выводила время вызова. Можно переписать функцию, добавив туда код с временем. А можно использовать декоратор!
Слишком сложно? Тогда не переживайте, все, что нужно усвоить, так это что нам нужно писать символ @ перед названием функции-декоратора. В нашем случае такой функцией будет lru_cache.
Значит перед той функцией, к которой нужно применить кеширование (lru_cache) мы пишем: @lru_cahce.
Декоратор @lru_cache
@lru_cache — это готовый декоратор из модуля functools, который автоматически добавляет кеширование к любой функции.
Что означает LRU?
LRU расшифровывается как Least Recently Used (наименее недавно использованный).
Это стратегия управления кешем. Представьте, что у вас есть полка на 10 книг (кеш на 10 элементов). Когда полка заполнится и вам нужно поставить новую книгу, какую старую убрать?
LRU-стратегия говорит: убирай ту книгу, которую дольше всего не брали.
Это логично, ведь если книгу давно не читали, скорее всего, она и дальше никому уже не понадобится. А часто используемые книги останутся на полке.
Так же работает и @lru_cache:
- Сохраняет результаты функций в кеше
- Когда кеш заполняется, удаляет самые старые неиспользуемые результаты
- Часто используемые результаты остаются в кеше
Теперь давайте опробуем декоратор @lru_cache в деле. Самый простой способ — просто добавить декоратор к функции:
Всё! Теперь функция автоматически кеширует свои результаты. Никаких словарей, никаких проверок — Python делает всё за вас.
Проверим скорость:
Не так быстро, как наш самописный способ кеширования, но тоже неплохо!
Параметры @lru_cache
Декоратор @lru_cache можно настраивать с помощью двух параметров: maxsize и typed.
Параметр maxsize (по умолчанию 128) — максимальное количество сохранённых результатов в кеше.
Когда кеш заполняется, самые старые неиспользуемые результаты удаляются, чтобы освободить место для новых.
Важные моменты:
- Степень двойки: рекомендуется устанавливать maxsize как степень двойки (128, 256, 512, 1024) для оптимальной производительности. Python использует битовые операции для ускорения доступа к кешу.
- None = бесконечный кеш: если установить maxsize=None, кеш будет расти неограниченно. Это может привести к проблемам с памятью при длительной работе или большом количестве уникальных аргументов.
- Баланс: больший кеш = больше памяти, но меньше пересчётов. Меньший кеш = меньше памяти, но больше пересчётов.
Параметр typed (по умолчанию False) — различать ли типы данных при кешировании. По умолчанию Python считает 1 и 1.0 одинаковыми значениями (математически они равны). Но если установить typed=True, они будут кешироваться отдельно.
Выводы
В этой статье мы научились оптимизировать рекурсивные функции. Вспомнили, что главная проблема рекурсии — это избыточные вычисления. А избежать таких вычислений можно с помощью мемоизации — сохранения результатов вызовов функции.
А, чтобы не писать вручную алгоритм мемоизации, мы научились использовать специальный декоратор — @lru_cache. Именно его мы и будем применять в решениях 16 заданий ЕГЭ.
Кстати о них, теперь вы готовы просто и результативно решать эти задания. И в следующих статьях мы разберём типы 16 заданий и выведем шаблонные алгоритмы для их решения.