
Катастрофоустойчивость ИТ-инфраструктуры является одним из ключевых направлений управления ИТ-услугами и напрямую связана с обеспечением непрерывности бизнеса. Важно различать такие понятия, как инцидент и катастрофа.
Инцидентом считается любое нарушение или ухудшение работы сервиса, которое можно устранить в пределах существующей инфраструктуры — например, отказ базы данных, сбой сервера или сетевого оборудования. Даже если инцидент критичен и затрагивает большое количество пользователей (инцидент наивысшей критичности), он всё же остаётся в зоне локального восстановления.
Катастрофой же называют событие, при котором сервисы невозможно восстановить на текущей площадке, и требуется задействование альтернативных ресурсов или резервного дата-центра. Для эффективного противодействия катастрофам необходимо выстроить отказоустойчивую инфраструктуру.
В данной статье мы рассмотрим основные аспекты построения отказоустойчивой ИТ-инфраструктуры для 1С. Сначала определим возможные угрозы, затем разберём роль и структуру DRP-плана (Disaster Recovery Plan) как стратегического документа, определяющего порядок действий в случае катастрофы. Далее рассмотрим варианты построения катастрофоустойчивой инфраструктуры. Отдельно опишем технологии, применяемые для обеспечения отказоустойчивости на уровне гипервизора и на уровне приложений. Также подробно рассмотрим процесс резервного копирования, поскольку временная остановка сервисов без потери данных является менее критичным инцидентом, чем безвозвратная утрата этих данных. Таким образом, статья даст целостное понимание того, какие инструменты и подходы позволяют минимизировать риски простоев и обеспечить сохранность критически важных данных даже в случае катастрофы.
Перечень угроз
К угрозам, которые классифицируются как катастрофические, относят широкий спектр событий.
Физические разрушения. Пожары, наводнения, землетрясения, аварии на инженерных сетях, которые могут вывести из строя дата-центр или коммуникационное оборудование.
Технические сбои. Массовый выход из строя серверов, СХД, сбои в энергоснабжении, полное падение сети, отключение магистральных каналов интернета.
Киберинциденты. Из наиболее актуальных на сегодняшний день: масштабные DDoS-атаки, шифровальщики, хакерские взломы. Тема сейчас особенно актуальна, поскольку атакам подвергаются не только крупные компании, но и все организации, имеющие уязвимости, независимо от их размера и отрасли.
Человеческий фактор. Критические ошибки администрирования, умышленные действия инсайдеров, саботаж.
Все эти сценарии объединяет общий признак: последствия катастрофы затрагивают ключевые ИТ-сервисы и бизнес-процессы, и без заранее разработанного плана восстановления и подготовленной резервной инфраструктуры организация рискует понести существенные финансовые и репутационные потери.
План аварийно-восстановительных работ (Disaster Recovery Plan)
Disaster Recovery Plan (DRP) — это документированный план действий организации на случай катастрофы, связанной с ИТ-инфраструктурой. Его основная задача — минимизировать последствия аварий, сократить время простоя и обеспечить восстановление критически важных сервисов в приемлемые сроки.
ЗАЧЕМ НУЖЕН DRP-ПЛАН?
- обеспечивает структурированный порядок действий;
- дает четкое понимание сроков восстановления сервисов;
- позволяет снизить риск ошибок и паники при восстановлении сервисов;
- определяет ресурсы и ответственных лиц, необходимые для восстановления.
ЧТО ДОЛЖНО БЫТЬ ОПИСАНО В DRP?
- Схема резервирования сервисов. Описание основной и резервной площадки и механизмов резервирования. Перечень ролей и сервисов, которые зарезервированы на случай катастрофы.
- Перечень ответственных сотрудников.
- Приоритеты восстановления — какие системы должны быть запущены первыми.
- RTO и RPO — допустимые сроки восстановления (Recovery Time Objective) и точки восстановления данных (Recovery Point Objective). RPO показывает предельно допустимый период за который могут быть потеряны данные.
- Порядок активации DRP — условия и процедура запуска плана. Необходимо для понимания, при каких условиях прекращается попытка восстановления сервисов на текущей площадке и начинается переключение на резерв.
- Коммуникационный план — порядок уведомления сотрудников, клиентов, поставщиков.
- Процедура тестирования — план проведения учений по тестовому переключению на резервную площадку.
МЕРОПРИЯТИЯ В РАМКАХ DRP:
- настройка и регулярная проверка резервного копирования;
- репликации данных между основной и резервной площадкой;
- автоматический мониторинг резервных копий и состояния репликации;
- подготовка инструкций и чек-листов для систем и сервисов;
- проведение учений и тестов DRP.
