
Предыдущие статьи вступительной части:
Введение.
В данном посте я расскажу о том, что успел реализовать к этому моменту: как работают отдельные части программы и с какими сложностями пришлось столкнуться.
Разработку я начал 30 октября 2025 года. За два месяца я не только продвинулся в коде, но и гораздо чётче понял финальный образ системы - что именно хочу получить в итоге и как это должно работать.
Сначала я планировал реализовать все 8 этапов освоения слова с 1-2 упражнениями на каждый. Однако, завершив разработку третьего этапа - "Глубокое запоминание", - я задумался о дальнейших шагах.
Стало понятно, что нет смысла двигаться к следующим этапам, пока не будут готовы фундаментальные части системы: словарь, грамматика и система тегов. Как именно я пришёл к этому выводу, расскажу в следующем посте.
А теперь подробнее о том, что уже реализовано и как это устроено. На данный момент система состоит из нескольких связанных модулей.
1. Выбор языка
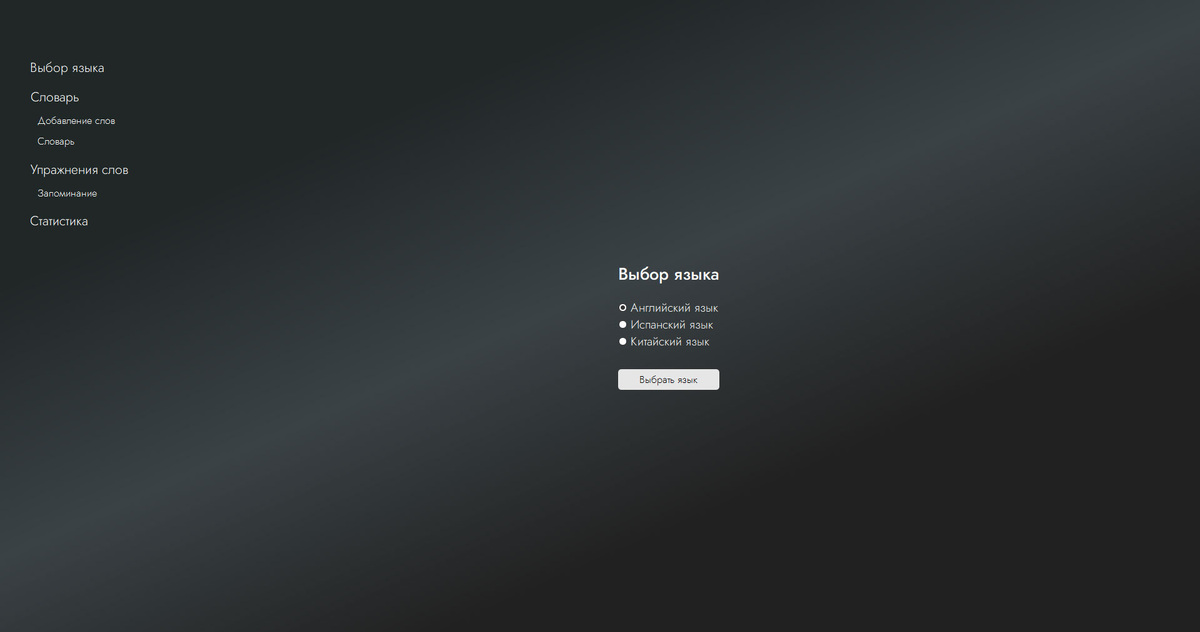
Назначение.
Это "точка входа" пользователя в систему.
Выбранный язык становится системной константой, которая определяет работу всех остальных модулей: словарь, упражнения, статистика и интервальные повторения будут завязаны именно на него.
Как это работает?
При первом запуске пользователь видит окно с выбором. На данный момент доступно три варианта:
- Английский
- Испанский
- Китайский
Достаточно выбрать нужный пункт и нажать "Выбрать язык" - система запомнит этот выбор и будет использовать его во всех последующих модулях.
При желании язык обучения можно изменить в любой момент в соответствующем разделе.
Возникшие сложности.
Этот модуль стал самым простым в реализации с точки зрения логики.
Единственный момент, над которым пришлось немного подумать - как хранить в базе данных всего одну запись (выбранный язык), чтобы её можно было легко читать и при необходимости перезаписывать. Решение оказалось простым, и сложностей не возникло.
2. Добавление слов (1-й этап моей системы).
Назначение.
Это основной экран системы - сохранение новых слов для их последующего изучения. Добавленное слово получает статус "сырое", что означает: оно ждёт обработки.
