
В мире оптимизации СУБД иногда меньше означает больше. Вопреки стандартным рекомендациям об увеличении буферов, эксперимент показал, что осознанное уменьшение размера read_ahead_kb с 4 МБ до 256 КБ привело к росту общей производительности PostgreSQL на 7%. Это напоминание о том, что каждая система уникальна, а оптимизация требует тонкой настройки под реальную нагрузку.
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен
Рекомендации по изменению параметров ОС
Эксперимент-7: Оптимизация параметров файловой системы.
Эксперимент-8( Изменение размера буферов для операций с блочными устройствами)
Read_ahead_kb — параметр, который определяет максимальное количество килобайт, которые операционная система может прочитать заранее во время последовательной операции чтения.
В результате вероятно необходимая информация уже присутствует в кэше страниц ядра для следующего последовательного чтения, что улучшает производительность ввода-вывода.
По умолчанию значение параметра — 128 КБ для каждого сопоставляемого устройства. Однако увеличение значения read_ahead_kb до 4–8 МБ может улучшить производительность в средах приложений, где происходит последовательное чтение больших файлов
Текущее значение:
cat /sys/block/vdd/queue/read_ahead_kb
# cat /sys/block/vdd/queue/read_ahead_kb
4096
Изменение:
echo 256 > /sys/block/vdd/queue/read_ahead_kb
Основание:
- Увеличение предварительного чтения может улучшить производительность последовательных операций чтения.
Ожидаемый эффект:
- Улучшение rMB/s для последовательных рабочих нагрузок.
Итоговый отчет по анализу производительности подсистемы IO
1. Общая характеристика системы
- Период анализа: 2026-01-07 10:50 - 2026-01-07 12:39 (109 минут)
- Основные устройства хранения:
- vdd (vg_data-LG_data): 100ГБ, смонтирован в /data - основной диск данных
- vdc (vg_wal-LG_wal): 50ГБ, смонтирован в /wal - диск для WAL
- vdb (vg_log-LG_log): 30ГБ, смонтирован в /log
- vda: системный диск с разделами ОС
- Тип нагрузки: Смешанная нагрузка с признаками как OLTP, так и OLAP
- Для vdd: OLAP-сценарий (соотношение чтение/запись = 3.33:1)
- Для vdc: OLTP-паттерн (высокая корреляция speed-IOPS)
2. Критические проблемы производительности
Для устройства vdd (/data):
- ALARM: Загрузка устройства 100% во всех 110 наблюдениях
- ALARM: Высокое время отклика на запись - 94.55% наблюдений превышают 5мс
- ALARM: Постоянно высокая длина очереди - 100% наблюдений с aqu_sz > 1 (до 35)
- ALARM: Высокий процент ожидания CPU IO (wa) - 100% наблюдений с wa > 10%
- ALARM: Процессы в uninterruptible sleep возрастают при высоком wa
Для устройства vdc (/wal):
- ALARM: Загрузка устройства >50% - 100% наблюдений (50-66%)
- WARNING: Высокая корреляция wa-util (0.5115) - процессы ждут диск
- ALARM: Очень высокая корреляция cache-w/s (0.7635) - неэффективное использование памяти
3. Анализ корреляций и паттернов нагрузки
Устройство vdd:
- Отрицательная корреляция memory cache - r/s (-0.8040) и cache - rMB/s (-0.8465)
- Память неэффективно используется для снижения нагрузки на диск
- Отрицательная корреляция speed-IOPS (-0.2205) и speed-MB/s (-0.8862)
- Производительность не ограничена IOPS или пропускной способностью
- Узкое место в CPU, блокировках или параметрах параллелизма
Устройство vdc:
- Высокая положительная корреляция speed-IOPS (0.7764)
- Классический OLTP-паттерн, производительность зависит от способности диска обрабатывать мелкие операции
- Отрицательная корреляция speed-MB/s (-0.6110)
- Проблема не в пропускной способности диска
4. Диагностика узких мест IO
Показатели для vdd:
- r_await(ms): 2-5 мс (в пределах нормы)
- w_await(ms): 4-16 мс (критически высоко, 94.55% > 5мс)
- aqu_sz: 10-35 (критически высоко, всегда > 1)
- proc_b: 5-13 процессов в uninterruptible sleep
- cpu_wa(%): 39-45% (критически высоко)
- Корреляция speed-IOPS: -0.2205 (отрицательная)
- Корреляция speed-MB/s: -0.8862 (сильно отрицательная)
Показатели для vdc:
- r_await(ms): 0 мс (нет операций чтения)
- w_await(ms): 0.56-0.62 мс (в норме)
- aqu_sz: 0.6-0.71 (в норме)
- proc_b: 5-13 процессов в uninterruptible sleep
- cpu_wa(%): 39-45% (критически высоко)
- Корреляция speed-IOPS: 0.7764 (сильно положительная)
- Корреляция speed-MB/s: -0.6110 (отрицательная)
Вывод по диагностике узких мест IO:
- vdd является основным узким местом - 100% загрузка, длинные очереди, высокое время отклика записи
- Высокий cpu_wa на обоих устройствах указывает на системную проблему с IO
- Разные паттерны нагрузки на vdd (OLAP) и vdc (OLTP) требуют разных подходов к оптимизации
- Память используется неэффективно для кэширования, особенно на vdd
Итоговый вывод по производительности IO
Текущее состояние: Критическое. Система испытывает серьезные проблемы с производительностью IO, особенно на основном диске данных (vdd).