Технологии обеспечения катастрофоустойчивости
Для обеспечения катастрофоустойчивости ИТ-инфраструктуры ключевым элементом является репликация данных на резервную площадку. Существует два основных подхода: репликация на уровне виртуализации и репликация на уровне приложений. Оба варианта имеют свои особенности, преимущества и ограничения.
РЕПЛИКАЦИЯ НА УРОВНЕ ВИРТУАЛИЗАЦИИ
В этом подходе все серверные роли размещаются на виртуальных машинах, работающих под управлением гипервизоров. Далее настраивается репликация виртуальных машин на резервную площадку, где в случае катастрофы они могут быть оперативно запущены.
Например:Microsoft Hyper-V Replica – встроенная технология в Windows Server, позволяющая реплицировать ВМ на другой сервер или кластер.
VMware vSphere Replication – инструмент для репликации виртуальных машин в среде VMware.
Veeam Backup & Replication – стороннее решение, поддерживающее репликацию и восстановление в средах VMware и Hyper-V.
РЕПЛИКАЦИЯ НА УРОВНЕ ПРИЛОЖЕНИЙ
Второй подход заключается в использовании встроенных механизмов репликации самих приложений. Здесь данные синхронизируются не на уровне виртуальной машины целиком, а на уровне конкретных сервисов.
Например:Кластеризация Active Directory. Реализуется встроенными инструментами Windows Server. Microsoft SQL Server – поддерживает зеркалирование баз данных, Always On. Основные компоненты Always On:Primary Replica (основной экземпляр). Все операции записи и чтения выполняются здесь. Данные c нее реплицируются на вторичные реплики.
Secondary Replica (вторичный экземпляр). Принимает изменения и может быть задействована в случае катастрофы.
Windows Failover Cluster. Встроенный функционал Windows Server, используется для координации и автоматического переключения ролей между репликами.
Listener. Виртуальная точка подключения для приложений. При переключении на другую реплику клиентские приложения продолжают работать, подключаясь к тому же имени/адресу. Схема работы показана на рисунке ниже.
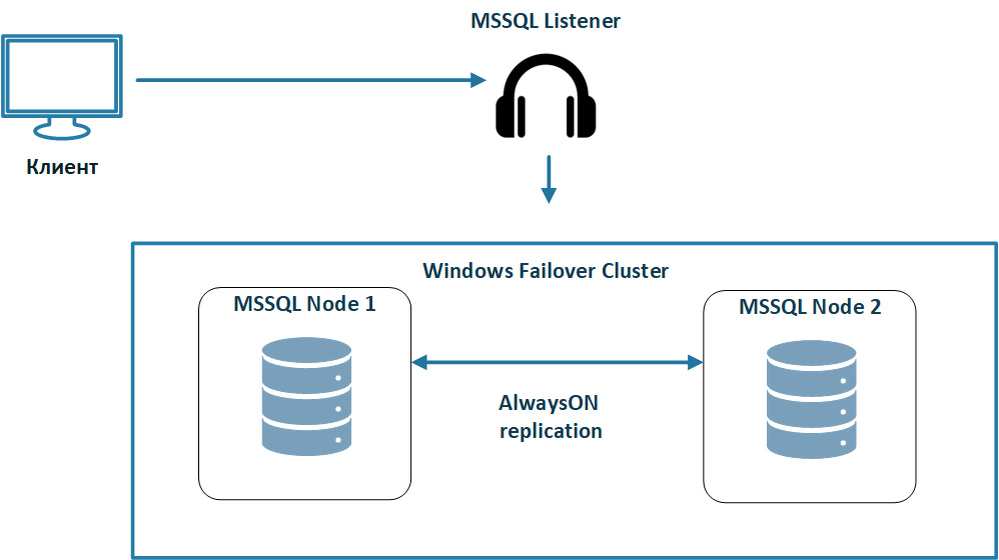
Рисунок 1 – Схема репликации MSSQL.
PostgreSQL – реализует потоковую репликацию (Streaming Replication). Механизм похож на работу Always ON, но реализация требует сторонних компонентов. В нашем примере для управления отказоустойчивым кластером используется надстройка Patroni. Стоит отметить, что для хранения конфигурации кластера также необходимо внешнее хранилище, в нашем случае используем etcd и функционал слушателя (Listener) в случае с PostgreSQL выполняет HAProxy. Получаем схему, которая показана ниже:
Рисунок 2 – Схема репликации PostgreSQL.
Почтовые системы (например, Microsoft Exchange) – поддерживают DAG (Database Availability Groups). Копии почтовых баз распределяются по серверам в двух (или более) ЦОДах. Если выходит из строя сервер или полностью датацентр – база активируется во втором датацентре. Поверх DAG всегда нужен Load Balancer, чтобы клиенты подключались к актуальному ЦОДу.
