Или как IBM 701 переводил русский на английский — и почему технология застряла на десятилетия

Вчера племянник хвастался: «Дед, смотри! Google Translate переводит мгновенно! Даже с камеры — навёл на вывеску, и она переведена! ИИ-революция!»
Диктор в видео: «Нейросети впервые в истории научились переводить тексты автоматически...»
Я усмехнулся: «Впервые? В 2020-х? А Georgetown-IBM эксперимент 1954 года не считается?»
Он удивился: «1954? Машинный перевод тогда был?»
Я встал. Достал папку «Georgetown University / IBM. Machine Translation Experiment. January 7, 1954».
Открыл на странице с распечаткой:
Входной текст (русский, на перфокартах):
"Качество угля определяется калорийностью"
Выходной текст (английский, напечатан IBM 701):
"QUALITY OF COAL IS DETERMINED BY CALORY CONTENT"
Дата: 7 января 1954 года
Словарь: 250 слов
Грамматических правил: 6
Точность: ~70% для простых фраз
Показал племяннику: «Вот твоя "революция нейросетей". Только это 1954 год. За 72 года до того, как Google "изобрёл" машинный перевод. И это работало на компьютере размером с комнату».
Georgetown-IBM: когда США показали СССР "мы можем читать ваши документы"
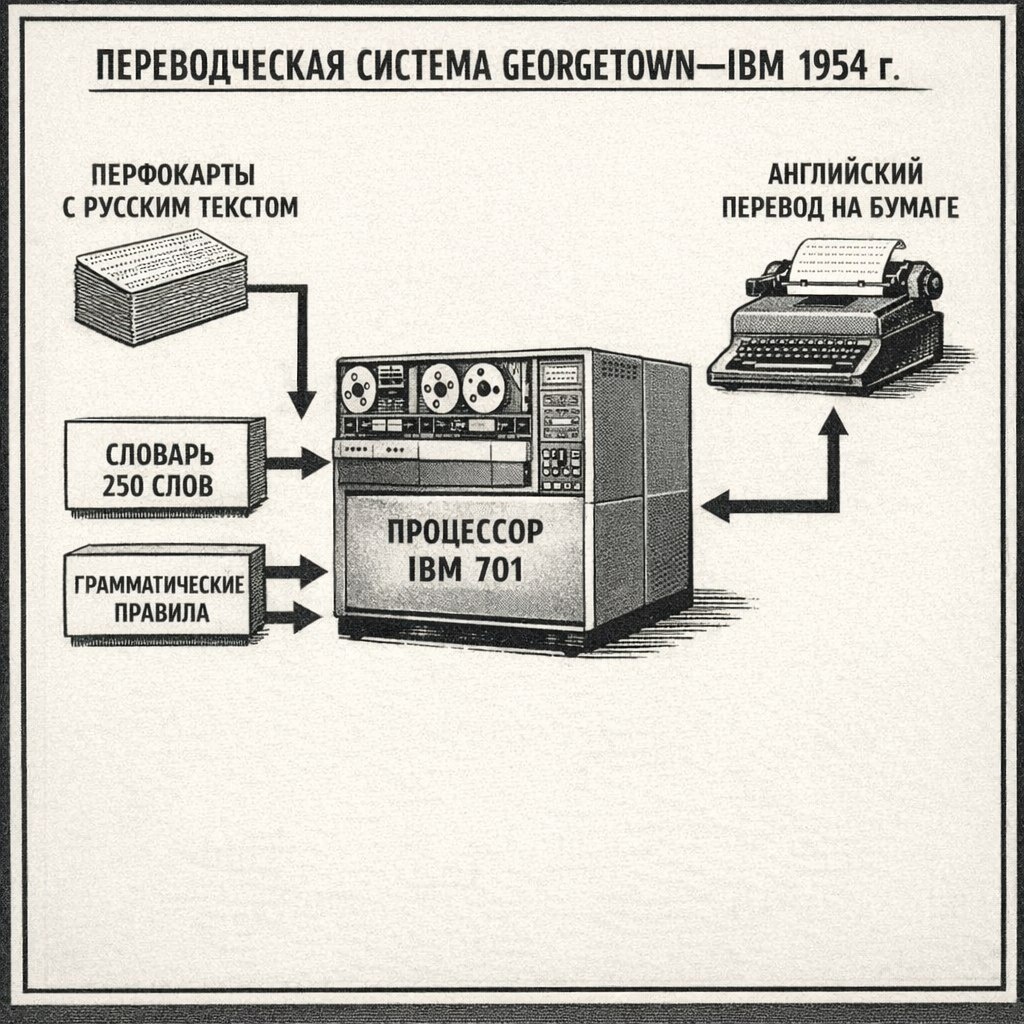
GEORGETOWN-IBM ЭКСПЕРИМЕНТ — первая в мире публичная демонстрация автоматического перевода текста.
