Современные LLM позволяют обрабатывать большие объемы данных, выявлять неочевидные закономерности и составлять прогнозы. Эксперт рассказал, как применяется ИИ в медицинских исследованиях
Об авторе: Артур Зиннуров, дата-сайентист в Secure eResearch Platform (SeRP) Swansea University.
Глоссарий:
LLM — нейросеть, обученная на большом объеме данных, которая понимает запросы на естественном, человеческом языке и умеет выполнять различные задачи: анализировать информацию, находить нужные данные, генерировать тексты на их основе и т. д.
LLM-агент — инструмент на базе LLM, который умеет не только отвечать на запросы, но и выполнять определенные действия, например отслеживать конкретные побочные эффекты лекарств или находить взаимосвязи между заболеванием и внешними факторами.
Скрипты для LLM — небольшие программы, состоящие из нескольких шагов, которые автоматически взаимодействуют с LLM: формируют запросы, обрабатывают ответы и вызывают нужные инструменты
Big Data — большие объемы данных, например медицинские карты пациентов в больнице, снимки МРТ, данные различных датчиков и приборов. Вручную обработать Big Data практически невозможно, поэтому с ними работают LLM.
SQL-скрипты (SQL-шаблоны, SQL-структуры) — готовые наборы команд, которые автоматически выполняют определенные операции с базой данных, отправляя им SQL-запросы, например заполняют таблицы, проверяют данные, делают аналитику.
SQL-движок — это компонент базы данных, который выполняет SQL-запросы: читает, записывает, обновляет и ищет данные.
Веб-приложение — программа, которая работает через интернет прямо в браузере, без установки на компьютер или телефон.
Фреймворк FastAPI — инструмент для быстрого создания веб-приложений.
Docker — инструмент, который упаковывает приложение с нужными файлами и настройками в «контейнер». Его можно запустить на любом компьютере, и он всегда будет работать одинаково.
Библиотека OMOP — набор стандартов, словарей и инструментов, созданных для унификации медицинских данных.
Вебхук-клиент — программа или сервер, который принимает входящие уведомления от другого сервиса по заранее указанному URL-адресу.
Туннельное соединение — способ передать данные через интернет в защищенном «туннеле», скрывая их от внешнего доступа.
GPU-сервер — сервер, в котором установлены графические процессоры (GPU), используемые для задач, требующих высокой вычислительной мощности, например настройки и обучения нейросетей.
Коннектор — компонент, который обеспечивает подключение одной системы к другой.
YAML — человекочитаемый формат для хранения настроек и конфигураций.
Метаданные — описательная информация, которая объясняет, что представляют собой основные данные: их структура, формат, источник, время создания и т. д.
Объектное хранилище — способ хранения данных, где файлы сохраняются как отдельные «объекты» с уникальным ID и метаданными, а не как части папок или блоков.
Версионирование — способ хранить и отслеживать разные версии одного и того же файла, документа или кода.
Git-репозиторий — место, где сохраняются файлы проекта, их версии, изменения и история работы.
Retrieval-Augmented Generation (RAG) — метод, при котором LLM перед генерацией ответа сначала ищет релевантную информацию во внешних источниках (документах, базах данных, поиске), а затем использует найденные данные для более точного ответа.
FAISS (Facebook AI Similarity Search) — библиотека от Meta (с 21 марта 2022 года решением суда организация признана в России экстремистской и запрещена) для быстрого поиска похожих изображений, текстов, объектов.
Векторное представление — способ превратить объект (слово, текст, картинку) в набор чисел, которые отражают его смысл или признаки. Векторная информация используется для работы с AI-агентами.
Кластеризовать — сгруппировать объекты по сходству так, чтобы похожие оказались в одном кластере, а непохожие — в разных.
Как можно применять ИИ в медицинских исследованиях
LLM (Large Language Model, большие языковые модели) автоматизируют сложные аналитические задачи в медицине, что помогает быстрее и точнее проводить исследования. Если раньше на поиск и сопоставление информации приходилось тратить несколько дней или даже недель, современные технологии позволяют в течение дня переработать большие объемы информации и предоставить специалистам структурированную выжимку, которую можно использовать в дальнейшей работе.
