
Гибкая автоматизация публикаций по расписанию без ручной рутины | Автор: Марина Погодина
Когда меня спрашивают про make.com автоматизация и расписания постинга, я уже не начинаю с «это удобно», я начинаю с «это удобно, но вы в России». Автоматизация публикаций make.com в вакууме выглядит идеально: контент уходит сам, соцсети живут своей жизнью, а маркетолог в это время спокойно допивает кофе (если повезёт, не холодный). Но как только в уравнение добавляется 152-ФЗ, локализация данных и новые требования к согласию, вся эта красота начинает трещать. В этой статье я разберу, как настроить расписание публикаций в Make.com так, чтобы и автоматизация работала, и юристы спали спокойно, и Роскомнадзор не дышал в спину. Текст рассчитан на российских специалистов, которые работают с контентом, нейросетями, автоматизацией и не хотят строить «теневую» архитектуру.
И да, у нас будет реальный кейс. Назовём её Света из маркетинга. Света ведёт несколько VK-сообществ и Telegram-канал сети образовательных курсов и мечтает перестать сидеть ночами с планером и напоминаниями. Я покажу, как мы со Светой выстраивали автоматизацию публикаций через Make.com, что пришлось поменять из-за 152-ФЗ и новых требований к согласию, где она почти попала на штраф и как мы разрулили историю. А заодно соберу всё это в понятную пошаговую схему, которой можно пользоваться как опорой, когда вы будете строить свои сценарии.
У меня был период, когда я на автоматизацию публикаций смотрела как на чисто техническую задачу: подключили Make.com, подружили его с контент-таблицей, раскидали расписания, проверили пару тестовых постов — и готово. Потом я ушла глубже в AI governance, внутренний аудит и ИТ-риски, и картинка радикально изменилась. Оказалось, что расписание публикаций — это не про «в какой час выйти посту», а про то, через какие сервера прошли персональные данные, кто их видел, как это задокументировано и чем вы будете прикрываться, если что-то поедет не туда. Звучит мрачно, но на самом деле это просто другая оптика.
Света пришла ко мне примерно с такой установкой: «Марин, я нашла классный туториал по Make.com, всё красиво, мультисценарии, автопостинг в VK и Telegram, но мне юрист сказал, что так нельзя, потому что данные уходят за границу. Они же просто имена и логины, разве это критично?» И вот в этот момент начинается интересное. Для российского бизнеса после 1 июля 2025 года критично почти всё, что похоже на персональные данные, а Make.com в этом уравнении — иностранный облачный сервис, который живёт по своим правилам (и своим законам). Поэтому я ей предложила: давай сделаем не «как в туториале», а как выдержит проверку Роскомнадзора.
Чтобы было проще визуализировать, как это всё связывается, я часто рисую архитектурные схемы и дорожки данных. Чуть ниже как раз такая, в формате схемы маршрута публикаций, которую можно примерить к своему проекту и честно ответить себе: у меня здесь всё в белую или нет.
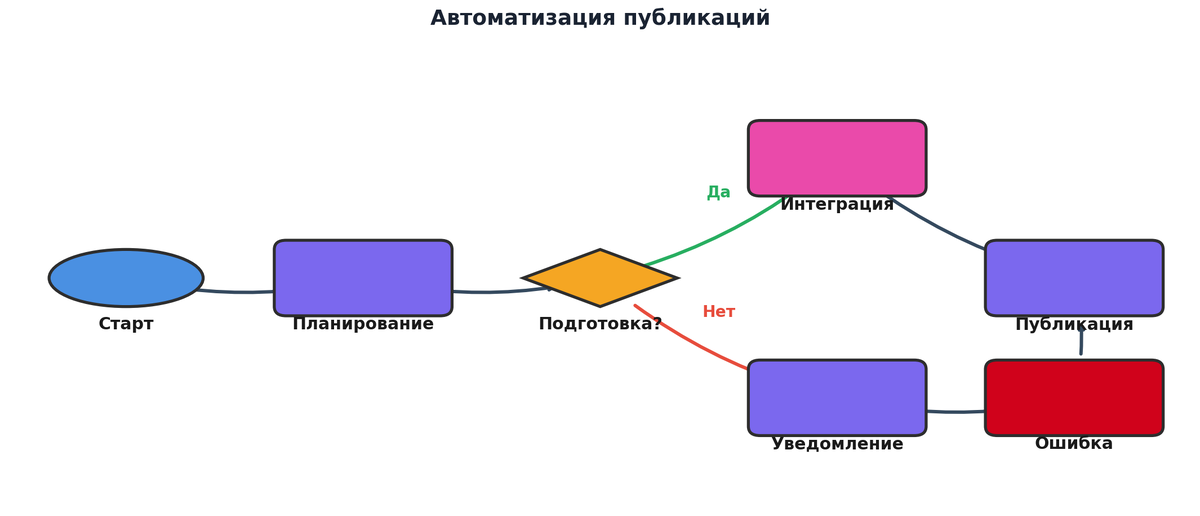
Как работает автоматизация публикаций в Make.com и что в ней опасно для российских компаний
Что на самом деле делает Make.com, когда вы ставите «пост по расписанию»
Если разобрать автоматизацию публикаций make.com на атомы, окажется, что это всего лишь конструктор: триггеры, действия, фильтры, расписания. На поверхностном уровне схема проста: вы создаёте сценарий, подключаете источники контента (таблица, база, CMS), настраиваете модули для VK, Telegram, Дзен или куда вы там публикуетесь, задаёте расписание — и дальше Make.com ходит по этим шагам сам, без вашего участия. Внутри же каждый такой шаг — это запрос по сети к стороннему API, передача данных, логирование этих данных на стороне сервиса и хранение истории. И вот тут появляются риски.