ДАТА: 7 января 1954 года
МЕСТО: Джорджтаунский университет, Вашингтон
ОРГАНИЗАТОРЫ:
- Леон Достерт (профессор Georgetown University)
- Инженеры IBM
ЦЕЛЬ: Доказать, что компьютер может переводить русский язык на английский автоматически.
ИСТОРИЧЕСКИЙ КОНТЕКСТ:
1950-е годы — холодная война:
- СССР и США — враги
- Американская разведка перехватывает советские документы, телеграммы, радиопередачи
- Проблема: Всё на русском языке
- Переводчиков мало, перевод медленный
Идея военных:
«А что если компьютер будет переводить автоматически? Тогда мы сможем читать ВСЕ советские документы мгновенно!»
Georgetown University получил грант от Rockefeller Foundation.
IBM предоставил компьютер IBM 701.
Как работал перевод: словарь + правила = примитивный, но работающий
ТЕХНИЧЕСКИЕ ДЕТАЛИ:
КОМПЬЮТЕР:
- IBM 701 — один из первых коммерческих компьютеров
- Размер: целая комната
- Память: 2048 слов (по 36 бит каждое = ~9 КБ!)
- Скорость: ~16,000 операций в секунду
- Ввод/вывод: перфокарты (бумажные карточки с дырками)
СЛОВАРЬ:
- Размер: 250 русских слов + их английские эквиваленты
- Хранение: в памяти компьютера (как таблица соответствий)
Примеры пар:
- качество = quality
- уголь = coal
- определяется = is determined
- калорийность = calory content
ГРАММАТИЧЕСКИЕ ПРАВИЛА:
- Всего 6 правил (примитивные трансформации)
Пример правила:
Правило 1: Если русское слово заканчивается на "-ость", переведи как английское слово с суффиксом "-ity" или "-ness".
Пример:
- калорийность → calory content (по словарю)
- скорость → speed (по правилу: корень "скор" = speed, суффикс "-ость" → без изменений)
ПРОЦЕСС ПЕРЕВОДА:
Шаг 1: Русский текст набивается на перфокарты (вручную, оператором)
Шаг 2: Перфокарты загружаются в IBM 701
Шаг 3: Компьютер читает первое слово
Шаг 4: Ищет слово в словаре
- Если нашёл → берёт английский эквивалент
- Если не нашёл → пропускает (оставляет пробел)
Шаг 5: Применяет грамматические правила (порядок слов, окончания)
Шаг 6: Печатает результат на принтере (медленно, построчно)
ВРЕМЯ ПЕРЕВОДА:
- Одна фраза: ~2-3 минуты (для 1954 года — быстро!)
Демонстрация: 60 фраз переведены, пресса в восторге, но...