Как это работает?
Я открываю форму для добавления слов, ввожу новое слово и, при желании, контекст. После нажатия кнопки «Добавить» слово сохраняется в базу данных.
Ключевая особенность - форма остаётся открытой, что позволяет вводить слова потоком, не отвлекаясь от основного занятия (например, чтения или просмотра фильма).
Добавлять можно любое количество слов за один раз.
Возникшие сложности.
Основная сложность была связана не с логикой работы данной части программы, а выбором библиотеки для графического интерфейса.
Изначально я использовал Tkinter, но быстро столкнулся с ограничениями, например, отсутствием нормальной поддержки копирования и вставки текста в поля ввода без написания дополнительного кода. Это заставило меня перейти на PySide6.
Сам переход занял 3-4 дня, в основном из-за кастомизации стилей интерфейса - базовый макет можно было сделать за день.
После смены фреймворка процесс разработки этого модуля пошёл гладко, и других существенных трудностей не возникло.
3. Обработка слов (2-й этап моей системы).
Назначение.
Этот этап превращает «сырое» слово из простой записи в полноценный объект для изучения. Здесь нужно заполнить все обязательные данные о слове - без них система просто не сможет использовать его в упражнениях.
Как это работает?
Я выбираю слово из списка "сырых" слов, кликаю по нему правой кнопкой мыши и выбираю "Начать изучать". Открывается форма, в которую вносятся: транскрипция, часть речи, перевод, определение на английском, теги.
После заполнения и нажатия кнопки "Начать изучать" слово меняет статус на "в изучении" и становится доступным для упражнений.
Возникшие сложности.
Основная сложность была связана не с логикой, а с расширением модели данных в базе - я только начинал с ней работать. Потребовалось разобраться, как правильно добавлять новые поля и обрабатывать изменения структуры. В остальном реализация прошла без особых проблем.
4. Глубокое запоминание (3-й этап моей системы).
Назначение.
Это первое и ключевое упражнение в системе, которое отвечает за начальный этап владения словом - его устойчивое запоминание. На данный момент оно единственное реализованное, но формирует основу для будущих тренировок.
Как это работает?
Я выбираю это упражнение в интерфейсе. Открывается страница с настройками:
- можно указать количество слов для текущей сессии.
- можно установить флажок, чтобы добавить слова, которые уже были изучены и для которых система рассчитала дату следующего повторения.
После нажатия кнопки "Начать упражнение" система формирует подборку слов и запускает процесс.
Для каждого слова нужно последовательно пройти 13 шагов. Между шагами можно свободно перемещаться вперёд и назад, пока слово не будет усвоено. Такой же цикл повторяется для всех слов в подборке.
Упражнение можно остановить в любой момент, но в текущей версии прогресс при этом не сохраняется (я планирую изменить это, чтобы система фиксировала уже пройденные этапы).
После прохождения всех слов появляется кнопка "Завершить упражнение". Её нажатие завершает сессию и выводит итоговую статистику: общее время занятия, количество изученных слов и среднее время на слово. Все эти данные сохраняются для последующего анализа и учёта в системе интервальных повторений.
Возникшие сложности.
Основная трудность заключалась в проектировании: было неочевидно, какие данные нужно хранить и как лучше организовать логику работы упражнения.
В итоге я выбрал прагматичный подход - реализовал рабочую версию, отложив оптимизацию архитектуры на будущее. Это позволило быстро получить результат и начать тестирование.
5. Система обучения.
Назначение.
Это центральный модуль, который будет координировать выполнение всех упражнений.
В перспективе я планирую добавить 10–15 различных упражнений. Однако на старте я сознательно отказался от проектирования сложной универсальной архитектуры "на вырост". Вместо этого я создал минимальную рабочую версию, которая поддерживает пока что единственный тип упражнений.
Такой подход позволил мне быстро получить работающий прототип, начать им пользоваться и сохранить мотивацию для дальнейшей разработки.
Как это работает?
Пользователь выбирает нужное упражнение (в текущей версии - одно) и нажимает кнопку "Начать упражнение". Система обучения создаёт новую сессию, обращается к модулю интервальных повторений и формирует подборку слов в соответствии с типом упражнения и индивидуальным графиком повторений для каждого слова.
На данный момент каждое слово в подборке обрабатывается как отдельное упражнение.
Упражнение можно запустить, приостановить и завершить.
Возникшие сложности.
Основная сложность заключалась в принятии архитектурного решения. Я осознанно выбрал путь минимальной реализации для первого упражнения, отложив создание сложной абстрактной системы на будущее.
