🔥 Karpathy выпустил nanochat miniseries v1.
Главная идея: мы не оптимизируем одну конкретную модель, а целое семейство моделей, где качество растёт монотонно вместе с вычислительными затратами. Это позволяет строить реальные scaling laws и быть уверенными, что когда платишь за большой прогон, результат оправдает деньги.
В nanochat был сделан упор на полный LLM-пайплайн. Теперь акцент сместился на предобучение как фундамент интеллекта модели.
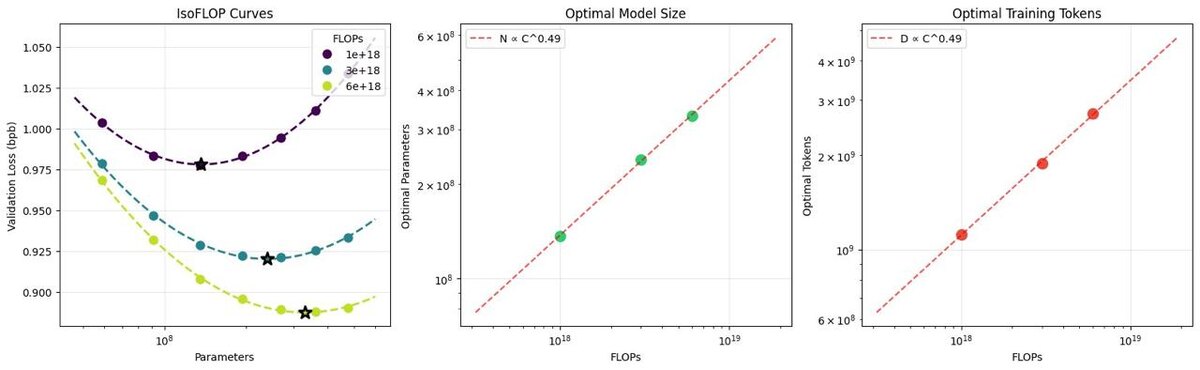
После тюнинга гиперпараметров выяснилось, что nanochat отлично следует законам масштабирования и ведет себя как в Chinchilla: оптимальное соотношение параметров и токенов сохраняется. Причем константа у nanochat примерно 8, а у Chinchilla была 20.
Далее была обучена мини-серия моделей d10...d20. У всех чистые, не пересекающиеся кривые обучения. Чтобы сравнить их с GPT-2 и GPT-3, Karpathy использовал CORE score вместо validation loss. В итоге nanochat корректно ложится на ту же шкалу и показывает, что всё движется в правильном направлении.
Стоимость экспериментов примерно 100 долларов за 4 часа на 8×H100. Уже сейчас можно тренировать вычислительно оптимальные модели и улучшать их просто увеличивая compute. А соответствие GPT-2 пока стоит около 500 долларов, но, по мнению автора, можно довести до менее 100.
Полный разбор и код: github.com/karpathy/nanochat/discussions/420
Смысл: масштабирование работает, пайплайн воспроизводим, и дальше всё упирается только в то, сколько вычислений вы готовы включить.