7 ЯНВАРЯ 1954, ДЕМОНСТРАЦИЯ:
- Приглашены журналисты, учёные, военные
- Лингвисты Georgetown подготовили 60 русских предложений (простые, научные/технические)
Примеры фраз:
1. "Качество угля определяется калорийностью"
Перевод: "Quality of coal is determined by calory content"
Оценка: ✅ Отлично
2. "Нефть является важным природным ресурсом"
Перевод: "Petroleum is important natural resource"
Оценка: ✅ Хорошо (пропущен артикль "an", но смысл ясен)
3. "Переработка нефти требует высоких температур"
Перевод: "Processing of petroleum requires high temperatures"
Оценка: ✅ Отлично
НО:
Фразы были специально отобраны — простые, без сложной грамматики, без идиом.
Сложные фразы не работали:
Пример неудачи:
Русский: "Он бросил курить"
Буквальный перевод: "He threw smoking"
Правильный: "He quit smoking"
Проблема: Идиома "бросить курить" = переносное значение. Словарь переводит "бросить" как "throw" (буквально). Смысл теряется.
РЕАКЦИЯ ПРЕССЫ (1954):
Заголовки газет:
- "Brain translates Russian into English" (New York Times)
- "Electronic translator works"
- "Machines can now do what humans do"
Оптимизм учёных:
Леон Достерт заявил: «Через 3-5 лет машинный перевод будет решённой проблемой».
РЕАЛЬНОСТЬ:
Прошло 72 года.
Машинный перевод ДО СИХ ПОР не идеален.
Почему технология застряла на 60 лет: сложность языка против примитивных алгоритмов
ПОЧЕМУ GEORGETOWN-IBM НЕ СТАЛ НАЧАЛОМ ЭРЫ МАШИННОГО ПЕРЕВОДА:
ПРОБЛЕМА 1: ЯЗЫК СЛИШКОМ СЛОЖЕН
Многозначность слов:
Пример: Русское слово "коса"
- Коса (инструмент для скашивания травы) = scythe
- Коса (причёска) = braid
- Коса (песчаная отмель) = spit
Компьютер 1954 года: Берёт первое значение из словаря. Часто ошибается.
Идиомы и переносные значения:
Пример: "Сесть в лужу" (идиома = опозориться)
Буквальный перевод: "Sit in puddle"
Смысл потерян.
Компьютер 1954: Переводит буквально. Чушь.
Контекст:
Пример: "The bank is closed" (английский)
- bank = банк (финансовый)?
- bank = берег (реки)?
Нужен контекст предыдущих предложений. Компьютер 1954 не учитывал контекст (памяти не хватало).
ПРОБЛЕМА 2: ГРАММАТИКА РАЗНЫХ ЯЗЫКОВ
Порядок слов:
- Русский: относительно свободный ("Я люблю тебя" = "Тебя люблю я" = "Люблю я тебя")
- Английский: жёсткий ("I love you" ≠ "Love I you")
Компьютер 1954: Использовал примитивные правила (подлежащее-сказуемое-дополнение). Для сложных конструкций не работало.
Падежи:
- Русский: 6 падежей (именительный, родительный, дательный...)
- Английский: падежей почти нет (только притяжательный)
Перевод русского падежа на английский: Нужны предлоги (of, to, with...). Правила 1954 года это не учитывали.
ПРОБЛЕМА 3: ВЫЧИСЛИТЕЛЬНАЯ МОЩНОСТЬ
IBM 701 (1954):
- Память: 9 КБ
- Словарь: только 250 слов (больше не влезало)
Для качественного перевода нужно:
- Словарь: минимум 100,000 слов
- Грамматических правил: тысячи
- Учёт контекста: несколько предыдущих предложений
Это требовало памяти и мощности, которых в 1954 не было.
ЧТО СЛУЧИЛОСЬ ДАЛЬШЕ:
1954-1966: ОПТИМИЗМ
- Правительство США вкладывает миллионы в машинный перевод
- Десятки исследовательских проектов
- Ожидание: Через 5 лет будет работать идеально
1966: ОТЧЁТ ALPAC (УДАР ПО ОТРАСЛИ)
- ALPAC (Automatic Language Processing Advisory Committee) проводит анализ
- Вывод: Машинный перевод не работает. Качество ужасное. Проще нанять людей-переводчиков.