Это позволило избежать перепроектирования и сосредоточиться на работоспособности ядра, что и стало ключом к прогрессу.
6. Система упражнений.
Назначение.
Центральный модуль, отвечающий за создание обучающих упражнений.
Его задача - получать отобранные слова и тип упражнения, затем генерировать персонализированные задания для каждого слова, формируя полноценную учебную сессию.
Как это работает?
Процесс запускается, когда система обучения передаёт в этот модуль два ключевых параметра: список слов (полученный от системы интервальных повторений) и тип упражнения.
Система упражнений на основе этих данных создаёт индивидуальные задания для каждого слова и возвращает готовый пакет упражнений обратно в ядро обучения для дальнейшего выполнения пользователем.
Возникшие сложности.
На текущем этапе сложности были минимальны, так как в системе реализован только один тип упражнения.
Это позволило сосредоточиться на отработке базового механизма взаимодействия модулей без необходимости проектирования сложной абстрактной архитектуры "на вырост".
7. Система интервальных повторений.
Назначение.
Этот модуль отвечает за планирование повторений слов согласно принципу интервального запоминания.
На данный момент реализована базовая версия с жёстко заданными интервалами, которая обеспечивает показ слов в нужные дни для их эффективного закрепления в памяти.
Как это работает?
Система рассчитывает дату следующего показа слова на основе двух параметров: текущей даты и количества уже выполненных повторений этого слова в конкретном упражнении.
К дате последнего взаимодействия прибавляется определённое количество дней в зависимости от номера повторения.
Например:
- Первое повторение - слово будет показано в тот же день.
- Второе повторение - через 1 день.
- Третье повторение - через 2 дня.
- и так далее по заданному шаблону.
Общее количество необходимых повторений для каждого типа упражнения жёстко задано.
Как только слово проходит через все запланированные этапы, оно считается освоенным и больше не включается в подборку для этого упражнения.
Возникшие сложности.
Основная трудность возникла с логикой подсчёта повторов.
Изначально система некорректно учитывала первое взаимодействие с ещё не запомненным словом, из-за чего общее количество показов не совпадало с ожидаемым. Проблема была в неверном условии проверки статуса слова, которую удалось быстро исправить после детального разбора логики работы модуля.
Вывод
На первый взгляд может показаться, что за два месяца реализовано не так много. Однако, если разложить систему на модули, становится ясно: готов полноценный рабочий каркас - от добавления слов и их обработки до системы упражнений с интервальным повторением.
Более того, за это время у меня сформировалась чёткая картина дальнейшего развития, появились конкретные идеи по улучшению, и самое главное - я нашёл тот темп и подход, который позволяет двигаться вперёд, не теряя мотивации. Это не может не радовать.
Что дальше?
В следующем посте (возможно 2-х постах) я подробно расскажу:
- основной инсайт, который изменил мой подход к разработке.
- детальные планы на развитие системы, включая ключевую для меня систему тегов.
После этого я перейду к формату "разработка в реальном времени" и буду вести проект параллельно на двух платформах, каждая - со своей уникальной ценностью:
В Дзен вас ждут основные вехи проекта и смысловые открытия. Здесь я буду выкладывать:
- Ежемесячные (а возможно, и еженедельные) итоги с ключевыми инсайтами и выводами.
- Глубокие разборы реализованных модулей и архитектурных решений.
- Крупные обновления системы - что появилось и как это меняет подход к изучению.
- Идеи, лайфхаки и наблюдения об изучении языков, которые рождаются в процессе разработки.
- И многое другое.
В Telegram-канале всё будет происходить здесь и сейчас. Это живой лог разработки:
- Планы и задачи на неделю.
- Итоги недели (месяца): что удалось сделать и в каком виде.
- Фрагменты кода и скриншоты интерфейса.
- Возникающие сложности и способы их решения - в момент, когда они актуальны.
- Мой прогресс: как растут навыки в коде и английском.
Таким образом, в Дзен вы получите выжимку смыслов и результатов, а в Telegram - полное погружение в процесс, где можно следить за каждым шагом, задавать вопросы и видеть, как система растёт в режиме реального времени.
Присоединяйтесь
Если вам интересно, как будет развиваться эта система - подписывайтесь здесь, на Дзен и мой Telegram-канал.
Все статьи вступительной части:
- Разработка - что уже работает в коде (первые результаты) (текущая статья).
7. Планы на ближайшее будущее - на месяц - два (будущая статья).