Zhipu AI представила легковесную модель GLM-4.7-Flash на базе MoE (30B/3B параметров) с бесплатным API. Новинка использует архитектуру MLA для повышения эффективности, демонстрирует 59.2 на SWE-bench и достигает 43 токенов/сек на Apple M5.
Компания Zhipu AI официально представила открытый исходный код и выпустила GLM-4.7-Flash — легковесную большую языковую модель, позиционируемую как преемник GLM-4.5-Flash. Модель теперь доступна с бесплатным доступом через API и разработана для локального программирования и агентских приложений.
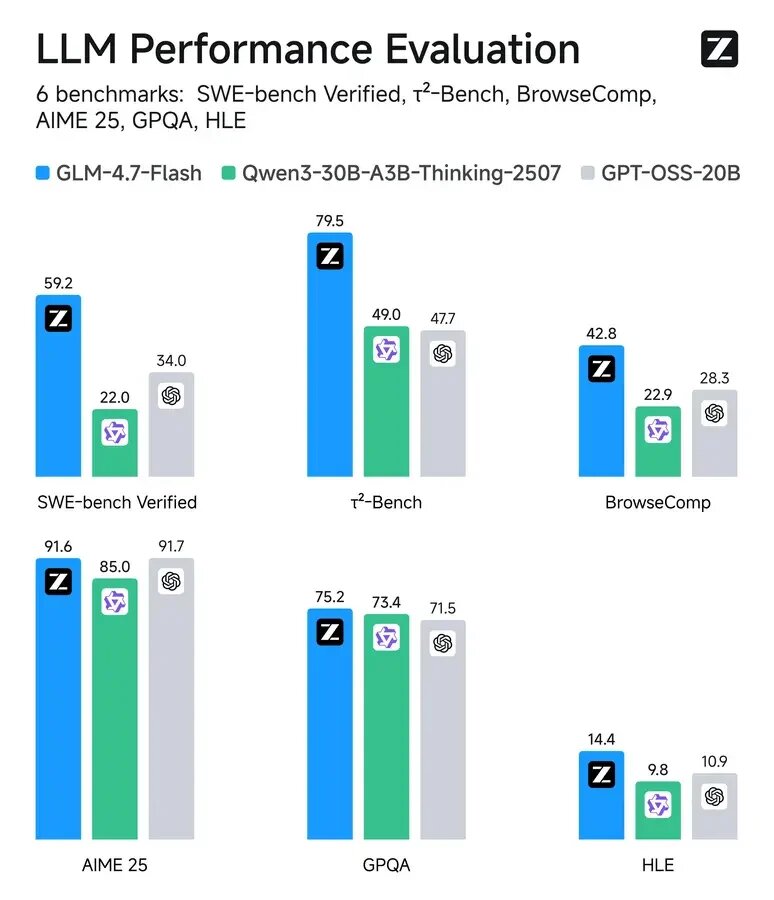
GLM-4.7-Flash использует архитектуру Mixture-of-Experts (MoE) с общим числом параметров в 30 миллиардов, при этом во время инференса активируется лишь около 3 миллиардов параметров, что значительно повышает эффективность. На бенчмарке SWE-bench Verified, предназначенном для реального исправления кода, модель продемонстрировала результат 59.2, подтверждая свои сильные способности к кодированию и логическому мышлению.
Важным техническим достижением стало первое применение Zhipu архитектуры MLA (Multi-head Latent Attention) — подхода, ранее подтвердившего свою эффективность в DeepSeek-v2, направленного на улучшение эффективности работы с длинным контекстом и производительности инференса. Модель оптимизирована для широкого спектра задач, включая креативное письмо, перевод и рассуждения на основе длинных контекстов.
Релиз быстро получил поддержку экосистемы: Hugging Face и vLLM обеспечили немедленную совместимость. Также доступна официальная поддержка нейропроцессоров Huawei Ascend NPU. В ходе тестов локального развертывания разработчики зафиксировали скорость инференса в 43 токена в секунду на ноутбуке Apple с чипом M5 и 32 ГБ унифицированной памяти. В коммерческом плане базовый уровень API полностью бесплатен (один одновременный запрос), в то время как высокоскоростная версия GLM-4.7-FlashX предлагается по конкурентоспособной цене.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Pandaily