Или как кириллица ломала компьютеры и почему КОИ-8, CP1251 и UTF-8 воевали за каждый байт

Вчера племянник получил email: текст превратился в кракозябры — "Ïðèâåò! Êàê äåëà?" вместо "Привет! Как дела?"
Он ругался: «Дед, опять эти кодировки! Почему в 2026 году до сих пор текст ломается?!»
Я усмехнулся: «Потому что это наследие 60-летней войны. ASCII против всего мира. Победил Unicode, но раны остались».
Он не понял: «Война кодировок? Какая война?»
Я встал. Достал папку «Character Encoding Standards. 1963-2010. ASCII / KOI-8 / CP1251 / Unicode».
Открыл на странице с таблицей ASCII (1963 год):
Символов: 128
Языки: только английский
Кириллица: НЕТ
Китайский: НЕТ
Арабский: НЕТ
Показал племяннику: «Вот корень проблемы. В 1963 году американцы создали ASCII — стандарт кодирования текста. Для АНГЛИЙСКОГО. Весь остальной мир не влез».
Потом открыл следующую страницу — таблица Unicode (2025):
Символов: 149,186
Языки: ВСЕ (включая мёртвые)
Эмодзи: ДА
«Вот победитель войны. Unicode. Но дорога к нему заняла 30 лет, 6 конкурирующих стандартов и миллионы сломанных текстов».
ASCII: когда американцы создали стандарт только для себя
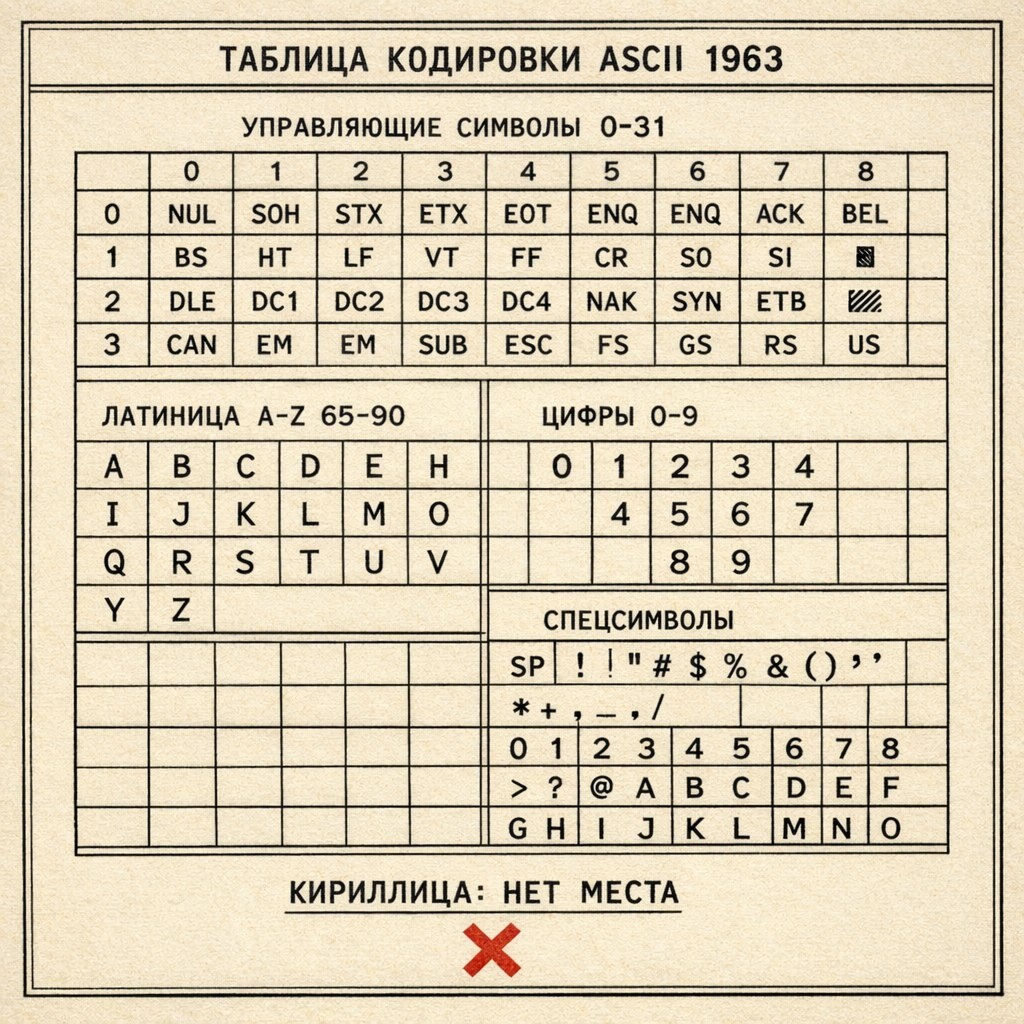
ASCII (American Standard Code for Information Interchange) — стандарт кодирования символов, созданный в США.