Когда вы в Make.com создаёте модуль «создать пост в VK» с подтягиванием, например, имени пользователя в текст или UTM-метки с ID, вы уже запускаете обработку персональных данных. По 152-ФЗ обработка — это не только хранение, но и сбор, передача, систематизация, использование, удаление. А Make.com, напомню, живёт не в российском дата-центре. Это означает, что даже если вам кажется, что вы «ничего личного не передаёте, просто логин», закон может считать это персональными данными. В итоге у нас получается удобный сервис, который по щелчку нарушает требование о первичной обработке на территории РФ (звучит жёстко, но так и есть).
Чтобы проще отследить, на каком шаге вы переходите черту, я обычно разбираю путь данных покомпонентно и прямо подсвечиваю, где начинается риск. Это можно сформулировать коротко:
Как только вы передали в Make.com что-то, по чему можно идентифицировать человека (даже косвенно), вы включили режим персональных данных, а значит — режим закона.
Почему место хранения и первичная обработка данных стали критичными после 2025 года
С 1 июля 2025 года для России игра пересобралась: теперь все персональные данные граждан РФ должны первично обрабатываться на российских серверах. Не «желательно», не «по возможности», а обязаны. Это значит, что первые операции записи, накопления и хранения информации о человеке должны происходить в инфраструктуре, физически расположенной в России. Make.com из коробки эту задачу не решает: его сервера находятся за пределами РФ, он логирует запросы и хранит историю запусков сценариев там, где это удобно ему, а не вашему комплаенсу. Для обычного пользователя это незаметно, но для юриста по 152-ФЗ — это красная лампа.
Когда я анализирую архитектуру автоматизации, я всегда задаю один и тот же вопрос: где в первый раз данные «приземляются» в системе. Если у Светы форма подписки, встроенная в сайт, сразу отправляет email и имя в Make.com, то первичная обработка проходит не в России. Если же форма сохраняет данные в российскую базу, а потом Make.com забирает только технический идентификатор без привязки к личности, то риск снижается. Это не превращает иностранный сервис в отечественный, но меняет юридическую картинку. Для автоматизации расписания публикаций это особенно чувствительно, потому что сценарии в Make.com часто строятся как раз «от формы к посту» — и вот тут приходится притормаживать фантазию и возвращать данные в Россию.
Для закрепления этого принципа полезно держать под рукой одну простую фразу. Я обычно проговариваю её с командами вслух, чтобы потом на встречах никто не говорил «я думал, это по-другому».
Первичный дом для данных пользователей должен быть в России, а всё остальное — только гостевые визиты.
Как Роскомнадзор проверяет ваши публикации и откуда берутся штрафы
После запуска автоматизированной платформы мониторинга Роскомнадзора иллюзия «мы маленькие, нас не найдут» окончательно рассыпалась. Теперь проверки не зависят от человеческого ресурса: сканируются сайты, формы, публичные политики, иногда изучается поведение форм подписки, а дальше это сопоставляется с тем, что указано в уведомлении в реестре операторов. Если у вас в уведомлении написано «обработка только на территории РФ», а на деле форма стучится прямиком в Make.com и дальше в Google Sheets, у регулятора появляется отличный повод задать вопросы. При желании он найдет и ваши автопостинги, особенно если вы в контенте указываете что-то личное: имена учеников, отзывы с никнеймами, персонализированные офферы.