- Рекомендация: Прекратить финансирование.
РЕЗУЛЬТАТ: Финансирование урезано на 90%. Исследования замерли на 20 лет.
1966-1990: "ЗИМА ИИ"
- Машинный перевод = тупиковая ветвь (так считали)
- Исследования продолжаются, но медленно
- Прогресс минимальный
1990-2000: СТАТИСТИЧЕСКИЕ МЕТОДЫ
- Новая идея: не правила, а статистика
- Берём миллионы пар переведённых текстов (русский-английский)
- Компьютер находит паттерны (какие слова часто переводятся как какие)
- Качество выросло до 60-70%
2010-2016: НЕЙРОСЕТИ
- Google, Microsoft переходят на нейронные сети (deep learning)
- Нейросеть обучается на миллиардах предложений
- Учитывает контекст, многозначность
- Качество: 80-90% (хорошо, но не идеально)
2016: GOOGLE NEURAL MACHINE TRANSLATION
- Google Translate переходит на нейросети
- Качество скачкообразно улучшается
2025: СОВРЕМЕННОЕ СОСТОЯНИЕ
- Качество: отличное для простых текстов, среднее для сложных (литература, юридические документы)
- Идиомы, культурные отсылки — до сих пор проблема
Курилка: вопрос читателям
Племянник сказал: «Дед, получается Georgetown-IBM показали, что машинный перевод возможен — но технология не была готова?»
Я кивнул: «Да. Идея правильная. Реализация примитивная. Потребовалось 60 лет, чтобы компьютеры стали достаточно мощными для качественного перевода».
Вопрос в курилку:
Что важнее: доказать концепцию рано или создать рабочий продукт вовремя?
Georgetown-IBM (1954):
- Доказали: машинный перевод возможен
- Качество: 70% для простых фраз (непригодно для реального использования)
- Вдохновили поколение исследователей
- НО: технология застряла на 60 лет (компьютеры слишком слабые)
Google Translate (2016, нейросети):
- Появились вовремя (когда компьютеры стали мощными)
- Качество: 80-90% (пригодно для реального использования)
- Миллиарды пользователей
Кто важнее?
Объективно: Georgetown-IBM проложили путь.
Но мир помнит Google Translate.
Урок:
Ранние демонстрации вдохновляют. Но продукт создаётся, когда технология готова.
Второй вопрос:
Может, машинный перевод убьёт профессию переводчика?
1954: Учёные предсказывали — через 5 лет переводчики не нужны.
2025 (72 года спустя): Переводчики всё ещё нужны.
Почему?
- Машина переводит буквально
- Человек переводит смысл (учитывает культурный контекст, тон, подтекст)
Пример:
Русская поговорка: "Москва слезам не верит"
Google Translate: "Moscow doesn't believe in tears"
Технически правильно, но смысл не передан (это не про слёзы, а про то, что жалобы не помогут).
Человек-переводчик: "Moscow is a tough city" или "Complaining won't help in Moscow"
Передаёт смысл, не слова.
Вывод:
Машинный перевод заменит переводчиков для простых текстов (инструкции, новости).
Не заменит для сложных (литература, дипломатия, юридические документы).
Связь обрывается, но данные остаются.
Ваш Линкин
P.S.
Племянник спросил: «Дед, а оригинальный IBM 701 сохранился?»
Я покачал головой: «Компьютер разобрали в 1960-х. Но один экземпляр IBM 701 выставлен в Музее компьютерной истории (Калифорния). Можно посмотреть, какой гигант переводил 60 фраз».
«Сейчас твой смартфон в 100,000 раз мощнее того IBM 701».
«И переводит в 1000 раз лучше».
«Но первыми были они. 1954 год. Холодная война. Перфокарты. Комната электроники».
«Они доказали: компьютер может понимать язык».
«Пусть криво. Пусть примитивно. Но — может».
«Это был прорыв».
Железо помнит. Перфокарты тоже. Первые шаги самые трудные.