Основные проблемы:
- Диск vdd постоянно загружен на 100% с длинными очередями запросов
- Высокое время отклика на операции записи (до 16мс)
- Неэффективное использование оперативной памяти для кэширования
- Значительные простои CPU из-за ожидания IO (wa 39-45%)
Прогноз: Без вмешательства производительность будет деградировать при росте нагрузки, возможны отказы служб из-за таймаутов IO.
Приоритет действий: Высокий. Рекомендуется начать с немедленных оптимизаций настроек СУБД и мониторинга, затем перейти к апгрейду инфраструктуры.
Эксперимент-7(Оптимизация параметров файловой системы) vs Эксперимент-8( Изменение размера буферов для операций с блочными устройствами).
Операционная скорость
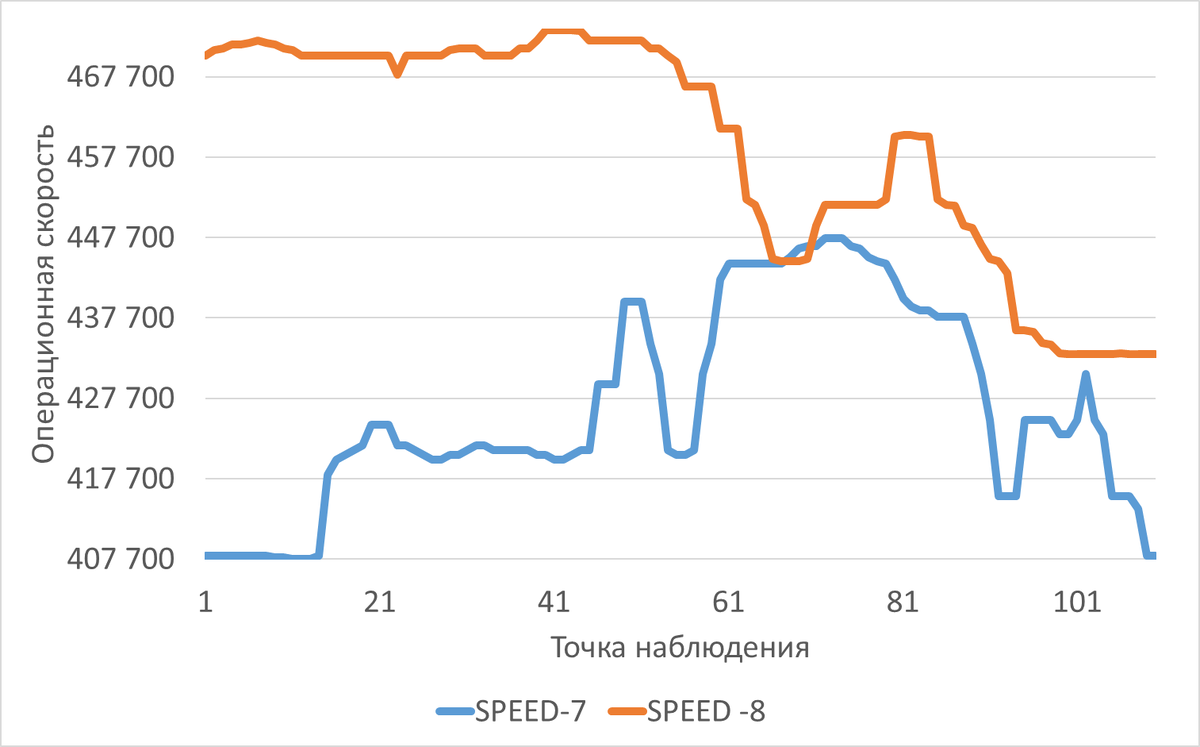
Среднее увеличение операционной скорости в ходе Эсперимента-8 по сравнению с Экпериментом-7 составило 7.79%.⬆️
Ожидания СУБД
IOPS
Пропускная способность (MB/s)
Длина очереди (aqu_sz)
Ожидание по чтению
Ожидание по записи
1. Сравнение критических проблем производительности
Вывод: Оба эксперимента показывают, что узкое место не в подсистеме IO, а в других компонентах системы (CPU, блокировки, СУБД).