РАЗРАБОТКА: 1963 год, American Standards Association (ASA, позже ANSI)
ЦЕЛЬ: Унифицировать представление текста в компьютерах и телеграфах
ПОЧЕМУ 7 БИТ (128 СИМВОЛОВ):
Технические ограничения 1960-х:
- Память дорогая (1 байт = большая роскошь)
- Хотели уложиться в 7 бит (128 вариантов), чтобы экономить память
- 8-й бит использовали для проверки чётности (контроль ошибок передачи)
ЧТО ПОМЕСТИЛОСЬ В ASCII:
0-31: Управляющие символы
- Не печатаются, управляют устройствами
- Примеры: LF (перевод строки), CR (возврат каретки), BEL (звонок), ESC (escape)
32-64: Цифры и символы
- Пробел, ! " # $ % & ' ( ) * + , - . /
- Цифры 0-9
- Символы : ; < = > ? @
65-90: Заглавные латинские буквы
- A B C D E F G ... Z
97-122: Строчные латинские буквы
- a b c d e f g ... z
123-127: Дополнительные символы
- { | } ~ DEL
ИТОГО: 128 символов.
ПРОБЛЕМА:
КИРИЛЛИЦА НЕ ВЛЕЗЛА.
Также не влезли:
- Китайские иероглифы (тысячи символов)
- Арабская вязь
- Греческий алфавит
- Иврит
- Любые диакритические знаки (ä, é, ñ, ü...)
ASCII = стандарт только для английского.
Война кодировок: как каждая страна создала свою кириллицу
Племянник спросил: «Дед, но как же СССР использовал компьютеры? Без кириллицы же невозможно!»
Я вздохнул: «Создали СВОЮ кодировку. И не одну. КОИ-8, КОИ-7, CP1251, CP866, ISO 8859-5... Каждый стандарт несовместим с другими. Открываешь текст не в той кодировке — получаешь кракозябры».
РАСШИРЕННЫЕ КОДИРОВКИ (8 БИТ = 256 СИМВОЛОВ):
Идея:
- Используем 8-й бит (вместо контроля чётности)
- Получаем 256 символов (вместо 128)
- Первые 128 = ASCII (совместимость)
- Вторые 128 = национальные символы
НО:
Каждая страна/компания создала СВОЮ таблицу для символов 128-255.
РЕЗУЛЬТАТ: ХАОС.
ОСНОВНЫЕ КОДИРОВКИ ДЛЯ КИРИЛЛИЦЫ:
1. KOI-8 (Код Обмена Информацией, 8-бит)
- СССР, 1970-е
- Кириллица в кодах 192-255
- Порядок букв: А=192, Б=193, В=194...
