
CSV - это как коробка без инструкций. Снаружи это просто текстовый файл, в котором внутри куча сюрпризов: даты строками, числа текстом, пропуски в виде “-”, а русская кодировка превращает “Сотрудник” в какие-то кракозябры.
Обычно, при read_csv используют набор основных параметров: задать путь, разделитель быть может и кодировку. Но функционал здесь намного больше, давайте поговорим о том, какие еще могут быть аргументы у этой функции.
Данные фишки использую в своей работе регулярно, так как приходится работать с большим числом CSV файлов.
Если вам интересно глубже понимать аналитику и работать с данными, то приглашаю вас в свой Telegram-канал, где регулярно выходят короткие заметки и практические примеры.
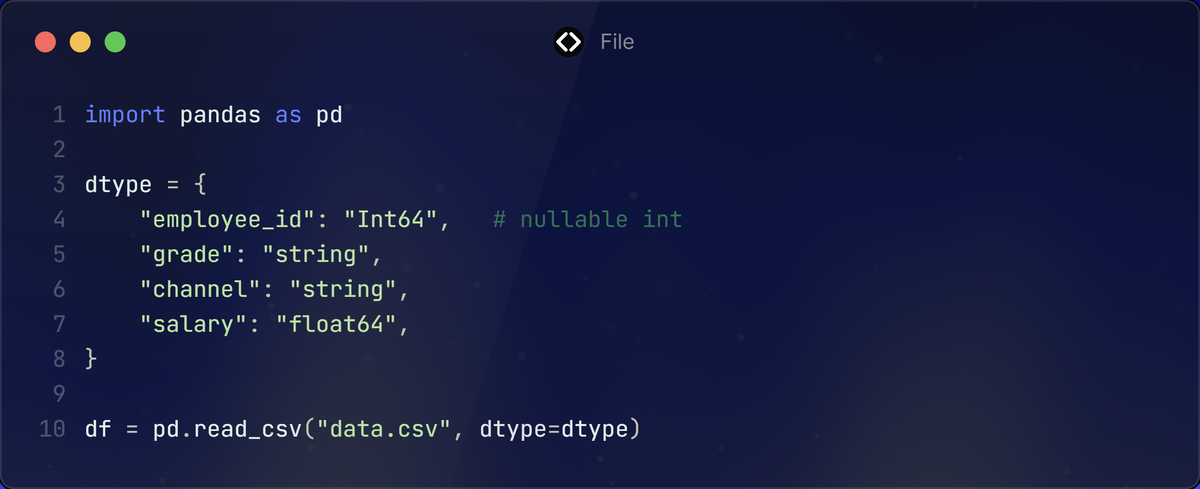
Сразу фиксируйте типы, иначе потом будете лечить object
Если оставить pandas угадывать, то колонка с числами легко становится строкой из-за пары мусорных значений.
Читайте только нужные колонки
Иногда файл большой, а вам нужно 6 колонок из 60.
Это и быстрее, и дешевле по памяти, и меньше шансов случайно притащить мусор.
Пропуски задавайте явно
Если пропуски не привести к NaN, вы в любом случае потом будете изменять этот текст и убирать лишние значения.
Даты парсите на входе
Decimal и thousands
Зарплата может выглядеть вот так 12 345,67. И зайдет в DataFrame как текст, поэтому лучше всего это учесть сразу и изменить эти значения в числа.
Большие файлы
Если файл тяжелый, не надо пытаться загрузить весь. Воспользуйтесь лучше chunk.
Вывод
read_csv - это не про просто загрузить файл, это про загрузить данные правильно, чтобы дальше не возвращаться к этому (всё равно же вернетесь).
Когда вы фиксируете типы, явно задаете пропуски, парсите даты на входе, учитываете локаль (decimal/thousands), читаете только нужные колонки и умеете работать с chunks - вы получаете как раз ту скорость, которая потом позволит вам не прогонять пайплайн сотню раз и не думать о чистках данных в дальнейшем.
И это, по сути, главный эффект: эти фишки экономят время аналитика и защищают качество решений, которые бизнес будет принимать по вашим данным.
Если что-то забыл упомянуть или у вас есть свои наработки с этой функцией, поделитесь этим в комментариях, дополню материал.