Когда вы читаете эту статью, ваш процессор выполняет один и тот же цикл миллиарды раз в секунду. Не какие-то сложные алгоритмы, не нейросети — просто бесконечное повторение трёх операций: взял команду, понял, что с ней делать, выполнил. И всё. Это основа всех вычислений, которые происходят в вашем компьютере прямо сейчас. 💾

Первый лайфхак для новичков: Если вы хотите понять, почему ваш компьютер медленнее, чем мог бы быть, нужно понимать этот цикл. Потому что любая оптимизация сводится к одному — сделать этот цикл быстрее. Это фундамент всех остальных оптимизаций.
Из чего состоит один такт процессора? 🔄
Вот перед вами процессор. Внутри него — счётчик команд, кэш-память, декодер инструкций, исполнительные устройства. Простая система, но потрясающе эффективная. Один такт процессора — это временной интервал, определяемый кварцевым генератором (обычно он указан как тактовая частота: 3,2 ГГц, 4,5 ГГц и так далее). За один такт процессор проходит через три этапа.
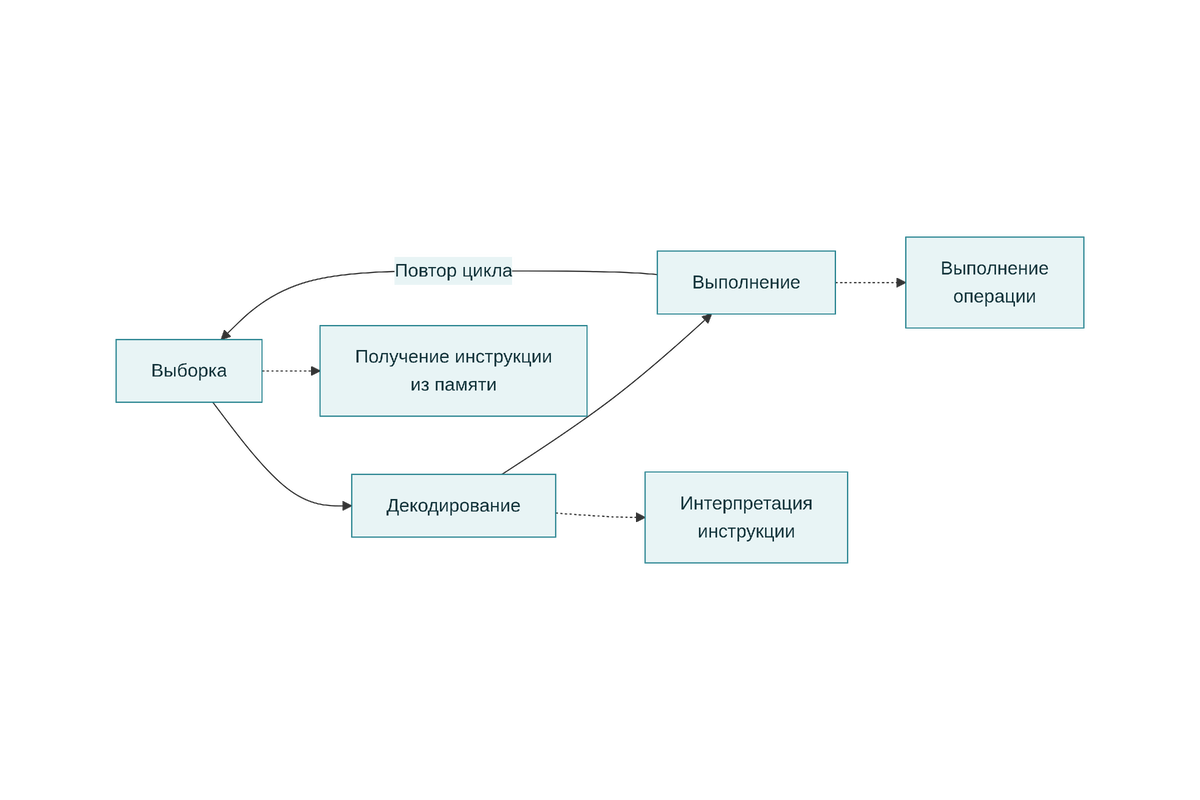
Этап 1: Выборка команды (Fetch) 📥
Всё начинается с выборки. Процессор смотрит на счётчик команд — специальный регистр, который хранит адрес текущей команды в памяти. На основе этого адреса блок выборки команд (Instruction Fetch Unit) обращается к кэш-памяти первого уровня (L1i-cache), чтобы извлечь следующую инструкцию.