Еще один способ использования LLM в медицине — оптимизация работы. Например, ИИ-модели способны составить дизайн исследования на основе имеющихся данных, чтобы обеспечить объективность, достоверность и обоснованно ответить на поставленные вопросы. Также LLM оценивают данные в реальном времени, чтобы скорректировать ход исследования и предложить новые варианты исследовательских работ.
Я рекомендую применять медицинские ИИ-агенты для следующих задач:
- Автоматизация. Выполнение рутинных задач по сбору и обработке больших объемов данных.
- Аналитика. Выявление причинно-следственных связей и прогнозирование.
- Оптимизация. Предложение изменений и корректировок на основе данных в реальном времени.
Как работать с Big Data при помощи ИИ
Один из способов сбора данных для обучения LLM, который я применяю в своих проектах, — использование «веб-краул дата». Это данные, собранные программой-роботом при сканировании веб-страниц для поиска и индексации информации.
Также для получения данных я использую медицинские журналы — PubMed или arXiv. Некоторые лицензированные источники могут быть недоступны для обработки, поэтому нужно следить, чтобы они распространялись по лицензии MIT. Использование Big Data значительно обогащает исследования. Обрабатывая и сопоставляя большие пласты информации, можно:
- выявить редкие побочные эффекты при употреблении определенных медикаментов;
- составить типичный прогноз развития заболевания у конкретного сегмента аудитории;
- выявить ранние предикторы заболеваний (повышение концентрации определенных белков, которое связано с риском развития патологии. — «РБК Тренды»);
- составить индивидуализированные протоколы лечения.
Почему для медицины нужно использовать локальные LLM
Я рекомендую использовать собственные LLM для обеспечения конфиденциальности и безопасности чувствительных данных. В исследовательских и корпоративных средах, по моему опыту, важно выстраивать ИИ-инфраструктуру, которая позволяет специалистам работать с SQL-скриптами и анализировать информацию без необходимости отправлять реальные данные в облачные LLM. Такой подход показал свою эффективность, особенно для молодых исследователей и аналитиков: он дает им возможность тестировать гипотезы и обучаться на реальных сценариях при полной изоляции данных.
В ряде случаев я советую разрабатывать специализированные LLM под конкретные проекты. Например, при интеграции инноваций в области health data целесообразно создать LLM-агента для поиска в базе данных конкретного сегмента пациентов — например, 18–25 лет, страдавших астмой во время пандемии COVID-19. Подобные решения доказали свою эффективность, позволяя сократить время анализа с нескольких недель до нескольких минут, при этом сохраняя строгие стандарты безопасности и конфиденциальности данных.
Например, для одного из проектов SeRP я создал локально размещенную LLM на базе платформы Ollama. Для управления компонентами использовал веб-приложение, написанное на фреймворке FastAPI и развернутое в контейнерах Docker. Для хранения и использования данных выбрал библиотеку OMOP, которая содержит информацию, конвертированную из разных источников в единый формат. Также я настроил уведомления о выгрузке данных в Slack с помощью вебхук-клиента через защищенное туннельное соединение. Выгрузку можно произвести только после одобрения ответственного сотрудника.
Я развернул систему внутри Trusted Research Environment (TRE) — защищенного сервера, где хранятся чувствительные данные. Она работает на GPU-сервере Nvidia A40, который обеспечивает необходимую мощность для LLM среднего размера. А платформу Ollama настроил так, чтобы она могла работать в автономном режиме.
Разработанный агент отвечает на естественные запросы, например: «Посчитай количество пациентов в Уэльсе возраста 40–60 лет, болеющих туберкулезом в 2023 году». После интерпретации запроса LLM определяет нужный SQL-шаблон, подставляет параметры и формирует SQL-запрос.