- Особенность: если отбросить 8-й бит (превратить в 7-бит) → кириллица превращается в фонетически похожую латиницуПример: русская "А" (код 192 = 11000000) → латинская "A" (код 64 = 01000000)
"Привет" → "Privet" (если убрать старший бит)
Зачем это нужно:
- Старые 7-битные телеграфные линии отбрасывали 8-й бит
- KOI-8 делала текст читаемым (хоть и латиницей) даже на старых линиях
2. CP866 (Code Page 866, DOS)
- IBM/Microsoft, 1980-е
- Для MS-DOS (операционная система ПК)
- Кириллица в кодах 128-175 и 224-255
- Несовместима с KOI-8!
3. CP1251 (Windows-1251)
- Microsoft, 1990-е
- Для Windows
- Кириллица в кодах 192-255
- Несовместима с KOI-8 и CP866!
4. ISO 8859-5
- Международный стандарт ISO
- Попытка унификации
- Почти никто не использовал (все уже привыкли к KOI-8 или CP1251)
5. Mac Cyrillic
- Кодировка Apple для Mac OS
- Несовместима со всеми остальными
ИТОГО:
5+ несовместимых кодировок для русского языка.
ПРОБЛЕМА:
- Написал текст в KOI-8 → открыл в CP1251 → КРАКОЗЯБРЫ
- Email из СССР (KOI-8) → получатель в Windows (CP1251) → НЕЧИТАЕМО
ПРИМЕР КРАКОЗЯБР:
Оригинальный текст (KOI-8): "Привет!"
Открыт в CP1251: "рТЙЧЕФ!"
Открыт в CP866: "╧@825B!"
ХАОС.
Unicode: как мир договорился об одном стандарте
UNICODE — УНИВЕРСАЛЬНЫЙ СТАНДАРТ:
СОЗДАНИЕ: 1991 год, Unicode Consortium (международная организация)
ЦЕЛЬ: Один стандарт для ВСЕХ языков мира
ПРИНЦИП:
- Каждому символу — уникальный номер (code point)
- Не 128, не 256, а миллионы возможных символов
ПРИМЕРЫ:
- Латинская "A" = U+0041
- Кириллическая "А" = U+0410
- Китайский иероглиф "中" = U+4E2D
- Эмодзи "😀" = U+1F600
КОДИРОВКИ UNICODE:
Unicode — это таблица символов (абстрактная).
Для ХРАНЕНИЯ в файлах используют кодировки:
1. UTF-32
- Каждый символ = 4 байта (32 бита)
- Простая, но расточительная (английский текст занимает в 4 раза больше места)
- Почти не используется
2. UTF-16
- Каждый символ = 2 или 4 байта
- Используется в Windows (внутри системы)
- Средняя эффективность
3. UTF-8 (ПОБЕДИТЕЛЬ)
- Переменная длина:ASCII символы (латиница, цифры) = 1 байт (совместимость с ASCII!)
Кириллица = 2 байта
Китайские иероглифы = 3 байта
Редкие символы/эмодзи = 4 байта
Преимущества:
- Обратная совместимость с ASCII (старые программы работают)
- Экономичная (английский текст не раздувается)
- Универсальная (поддерживает всё)
СТАТУС (2025):
- 98%+ веб-страниц используют UTF-8
- UTF-8 = фактический стандарт интернета
Почему до сих пор бывают кракозябры
Племянник: «Дед, но если Unicode победил, почему мой email сломался?»
Я вздохнул: «Потому что СТАРЫЕ системы всё ещё живы. И они не знают про Unicode».
ПРИЧИНЫ КРАКОЗЯБР (2026):
1. Старые почтовые серверы
- Настроены на CP1251 (1990-е)
- Получают UTF-8 → не понимают → показывают кракозябры
2. Старые базы данных
- Созданы в 2000-х с кодировкой Latin1
- Хранят русский текст в неправильной кодировке → при выводе = кракозябры
3. Неправильные настройки
- Программист забыл указать charset=UTF-8 в HTML
- Браузер пытается угадать → угадывает неправильно
4. Легаси-системы
- Банки, государственные сайты используют софт 1990-2000-х
- Переписать = дорого → оставляют старые кодировки
РЕШЕНИЕ:
- Мигрировать всё на UTF-8
- Но это дорого и долго
Поэтому кракозябры будут ещё лет 10-20.