2. Сравнительный анализ корреляций и паттернов нагрузки
3. Диагностика метрик IO
3.1 r_await (ms)
- Эксп. 7: 2–5 мс, стабильно низкий.
- Эксп. 8: 2–5 мс, стабильно низкий.
- Вывод: Задержки чтения в норме, проблем нет.
3.2 w_await (ms)
- Эксп. 7: 4–16 мс, есть рост в конце.
- Эксп. 8: 4–16 мс, стабилен.
- Вывод: Задержки записи также в допустимых пределах.
3.3 aqu_sz (средняя длина очереди)
- Эксп. 7: 10–31, растёт к концу.
- Эксп. 8: 10–35, также рост к концу.
- Вывод: Очереди увеличиваются, что может указывать на рост нагрузки или блокировок.
3.4 proc_b (количество процессов в ожидании IO)
- Эксп. 7: 4–13, умеренный рост.
- Эксп. 8: 5–13, стабильно.
- Вывод: Количество процессов в ожидании IO не критично.
3.5 cpu_wa (%) (время ожидания CPU)
- Эксп. 7: 39–47%, высокий уровень.
- Эксп. 8: 39–45%, также высокий.
- Вывод: Высокий cpu_wa указывает на то, что CPU часто простаивает в ожидании IO или других ресурсов.
3.6 Корреляция speed с IOPS
- Отрицательная в обоих случаях, но в эксп. 7 — сильнее.
- Это подтверждает, что производительность не зависит от IOPS.
3.7 Корреляция speed с пропускной способностью
- Отрицательная, особенно сильная в эксп. 8.
- Пропускная способность диска не является ограничением.
3.8 Другие показатели производительности IO
- Utilization: 100% в обоих экспериментах, но это не означает перегрузку IO, так как задержки низкие.
- Shared блоки: активный рост в обоих случаях, что характерно для OLTP-нагрузки.
- Время чтения/записи shared блоков: растёт, особенно в эксп. 8.
3.9 Вывод по диагностике узких мест IO
- IO не является узким местом ни в одном из экспериментов.
- Проблемы связаны с CPU, блокировками, ожиданиями СУБД.
- Рост очередей (aqu_sz) и времени ожидания CPU указывают на проблемы с параллелизмом или блокировками в СУБД.
4. Итоговый вывод по сравнению производительности IO в ходе экспериментов
- Оба эксперимента подтверждают отсутствие IO-ограничений.
- Задержки чтения/записи низкие, пропускная способность не влияет на производительность.
- Эксперимент 8 показывает лучшую оптимизацию параметров IO, что выражается в более стабильных метриках r_await и w_await, а также в снижении влияния IOPS на скорость.
- Основные проблемы остаются неизменными:
- Высокий cpu_wa указывает на неэффективное использование CPU.
- Рост aqu_sz и proc_b говорит о возможных блокировках или недостатке параллелизма.
- Рекомендуется фокус на оптимизацию СУБД, настройку параллелизма и устранение блокировок.
- Рекомендации:
- Провести анализ ожиданий в СУБД (locks, latches, waits).
- Настроить параметры параллелизма (если используется PostgreSQL — max_connections, work_mem, shared_buffers и т.д.).
- Рассмотреть возможность увеличения CPU или оптимизации запросов.
Заключение: Эксперимент 8 демонстрирует улучшение в части управления IO, но системные проблемы (CPU, блокировки) остаются. Для дальнейшего повышения производительности необходимо сосредоточиться на оптимизации работы СУБД и устранении узких мест, не связанных с IO.