Если команда уже лежит в кэше — отлично, задержка минимальна (несколько тактов). Если нет — нужно идти в L2, потом L3, а в худшем случае — в основную оперативную память. И вот тут задержки взлетают до сотен тактов. Это первая узкая горлышка производительности.
Совет: Если вы пишете код, старайтесь держать часто используемые данные компактно. Это помогает кэшу работать эффективнее и ускоряет именно этап выборки.
Этап 2: Декодирование команды (Decode) 🔍
Команда попала в буфер, и теперь декодер процессора должен её понять. Машинный код — это просто набор битов, и декодер преобразует их в микроинструкции, которые процессор может выполнить.
Например, инструкция x86 «ADD RAX, RBX» кодируется как определённая последовательность битов. Декодер смотрит на эти биты, определяет операнды (какие регистры задействованы), тип операции, размер данных и передаёт всё это дальше в конвейер выполнения.
На этом этапе могут появиться ветвления (условные переходы). Процессор должен решить: идти ли на следующую команду или прыгнуть на другой адрес? Вот почему неправильное предсказание ветвления убивает производительность на корню.
Секрет оптимизации: В современных процессорах используется спекулятивное исполнение — процессор заранее предсказывает, куда прыгнет условный переход, и начинает загружать команды оттуда. Если предсказание неверно — весь конвейер нужно очищать. Плохой код с частыми непредсказуемыми ветвлениями может замедлиться в 2—3 раза.
========================
✅ Подпишитесь на канал - (это бесплатно и очень помогает алгоритму)
❤️ Поставьте лайк - (это один клик, а нам очень важно)
🔄 Репостните друзьям - (которые играют в танки и жалуются на FPS)
💰 Задонатьте (Даже 50 руб. - это топливо для новых статей, скриптов и пошаговых инструкция для Вас. Большое Спасибо понимающим! 🙏
💰ПОДДЕРЖАТЬ КАНАЛ МОЖНО ТУТ ( ОТ 50 РУБЛЕЙ )💰
Или сделать любой перевод по ССЫЛКЕ или QR-коду через СБП. Быстро, безопасно и без комиссии. ( Александр Г. ) "Т.Е.Х.Н.О Windows & Linux".
=========================
Этап 3: Выполнение команды (Execute) ⚙️
Вот уже декодированная микроинструкция попадает в исполнительное устройство. Это может быть арифметико-логическое устройство (АЛУ) для простых операций, блок работы с памятью (Load/Store Unit) для доступа к оперативной памяти, или специализированное устройство для векторных операций (SSE, AVX, NEON).
На этом этапе происходит реальная работа: складываются числа, сравниваются значения, пишутся данные в память. Результат сохраняется в регистры или передаётся дальше в конвейер.
Важно: Выполнение не всегда занимает один такт. Сложные операции (деление, квадратный корень) могут требовать десятки тактов. Это еще одна задержка, которая замораживает весь конвейер.
Почему это повторяется миллиарды раз в секунду? 📊
Современный процессор Intel Core i9-14900K работает на частоте 3,2 ГГц в базовом режиме и до 6,0 ГГц в турбо-режиме. Это означает, что счётчик команд увеличивается 3 200 000 000 раз в секунду (или даже 6 000 000 000 раз в турбо). Процессор Intel Core Ultra 9 285K работает на 3,7 ГГц базовой частоты и 5,7 ГГц в турбо.
За одну секунду на процессоре i9-14900K в турбо-режиме выполняется 6 миллиардов полных циклов Fetch-Decode-Execute. Это колоссальная цифра, но она не означает, что происходит 6 миллиардов полезных вычислений — часть времени уходит на пустой ход, ожидание памяти и очищение конвейера при неправильных предсказаниях.
Однако в среднем даже обычный процессор за секунду выполняет сотни миллиардов операций. А вот какие из них реальные, а какие — спекуляция, зависит от качества кода и архитектуры программы.
Конвейеризация: как процессор наращивает мощь 🔧
В реальности современные процессоры работают не так просто, как описано выше. Вместо того чтобы ждать, пока команда пройдёт все три этапа, процессор использует конвейер (pipeline). На каждом такте:
- Одна команда находится в стадии выборки
- Другая в стадии декодирования
- Третья выполняется
- А ещё несколько ждут в буфере
Это позволяет увеличить пропускную способность. Но если происходит задержка (переполнение кэша, условный переход, сложная операция), весь конвейер может остановиться. Это называется пузырь в конвейере.
Лайфхак: Код, который вызывает частые остановки конвейера (зависимости между командами, неправильно предсказуемые переходы), будет работать намного медленнее, чем количество инструкций может предположить.
