⚡️ GLM-4.7-Flash - “быстрый” MoE-монстр, который вывозит coding и агентов локально
Z.ai (семейство ChatGLM) выложили GLM-4.7-Flash на Hugging Face - и это один из тех релизов, которые прям приятно тащить к себе на сервер.
Что это за модель
GLM-4.7-Flash - это MoE 30B-A3B:
то есть у неё “много параметров”, но активных на шаге всего ~3B, поэтому она:
- быстрее в инференсе
- легче в деплое
- дешевле в эксплуатации, чем плотные 30B
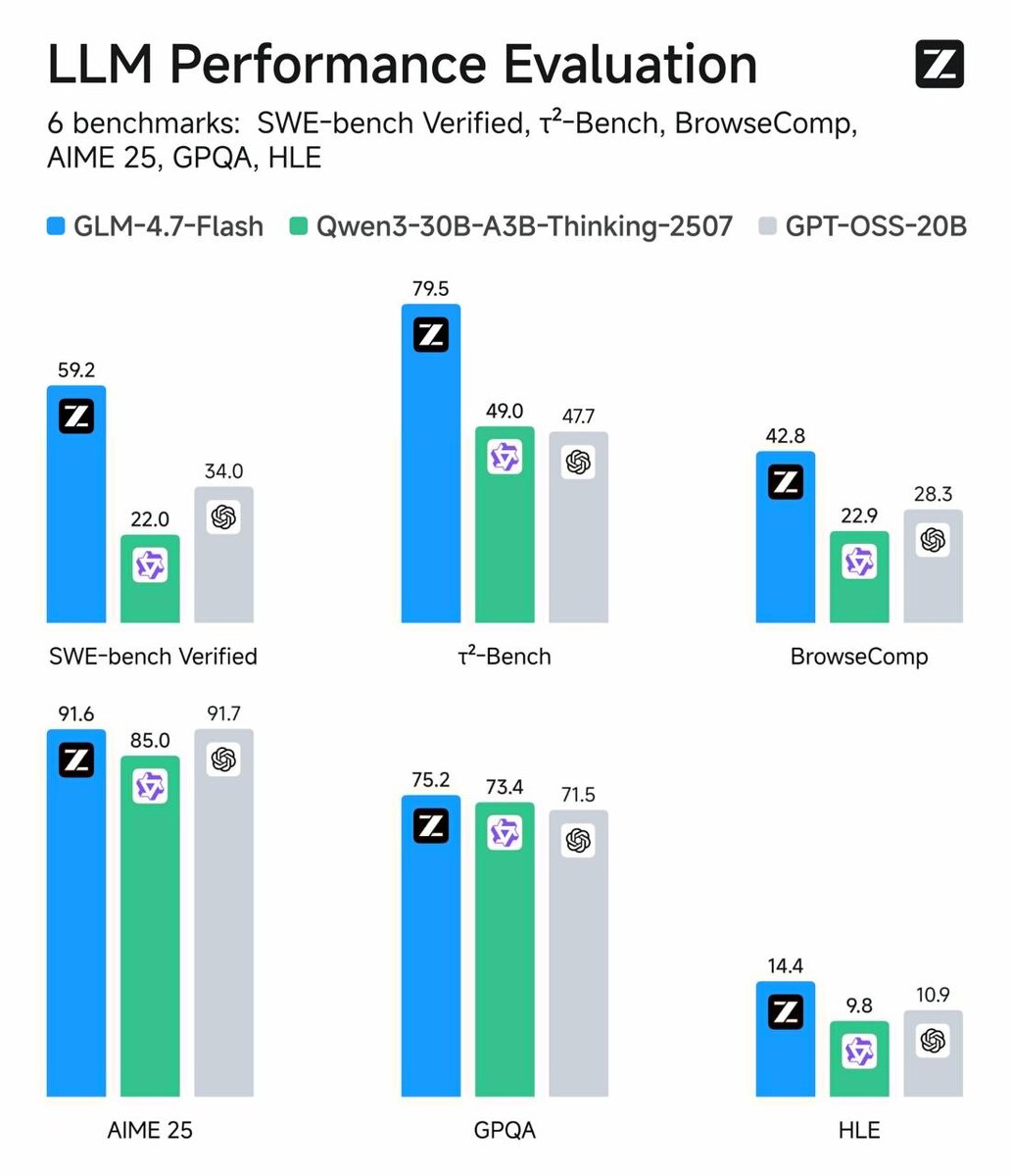
По бенчмаркам выглядит очень бодро:
- AIME 2025: 91.6
- GPQA: 75.2
- SWE-bench Verified: 59.2 (очень сильный показатель для coding-агентов)
- BrowseComp: 42.8
Почему это важно
Это “рабочая лошадь” под:
- локальные агентные пайплайны
- автокодинг / рефакторинг
- web-browsing задачи
- длинный контекст и быстрый inference
Плюс - уже заявлена поддержка vLLM и SGLang (на main ветках).
Ссылка: https://huggingface.co/zai-org/GLM-4.7-Flash