Рисунок 3 – Схема работы DAG Exchange.
Отказоустойчивый кластер 1C. Реализуется встроенными средствами 1С. Приложение 1С:Предприятие взаимодействует с СУБД для хранения данных. Механизм резервирования СУБД зависит от выбранной системы и был описан выше для MSSQL и для PostgreSQL. Схема репликации 1С на рисунке ниже:
Рисунок 4 – Схема репликации 1С:Предприятия.
Также много приложений кластерезируются простой синхронизацией данных. Т.е. приложения устанавливаются на обе площадки и происходит синхронизация файлов между ними.
ПараметрРепликация на уровне виртуализацииРепликация на уровне приложенийОсновные преимуществаБолее простая настройка. Более простой мониторинг. Экономия на лицензиях.Быстрое переключение на резерв. Минимизация возможной потери данных. Минимальная нагрузка на канал интернета.RTOОт 30 минут, в зависимости от количества виртуальных машин и занимаемый ресурсов.От 0 секунд до нескольких минут.RPOОт 30 секунд до 15 минут. Выбор частоты синхронизации также зависит от интернет канала и количества изменяемых данных.От 0 секунд до нескольких минут. Данные могут писаться одновременно на обе площадки, поэтому потери данных не происходит, но в некоторых случаях применяется асинхронная кластеризация, в этом случае будут потери последних транзакций.
Таблица 2 – Сравнение подходов к репликации данных.
Как видим при выборе подхода к репликации необходимо ориентироваться на требования клиента, потребности бизнеса и бюджет. Также на практике часто встречается использование разных подходов для репликации разных сервисов. Например, основные сервисы такие как СУБД, сервер приложений могут дублировать на уровне гипервизора, а такие как Active Directory и почтовый сервер кластеризирются на уровне приложений.
Резервное копирование
Данный пункт выделен отдельно, поскольку отсутствие резервных копий при потере данных наносит несоизмеримо больший ущерб, чем остановка работы сервисов компании.
ПОДХОД К АРХИТЕКТУРЕ СИСТЕМЫ РЕЗЕРВНОГО КОПИРОВАНИЯ
В первую очередь стоит обратить внимание на построение архитектуры. Основные классические принципы такие:
- выделенное хранилище для резервных копий. Хранить бекапы необходимо отдельно от рабочей среды;
- доступ к хранилищу резервных копий происходит под отдельной учетной записью. Если будут скомпрометированы учетные записи имеющие доступ к данным – доступа к резервным копиям все равно не будет;
- использование малоуязвимых защищенных операционных систем на хранилищах резервных копий. рекомендуется использовать минималистичные и безопасные дистрибутивы Linux;
- географическое распределение резервных копий. Отправка резервных копий на несколько удаленных площадок;
- использование оффлайн носителей для хранения резервных копий. Иногда целесообразно хранить копии информации оффлайн. Если требуется длительное хранение больших объемов данных, целесообразно использовать специализированные ленточные накопители;
- использование минимум 2-х разных инструментов для резервного копирования. В случае отказа или ошибки резервной копии сделанной одним инструментов останется копия сделанная альтернативным способом. Например, одним инструментом может быть копия всего сервера или виртуальной машины, а вторым встроенный инструмент прикладного ПО.
ПАРАМЕТРЫ РЕЗЕРВНОГО КОПИРОВАНИЯ
При настройке планов резервного копирования основные вот две опции, на которые стоит обратить внимание:
- частота резервных копий. Периоды времени через которые делается резервная копия;
- глубина хранения. Период времени на протяжении которого хранятся резервные копии и не перезаписываются.
Естественно чем чаще делаются копии и чем дольше хранятся – тем лучше, но это требует и дополнительных ресурсов.
Для того чтобы восстановить информации в случае сбоя достаточно наличие хотя бы одной свежей резервной копии. Но существует много ситуаций, когда потеря данных вскрывается не сразу, поэтому копии делаются периодически и имеют глубину хранения.
МОНИТОРИНГ И ВЕРИФИКАЦИЯ
Необходимо не только делать резервные копии, но и быть уверенным, что с них восстановятся данные. Для этого должен быть настроен следующий мониторинг:
- доступность бекап-сервера;
- наличие места для резервных копий;
- наличие места на исходном сервере для временной копии, если это необходимо;
- наличие ошибок в ПО с помощью которого делаются копии;
- проверка размера новой копии;
- проверка даты последней копии.
Помимо мониторинга необходимо также проводить периодические аудиты резервных копий, которые должны включать тестовое восстановление и проверку данных. Таким образом будет исключена ситуация, когда копия по всем параметрам должна была восстановиться, но каким-то образом была повреждена.