Главные настройки и оптимизация на Windows 25H2 ⚙️
Настройка 1: Управление питанием и частотой процессора
Windows 25H2 позволяет контролировать режимы работы процессора. По умолчанию система пытается сбалансировать производительность и потребление энергии, но вы можете её переконфигурировать.
Шаг 1. Откройте командную строку PowerShell с правами администратора:
# Проверить текущий план электропитания
Get-WmiObject -Class Win32_PowerPlan -Namespace root\cimv2\power | Select-Object ElementName, @{N='Активен';E={$_.IsActive}}
# Установить план "Максимальная производительность"
powercfg /SETACTIVE SCHEME_MIN
Шаг 2. Для более тонкой настройки используйте реестр:
# Установить минимальное значение процессора на 100% (без снижения частоты)
powercfg /CHANGE MONITOR-TIMEOUT-AC 0
powercfg /CHANGE DISK-TIMEOUT-AC 0
powercfg /CHANGE STANDBY-TIMEOUT-AC 0
# Отключить адаптивное снижение напряжения (если нужна максимальная производительность)
reg add "HKLM\SYSTEM\CurrentControlSet\Control\Power" /v "HibernateFileSizePercent" /t REG_DWORD /d 0 /f
Совет: Устанавливайте "Максимальная производительность" только если нужна стабильная производительность — для ноутбуков это убьёт батарею за час.
Канал «Каморка Программиста» — это простые разборы программирования, языков, фреймворков и веб-дизайна. Всё для новичков и профессионалов.
Присоединяйся прямо сейчас.
Настройка 2: Отключение динамического изменения частоты (для продвинутых)
На некоторых системах динамическое изменение частоты (DVFS — Dynamic Voltage and Frequency Scaling) может вносить задержки. Если вам нужна стабильная производительность, можно её отключить:
# Проверить состояние динамического масштабирования частоты
Get-WmiObject -Class Win32_PerfFormattedData_Counters_ProcessorInformation | Select-Object Name, @{N='Базовая_частота';E={$_.PercentofMaximumFrequency}}
# Через реестр установить фиксированную частоту (требует перезагрузки)
powercfg /query SCHEME_CURRENT sub_processor
# Найти GUID стратегии процессора и применить её
$guid = (powercfg /query SCHEME_CURRENT | Select-String "Максимальная" | Select-Object -First 1).ToString().Split(":").Trim()
Настройка 3: Приоритет процесса в системе
Если вы хотите, чтобы определённое приложение имело приоритет при выполнении цикла процессора:
# Запустить приложение с высоким приоритетом
Start-Process -FilePath "C:\Program Files\Application\app.exe" -PriorityLevel High
# Изменить приоритет уже запущенного процесса
Get-Process notepad | ForEach-Object { $_.PriorityClass = [System.Diagnostics.ProcessPriorityClass]::High }
# Проверить приоритет процесса
Get-Process | Select-Object Name, @{N='Приоритет';E={$_.PriorityClass}} | Where-Object Name -Like "*chrome*"
Важно: Установка приоритета High или Realtime может заморозить систему, если приложение будет занято циклом. Используйте осторожно.
Настройка 4: Мониторинг выполнения цикла процессора
Чтобы видеть, как работает ваш процессор, используйте следующий скрипт:
# Мониторинг частоты процессора в реальном времени
# Требует Windows 25H2 и встроенного WMIC (или WMI в более новых версиях)
while ($true) {
$cpu = Get-WmiObject -Class Win32_Processor | Select-Object Name, CurrentClockSpeed, MaxClockSpeed
$load = Get-WmiObject -Class Win32_PerfFormattedData_PerfOS_Processor | Where-Object Name -eq "_Total" | Select-Object PercentProcessorTime
Clear-Host
Write-Host "=== Мониторинг процессора ===" -ForegroundColor Cyan
Write-Host "Название: $($cpu.Name)" -ForegroundColor White
Write-Host "Текущая частота: $($cpu.CurrentClockSpeed) МГц" -ForegroundColor Yellow
Write-Host "Максимальная частота: $($cpu.MaxClockSpeed) МГц" -ForegroundColor Green
Write-Host "Нагрузка: $($load.PercentProcessorTime)%" -ForegroundColor Magenta
Write-Host ""
Write-Host "Обновление каждые 2 секунды. Для выхода нажмите Ctrl+C" -ForegroundColor Gray
Start-Sleep -Seconds 2
}
Запуск: Сохраните как cpu_monitor.ps1 и запустите:
Set-ExecutionPolicy -ExecutionPolicy Bypass -Scope Process -Force
& "C:\path\to\cpu_monitor.ps1"
Итоги: к чему это привело 📈
После применения этих настроек вы получите:
- Более стабильную производительность — процессор не будет колебаться в частоте при простых задачах
- Меньше задержек — стабильный Fetch-Decode-Execute цикл без прерываний означает предсказуемое время отклика
- Контроль над системой — вы видите, как работает ваш процессор, и можете оптимизировать под свои нужды
- Понимание — теперь вы знаете, почему одна программа быстрая, а другая медленная
Для серверов и рабочих станций эти знания критичны. Для домашнего пользователя — это шанс выжать максимум из железа.