Когда мы со Светой разбирали её первый черновой сценарий, мы быстро нашли два слабых места: во-первых, её форма заявки на курс отправляла данные сразу в Google-таблицу через Make.com; во-вторых, в расписании публикаций были посты с обращением по имени и отсылкой к конкретным действиям пользователя. Если бы это всплыло при проверке, можно было бы схлопотать штраф на миллионы, и размер компании тут вообще не аргумент. Я заметила, что как только команда один раз видит реальный протокол проверки и размер санкций, все разговоры про «это же просто автоматизация, не утечка» сами собой заканчиваются. Автопостинг в глазах закона — тоже обработка.
Получается, что прежде чем думать о красоте контент-плана, нужно честно посмотреть на инфраструктуру: где живут данные, кто к ним ходит, что записывает Make.com, и какое у вас основание это всё делать. На этом фундаменте уже можно строить безопасное расписание публикаций, а не мина замедленного действия.
Как спроектировать архитектуру расписания публикаций в Make.com под 152-ФЗ
Как разделить «российский контур» и Make.com, чтобы остаться в белой зоне
Ключ к безопасной автоматизации в Make.com для российских компаний — в разделении зон ответственности: российский контур отвечает за первичную обработку и хранение персональных данных, а Make.com — за оркестрацию и механику расписания. Когда я рисовала схему для Светы, мы начали именно с этой границы. Всё, что связано с именами, телефонами, email, идентификаторами конкретных людей, уходит в российскую базу: это может быть отдельный сервер, защищённое облако в России или даже CRM, которая сертифицирована по требованиям локализации. Make.com видит только те фрагменты, которые нельзя увязать с личностью, или получает обезличенные идентификаторы, сопоставление которых происходит уже внутри российского слоя.
На практике это означает, что сценарий перестаёт быть «форма — Make.com — соцсеть» и превращается в цепочку «форма — российская БД — логика обработки — Make.com — соцсеть». Да, это чуть сложнее, чем взять готовый шаблон на YouTube, но это архитектура, за которую не стыдно показываться юристам. Я поняла, что как только команда принимает эту логику, разговор про make.com автоматизация становится гораздо спокойнее: мы не боремся с сервисом, мы просто ставим его на правильное место в общей схеме. В случае Светы это означало перенос всех форм и лид-магнитов на российский сервер и полную вычистку персональных атрибутов из данных, которые уходят в Make.com.
Чтобы не потеряться в этом делении, я часто озвучиваю простое правило. Оно звучит почти по-домашнему, но мозг его хорошо запоминает.
Всё «человеческое» — имена, e-mail, телефоны — живёт в России, а в Make.com попадают только «машинные» кусочки, без лица и паспорта.
Какие данные можно отправлять в Make.com без риска, а какие нужно оставлять в РФ
Когда мы доходим до конкретики, обычно начинается спор: что считать персональными данными, а что нет, что можно безболезненно слать в Make.com, а что лучше даже не пытаться. Я не юрист, но как человек из ИТ-рисков и аудита я опираюсь на формулировки закона и практику проверок. Всё, что явно или в комбинации позволяет идентифицировать человека, лучше из иностранного контура убрать или анонимизировать. Это не только ФИО и телефоны, но и устойчивые идентификаторы аккаунтов, e-mail, связка «ник плюс город», иногда даже уникальные ID в вашей системе, если они жёстко привязаны к конкретному пользователю. В автоматизации расписаний это всплывает, например, когда вы хотите подставлять в текст поста имя того, кто оставил заявку, или подбирать предложения по истории действий пользователя.
Свете пришлось перепридумать часть контент-плана, потому что она очень любила публиковать истории учеников с почти полными данными: имя, город, иногда даже кусочки их переписок из мессенджера. В чисто ручном режиме это и так погранично, но когда это загоняется в конвейер Make.com, риски вырастают. Мы оставили в автоматизированной части только обезличенные кейсы, а всё, что с личными деталями, перевели в ручной формат и отдельный согласовательный процесс. Звучит старомодно, но иначе пришлось бы городить такой маштаб анонимизации, что проще было не тащить эти данные в иностранный сервис вообще.
Чтобы не запутаться, мы разложили параметры по трём корзинам и договорились их придерживаться. Я озвучу их коротко.