Мой опыт: 30 лет борьбы с кодировками
1990-е: НАЧАЛО КОШМАРА
- Работаю программистом
- Получаю текстовые файлы от коллег
- Каждый файл — в своей кодировке (KOI-8, CP866, CP1251)
- Перед чтением → угадываю кодировку (открываю в блокноте, смотрю кракозябры, пробую другую кодировку)
- Теряю часы на конвертацию
2000-е: ИНТЕРНЕТ УСУГУБЛЯЕТ
- Email от русских коллег → KOI-8
- Email от европейских → ISO-8859-1
- Китайцы пишут → GB2312
- Каждое письмо — лотерея (откроется или нет)
2010-е: ПЕРЕХОД НА UTF-8
- Начал принудительно использовать UTF-8 во всех проектах
- Коллеги сопротивлялись: «У меня в 1251 работает! Зачем менять?»
- Объяснял: «Потому что завтра придёт китайский партнёр — и ваш текст сломается»
2020-е: ПОЧТИ ПОБЕДА
- 95% проектов на UTF-8
- Но старые базы данных до сих пор в CP1251
- Миграция = риск (могут сломаться данные)
СТАТИСТИКА МОИХ ПОТЕРЬ:
- ~500 часов потрачено на конвертацию кодировок (за 30 лет)
- ~100 файлов потеряно навсегда (сломались при конвертации, резервных копий не было)
Курилка: вопрос читателям
Племянник сказал: «Дед, получается американцы создали ASCII только для себя — и весь мир страдал 30 лет?»
Я кивнул: «Да. Это классический пример технологического империализма. Кто создаёт стандарт первым — навязывает его всем».
Вопрос в курилку:
Справедливо ли, что один язык (английский) стал основой компьютеров?
ASCII (1963):
- Создан американцами для американцев
- Кириллица, китайский, арабский не влезли
- Половина мира не могла нормально работать с компьютерами
Unicode (1991):
- Создан международным консорциумом
- Включает все языки (даже мёртвые)
- Справедливо, но пришёл на 30 лет позже
Последствия задержки:
- 30 лет хаоса (война кодировок)
- Миллионы сломанных текстов
- Потерянные документы
Что если бы Unicode создали в 1963?
- Компьютеры сразу поддерживали бы все языки
- Не было бы войны кодировок
- Интернет развивался бы быстрее (не тратили время на конвертации)
Но тогда:
- Память дорогая → UTF-8 был бы слишком расточительным
- Технология не готова
Второй вопрос:
Может, технологические стандарты должны быть международными с самого начала?
Сейчас:
- Большинство стандартов создаются в США (Silicon Valley)
- Потом навязываются миру
- Остальные страны адаптируются
Альтернатива:
- Стандарты создаются международными организациями (как Unicode Consortium)
- Учитывают потребности всех стран
Но это медленнее (нужен консенсус между странами).
Что лучше: быстро (но несправедливо) или медленно (но для всех)?
Связь обрывается, но данные остаются.
Ваш Линкин
P.S.
Племянник спросил: «Дед, а как ты восстанавливал сломанные тексты?»
Я усмехнулся: «Писал скрипты. Пробовал все кодировки подряд, искал ту, где текст становится читаемым».
«Но иногда тексты проходили через 2-3 конвертации».
Пример:
- Оригинал: KOI-8
- Кто-то открыл в CP1251 → сохранил (кракозябры)
- Потом в UTF-8 → сохранил (кракозябры от кракозябр)
Результат: Необратимо сломано.
Я видел документы, которые прошли через 5 конвертаций.
Текст превратился в нечитаемую кашу.
Восстановить невозможно.
Война кодировок убила культурное наследие.
Письма, статьи, документы 1990-х — многие потеряны навсегда.
Железо помнит. Кодировки тоже. ASCII был ошибкой. Unicode — искупление.