Как откатиться в случае ошибки 🔙
Если что-то пошло не так, процесс легко отменить:
# Вернуть план электропитания по умолчанию (Сбалансированный)
powercfg /SETACTIVE SCHEME_BALANCED
# Сбросить все настройки питания
powercfg /RESTOREDEFAULTSCHEMES
# Проверить результат
Get-WmiObject -Class Win32_PowerPlan -Namespace root\cimv2\power | Select-Object ElementName, @{N='Активен';E={$_.IsActive}}
# Если система нестабильна, перезагрузитесь в безопасный режим
# (F8 при загрузке или: msconfig -> вкладка Загрузка -> Безопасный режим)
Совет: Всегда делайте точку восстановления перед изменением реестра:
# Создать точку восстановления системы
Checkpoint-Computer -Description "До оптимизации CPU" -RestorePointType "MODIFY_SETTINGS"
Вопрос—Ответ 🤔
Вопрос: Почему процессор не может выполнять бесконечно быстро?
Ответ: Потому что физика не позволяет. Электрический ток распространяется с конечной скоростью. Кроме того, с повышением частоты растёт потребление энергии и тепло. Современные процессоры на 5—6 ГГц уже нагреваются до 100 градусов при нагрузке. Дальше можно только охлаждением.
Вопрос: Почему задержки памяти убивают производительность так эффективно?
Ответ: Потому что пока процессор ждёт данных из памяти, весь его конвейер встал. Цикл Fetch-Decode-Execute остановлен. Если это происходит часто, процессор простаивает до 80 процентов времени. Это как если бы вы писали письмо, но каждый раз забывали буквы и ждали их из другой комнаты.
Вопрос: Что такое спекулятивное исполнение и насколько оно опасно?
Ответ: Это когда процессор угадывает результат условного перехода и загружает команды заранее. Если угадал правильно — прибыль в производительности. Если нет — конвейер нужно очищать (штраф 10—20 тактов). Что касается безопасности — уязвимости Spectre и Meltdown показали, что спекулятивное исполнение может привести к утечкам данных. Microsoft и Intel закрыли их, но это требует постоянного обновления.
Вопрос: Может ли пользователь как-то влиять на процесс Fetch-Decode-Execute?
Ответ: Прямо — нет. Но косвенно — постоянно. Написав хороший код без зависимостей между инструкциями и с предсказуемыми переходами, вы помогаете процессору работать эффективнее. Правильно организованные данные в памяти улучшают кэширование. Выбор алгоритма может означать разницу между миллиардами потраченных тактов и минимальными издержками.
Призыв к действию и благодарность 💪
Если эта статья помогла вам разобраться в том, как на самом деле работает ваш компьютер, то поделитесь ею с друзьями. Нажмите «Лайк» и подпишитесь на канал T.E.X.H.O Windows & Linux, чтобы не пропустить новые статьи о железе, оптимизации и хитростях системного администрирования.
Если вы хотите, чтобы мы рассмотрели конкретную оптимизацию или провели более глубокий анализ микро-архитектуры вашего процессора, поддержите канал донатом. Каждый рубль помогает нам создавать более качественный контент.
Репостните эту статью тем, кто работает с железом. Давайте сделаем компьютеры быстрее вместе! 🚀
#ПроцессорОсновы #FetchDecodeExecute #МикроархитектураПроцессора #ОптимизацияПроцессора #Windows25H2 #PowerShellОптимизация #СистемныеПроцессы #КэшПамять #АлгоритмыПроцессора #ЦиклПроцессора #ПроизводительностьПК #ОптимизацияПК #ЛинухиУроки #ТехнологияПроцессора #ПроцессорыIntel #ПроцессорыAMD #СборкаПК #ТюнингОперативнойСистемы #КомпьютернаяАрхитектура #SysAdmin #ИТТехнология #ОптимизацияСистемы #ТехническийконтентT #T_E_X_H_O #ШколаПроцессора #КонвейеризацияПроцессора #ПредсказаниеПереходов #ВысокиеПроизводительности #ПисьмоНаПроцессор