- Категория А: чисто технические данные (ID поста, время публикации, тип канала) — можно в Make.com.
- Категория Б: полуидентифицирующие штуки (UTM с зашифрованным ID, агрегированные метрики) — можно, но аккуратно.
- Категория В: всё, что явно указывает на человека (имя, почта, логин, телефон) — оставляем в РФ.
Как встроить Make.com в общую систему с российскими сервисами
Когда базовый принцип разделения контуров понятен, начинается самое интересное — сборка живой системы. В российских реалиях Make.com редко живёт в одиночестве, его обычно окружают отечественные сервисы: CRM на российских серверах, рассылщики с локализацией данных, аналитика типа Яндекс.Метрики, VK и Telegram как основные каналы. Моя задача как AI Governance & Automation Lead — сделать так, чтобы Make.com стал не центром вселенной, а аккуратным оркестратором, который дергает нужные ниточки, не вытаскивая наружу лишнего. Это означает, что расписание публикаций часто строится через связку: российский источник данных — Make.com — API соцсети, без промежуточного хранения чувствительной информации в самой Make.
В проекте со Светой мы выбрали такую комбинацию: контент-план и статусы материалов живут в российском облаке, которое соответствует требованиям по защите информации, а Make.com забирает только технический набор: текст поста, ссылки, метки времени, идентификатор сообщества. Никаких персонализированных обращений «Светлана, вот ваш отчёт», никаких e-mail внутри текстов, которые приходят из CRM. На первых порах ей было неудобно — привычка писать «теплее» резалась архитектурой, — но когда мы посчитали риски штрафа и возможные репутационные потери, её энтузиазм к обезличиванию резко вырос. Зато сценарии Make.com стали значительно чище и проще для аудита.
Это означает, что make.com автоматизация в России реалистична, но требует честного дизайна: не строить из Make.com «вторую CRM», не складировать там логины и письма, а использовать как связующее звено между уже легальными, корректно настроенными системами. Тогда расписание публикаций превращается из потенциальной угрозы в нормальный рабочий инструмент.
Как грамотно настроить расписание публикаций Make.com технически
Как использовать триггеры и планировщик Make.com без нарушения 152-ФЗ
Если абстрагироваться от юридической части, настройка расписания в Make.com элементарна: вы создаёте сценарий, добавляете модуль Scheduler и указываете, когда он должен запускаться — раз в час, в 9 утра по будням, каждые 15 минут и так далее. Дальше сценарий забирает данные из источника и создаёт посты в нужных каналах. Нюансы начинаются, когда мы вспоминаем, что источник и состав данных ограничены законом и нашей собственной архитектурой. В истории со Светой мы как раз столкнулись с тем, что её первый инстинкт был: «пусть Make.com сам забирает новые заявки из формы и сразу формирует посты с отзывами». Красивая картинка, но первичная обработка улетает за границу.
На практике я предложила ей разделить логику. Scheduler в Make.com запускался каждый час и обращался не к форме, а к российской базе, где уже лежали отобранные и обезличенные материалы для постов. Там же, на российской стороне, крутилась логика, которая проверяла, есть ли согласие человека на публикацию его истории. Make.com видел только текст, картинку и параметры расписания. Я заметила, что такое разделение сначала кажется избыточным, но через пару недель работы воспринимается как норма. Мы просто переносим «умную» часть, связанную с людьми, в безопасную зону, а в Make оставляем только автоматику, близкую к технической.
Чтобы не запутаться в настройке, полезно держать в голове одну связку, она простая.
Триггер и планировщик в Make.com могут управлять временем и порядком, но не должны быть первым, кто видит данные пользователя.
Как организовать таблицу контента и статусы для автопостинга
В любой автоматизации расписания публикаций неизбежно появляется «источник правды» — таблица или база, где лежит контент-план, статусы материалов, даты выхода, каналы. Я обычно рекомендую хранить эту таблицу в российском контуре: может быть Notion, хостящийся в РФ (если такой найдётся), но чаще это отечественный аналог, собственная база или защищённое облако. Для Светы мы выбрали российское облачное хранилище с таблицами, куда добавили поля: текст поста, ссылка на медиафайл, дата/время публикации, список каналов, статус (черновик, готов к публикации, опубликован), а также технический ID записи. Make.com подключался к этой таблице через API и работал только с теми записями, у которых статус «готов к публикации» и время выхода меньше или равно текущему моменту.
