⚡️ ERNIE 5.0 - официальный релиз.
Baidu выкатили нативную omni-modal модель, которая умеет понимать и генерировать текст, изображения и аудио.
Ключевая фишка архитектуры - MoE на 2,4 трлн параметров, но в каждом запросе активируется менее 3% параметров.
То есть модель пытается держать качество “больших” систем, но с более эффективным инференсом по стоимости и скорости.
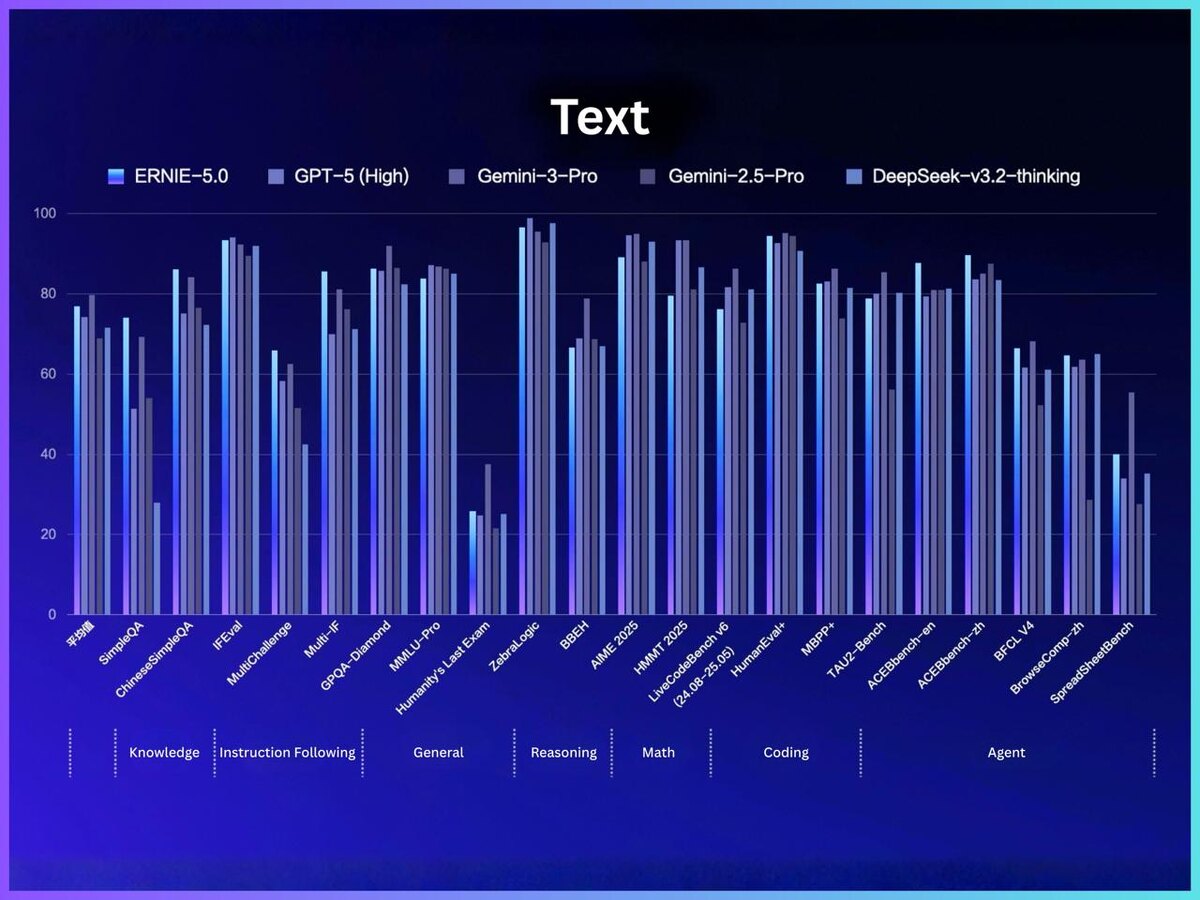
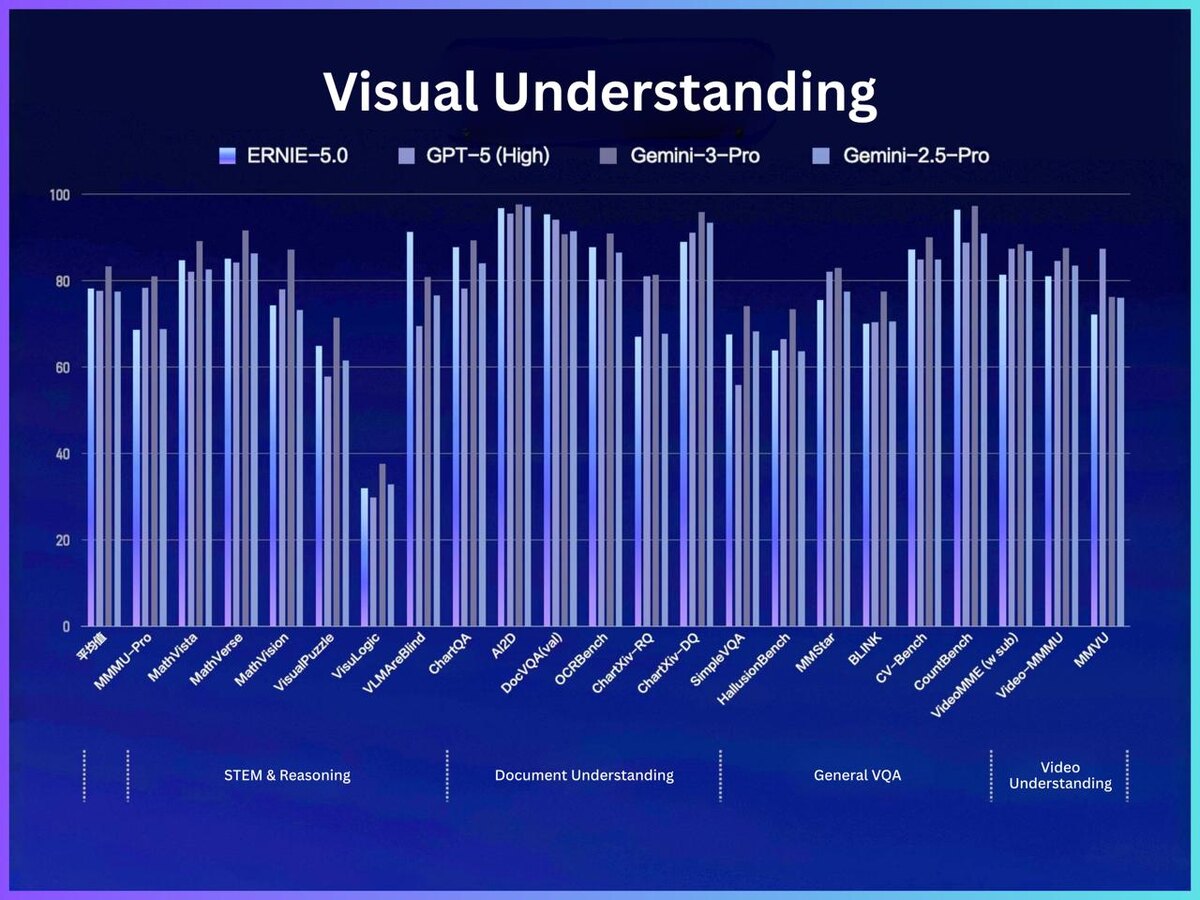
Самое интересное - результаты на бенчмарках (по графикам Baidu):
- Text: ERNIE-5.0 уверенно держится в топ-группе на широком наборе тестов по знаниям, инструкциям, reasoning, математике и коду - на многих метриках близко к GPT-5 (High) / Gemini-3-Pro, а местами выглядит сильнее (особенно на части задач по кодингу и агентным бенчмаркам типа BFCL / BrowserComp / SpreadsheetBench).
- Visual Understanding: по “пониманию картинок” ERNIE-5.0 в ряде STEM/VQA тестов идёт очень высоко - рядом с GPT-5 (High) и Gemini-3-Pro, хорошо выступает на DocVQA/OCR-подобных задачах (документы, таблицы, текст на изображениях) и на блоке General VQA.
- Audio: в speech-to-text chat и audio understanding ERNIE-5.0 показывает конкурентный уровень рядом с Gemini-3-Pro, а по распознаванию речи (ASR) близко к топам на LibriSpeech / AISHELL.
- Visual Generation: по генерации изображений (GenEval) ERNIE-5.0 сравнивают с топовыми генераторами уровня GPT-Image, Seedream, Qwen-Image - и ERNIE выглядит на одном уровне по total score. По генерации видео - рядом с Veo3 / Wan2.1 / Hunyuan Video, с сильными Quality/Semantic оценками.
Baidu делает ставку на “унифицированную мультимодальность” + MoE-эффективность - и судя по бенчмаркам, ERNIE 5.0 реально попадает в верхнюю лигу не только по тексту, но и по vision/audio.
Доступно:
- на сайте ERNIE Bot
- через Baidu AI Cloud Qianfan (для бизнеса и разработчиков)