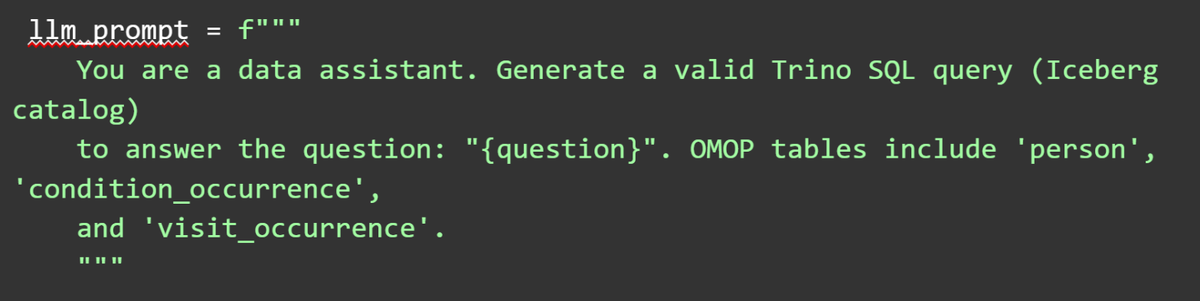
Для обработки запросов и доступа к данным я использовал конфигурацию «распределенный SQL-движок Trino + коннкетор Apache Iceberg». Iceberg создает дополнительный слой метаданных для больших таблиц в объектном хранилище, сохраняет историю изменений и поддерживает версионирование схемы данных. Агент подключается к базам данных через клиентскую библиотеку Trino, которая обеспечивает согласованное управление метаданными.
Я разработал правила, которые ограничивают область поиска LLM. Например, здесь можно увидеть yaml-файл, которые показывает SQL-шаблон по условию возраста. Шаблоны позволяют использовать только предварительно утвержденные OMOP-таблицы. Исследователи могут видеть все шаблоны, а версии контролируются через Git-репозиторий.
Сложным моментом стало преобразование естественного языка в SQL-структуры. Чтобы понять логику медицинских кодов и терминов, я использовал метод Retrival-Augmented Generation (RAG) и инструмент FAISS (Facebook AI Similarity Search). Эти инструменты помогают преобразовать предложения естественного языка в векторное представление для AI-агента и кластеризовать их. После этого можно найти схожие случаи в базах данных.
После извлечения данных запускается конструктор SQL-запросов, который создает SQL-инструкции на основе yaml-шаблона и полученных с помощью LLM диагнозов. Trino отправляет запрос и получает запрошенные данные. Также я создал небольшой сводный запрос, чтобы можно было увидеть превью возвращенных данных.
Пример того, как работает SQL-запрос по заданным параметрам.
Благодаря собственной LLM мы обеспечили безопасность чувствительных данных и плавную автоматизацию исследований. Использование новых технологий стало доступным для всех сотрудников, потому что общаться с LLM можно на естественном языке.
Создавая собственную LLM, я советую учитывать экономическую целесообразность — на начальном этапе разработка может быть дорогой, так как потребуются значительные мощности графического процессора. Но собственный агент обеспечивает долгосрочные преимущества для исследовательских институтов, которым необходима постоянная обработка больших объемов информации.
Мои подходы по выстраиванию синергии между LLM и человеком
Главная проблема LLM на данный момент — так называемые галлюцинации, которые требуют человеческого контроля. Искусственный интеллект может выдать ошибочную или придуманную информацию — и этого не избежать, так как «галлюцинации» появляются из-за принципа работы самих генеративных моделей.
LLM не способна критично оценить свою работу — насколько данные в ней являются полными, качественными и определенными. Из-за этого могут возникнуть ложные предположения и прогнозы. Также агентам недоступны сложные рассуждения и взгляд на исследование под нетривиальным углом.
Однако LLM могут ускорить исследования и помочь избежать ошибок из-за человеческого фактора. Поэтому я считаю, что в будущем всем исследователям понадобятся навыки работы с ИИ. Например, специалисты могут автоматизировать задачи по генерации скриптов для LLM или форматированию данных с помощью инструмента n8n.
Искусственный интеллект уже плотно проникает в медицинскую среду. Например, LLM уже использовалась в исследованиях по радиологии — она помогала отсортировать данные пациентов, чтобы специалисты смогли отобрать карточки с подозрениями на отклонения от нормы.
➤ Подписывайтесь на телеграм-канал «РБК Трендов» — будьте в курсе последних тенденций в науке, бизнесе, обществе и технологиях.