🚀 Вышел QwenLong-L1.5 - модель для long-context reasoning, которая на длинных контекстах конкурирует с GPT-5 и Gemini-2.5-Pro.
Коротко о модели
- 30B параметров, из них 3B активных
- Заточена под рассуждение на очень длинных контекстах
- Полностью открыты веса, код обучения и рецепты данных
Ключевые показатели:
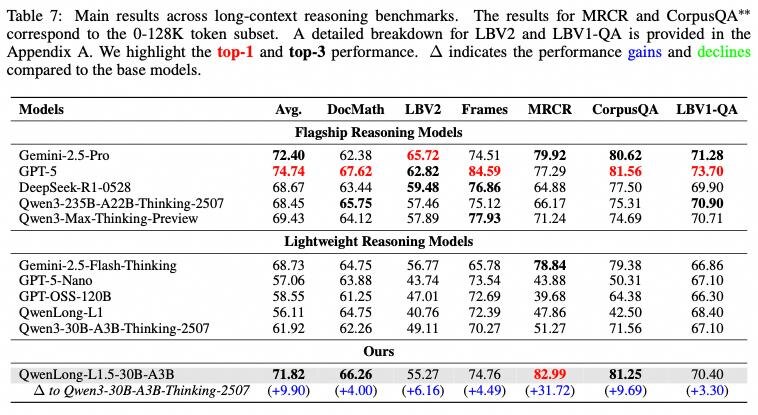
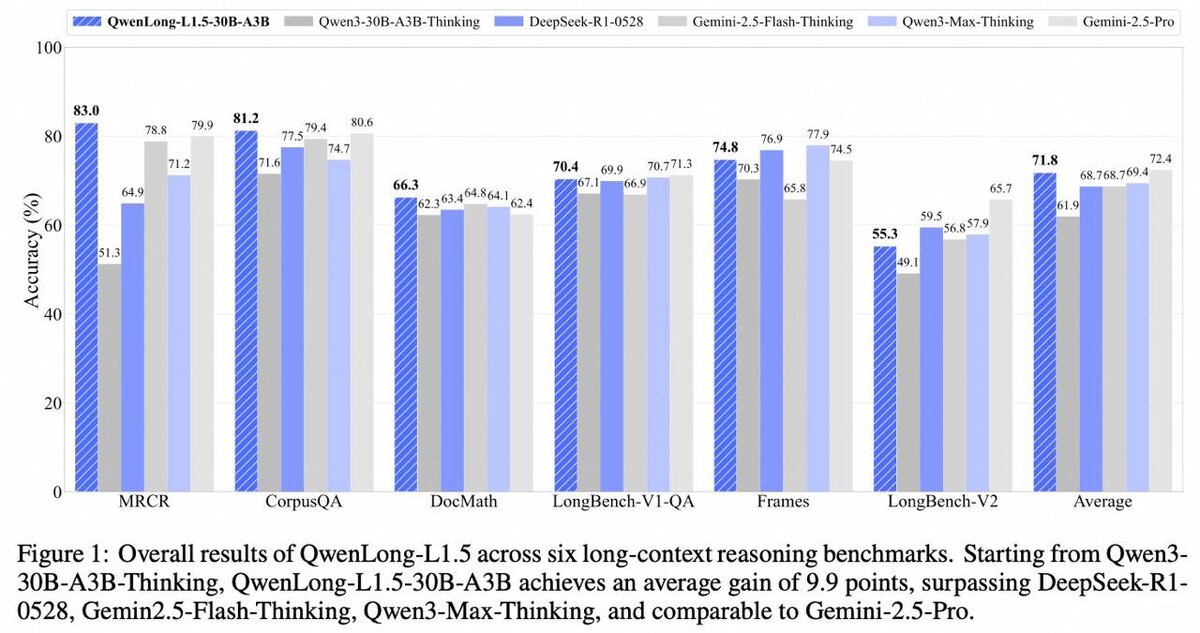
- +31.7 балла на OpenAI MRCR при контексте 128K - SOTA среди всех моделей
- На уровне Gemini-2.5-Pro на 6 крупных long-QA бенчмарках
- +9.69 на CorpusQA
- +6.16 на LongBench-V2
Что интересного.
1. Синтетические данные в масштабе
14.1K длинных reasoning-сэмплов из 9.2B токенов без ручной разметки.
Средняя длина - 34K токенов, максимум - 119K.
2. Стабильное RL-обучение
Используется балансировка задач и Adaptive Entropy-Controlled Policy Optimization (AEPO), что позволяет стабильно обучать модели на длинных последовательностях.
3. Архитектура с памятью
Итеративные обновления памяти за пределами окна 256K токенов.
Результат - +9.48 балла на задачах с контекстом от 1M до 4M токенов.
QwenLong-L1.5 - это один из самых сильных open-source шагов в сторону реально масштабируемого ризонинга с длинным контекстом
Модель интересна не только результатами, но и тем, что весь стек обучения открыт.
GitHub: https://github.com/Tongyi-Zhiwen/Qwen-Doc
Paper: https://modelscope.cn/papers/2512.12967
Model: https://modelscope.cn/models/iic/QwenLong-L1.5-30B-A3B
HF: https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B
#AI, #LLM, #opensource, #long #Owen