⚡️ Хочешь обучить свой TTS с нуля и добавлять туда фичи “как тебе надо”, а не как у всех?
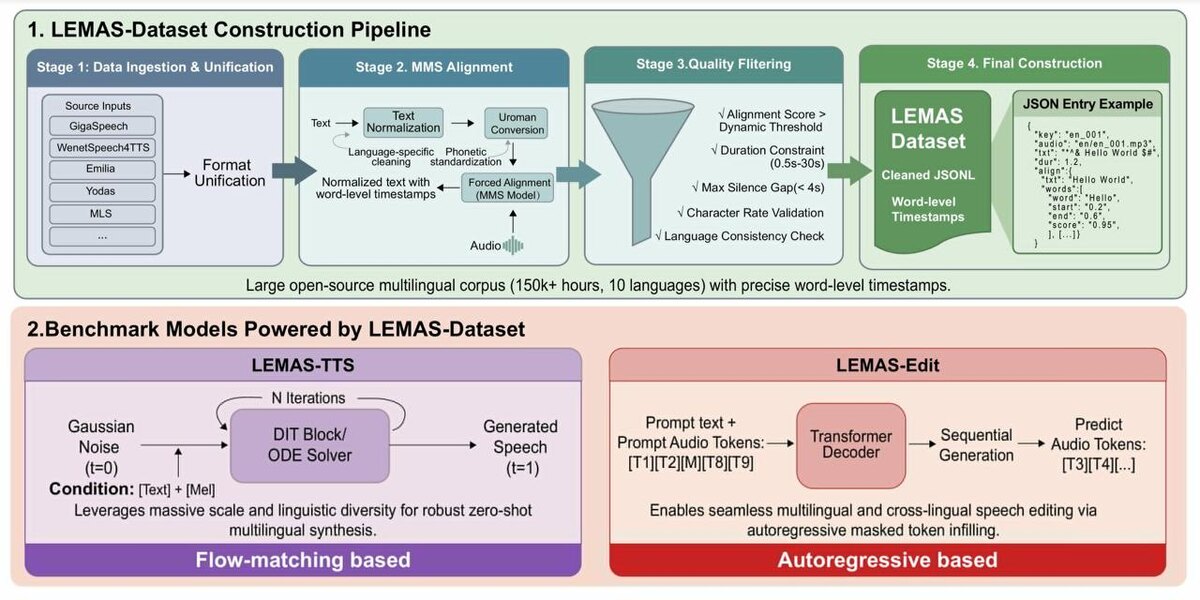
Команда LEMAS (IDEA) открыла датасет, на котором они обучали LEMAS и это, похоже, крупнейший open-source мультиязычный speech-датасет вообще.
Что внутри:
- 150K+ часов аудио
- 10 языков
- word-level timestamps (разметка до уровня слов)
- качество и масштаб уровня “обычно такое держат под замком”
По сути - они выложили то, что большинство компаний никогда бы не отдали публично.
И да, из этого “сокровища” уже родились 2 мощные модели:
LEMAS-TTS
- Zero-shot мультиязычный синтез речи (озвучка без дообучения на конкретного спикера)
LEMAS-Edit
- редактирование речи как текста: меняешь слова — меняется аудио
Если ты работаешь со Speech AI, TTS, ASR, voice agents — это must-have релиз.
Project: https://lemas-project.github.io/LEMAS-Project/
Dataset & model released: https://huggingface.co/LEMAS-Project