Звучит как обычная инженерная рутина, но именно здесь часто происходит самое болезненное: некоторые тянутся добавить в таблицу имя автора, ссылку на пользователя, комментарии с личными данными. Вот тут я начинаю тормозить процесс и спрашивать: зачем эти поля должны видеть иностранные сервисы. Если это критично только для внутренней команды, их можно вынести в соседнюю таблицу, которая не подключена к Make.com. Свете поначалу казалось, что так неудобно (ещё одно место, куда нужно смотреть), но когда она увидела, как чистится логика сценариев и как просто объяснить аудитору, какие поля уходят в Make, а какие нет, сопротивление заметно упало.
Чтобы эта таблица стала реально рабочей, я всегда ввожу правило по статусам. Оно звучит чуть академично, но экономит десятки часов на разбор провалов публикаций.
Статус «готов к публикации» должен означать, что пост можно отправлять хоть сейчас, без дополнительных проверок и дописываний.
Как тестировать и мониторить расписание публикаций, чтобы не ловить сюрпризы
После того как расписание настроено и сценарий в Make.com крутится сам, очень хочется выдохнуть и уйти пить чай. В реальности именно здесь начинается самое уязвимое место: если не настроить мониторинг и логи, можно неделями не замечать, что часть постов не уходит, какие-то тексты публикуются дважды, а какие-то заваливаются ошибками API. Роскомнадзор тут, кстати, тоже не дремлет, потому что ошибки иногда проявляются в виде некорректной обработки согласий или рассинхронизации статусов. На практике я всегда прошу команды выделить время на два типа тестов: технические (правильно ли отрабатывает расписание, нет ли сбоев) и содержательные (точно ли не уехали никакие персональные данные в публичный пост).
Со Светой мы завели отдельный лог в российском контуре, куда Make.com при каждом успешном или неуспешном публикации отправлял короткую запись: ID поста, время, канал, статус. Да, это ещё один API-запрос, но он позволяет пройтись по истории и увидеть, что именно вышло в эфир. Плюс в Make.com мы включили внутренние логи и раз в неделю просматривали последние выполнения сценариев. Я подумала, что буду делать это сама, но быстро оказалось, что ей самой интересно отслеживать, как живёт система. На третьей неделе она уже по своей инициативе прислала мне сообщение: «Я нашла, почему один пост не вышел, там у нас статус не тот стоял 🙂». Вот тогда я поняла, что автоматизация перестала быть черным ящиком и стала нормальным инструментом.
Это означает, что настройка расписания публикаций Make.com — это не только про триггеры и время, но и про живую дисциплину: где лежит лог, кто его смотрит, как часто вы делаете ревью сценариев и поправок. Без этого любая красота оркестровки со временем превращается в хаос.
Как согласия, уведомления и журналы сочетаются с автоматизацией расписаний
Зачем нужен отдельный документ согласия, если вы «просто публикуете посты»
Там, где технические специалисты обычно расслабляются, юристы только разминаются. Согласие на обработку персональных данных в России после 1 сентября 2025 года стало отдельной историей: его больше нельзя прятать в Политику обработки или пользовательское соглашение, оно должно жить отдельно, быть конкретным и осознанным. Как это связано с автоматизацией расписания публикаций? Напрямую: если вы в своих публикациях используете что-то, связанное с конкретными людьми (истории, отзывы, персонализированные обращения), вам нужно отдельное согласие на такую обработку и возможную передачу данных третьим лицам. Да, даже если вы думаете, что там нет ничего страшного (я тоже раньше так думала, пока не увидела пару протоколов проверок).
В кейсе со Светой мы заново переписали форму согласия для учеников. В неё добавили пункты про использование обезличенных историй в маркетинговых материалах и возможность автоматизированной обработки через интеграционные сервисы. Не с перечислением конкретных брендов, а с описанием сути: оркестрация и техническая доставка контента. Это не даёт карт-бланш на левые эксперименты, но создаёт юридическую основу для того, что реально происходит в архитектуре. Без такого согласия любой автоматизированный пост с элементами истории пользователя превратился бы в потенциальный риск, особенно если дорога данных проходит через Make.com.
Чтобы упростить себе жизнь, я предлагаю всегда задавать один вопрос при проектировании любых расписаний в Make.com. Он звучит немного занудно, но зато предельно честно.
Если пользователь попросит показать ему, что я с ним делаю, смогу ли я это описать на одном листе бумаги, не стесняясь ни одного шага (хотя, ладно, листа иногда не хватает).
Как уведомление Роскомнадзора связано с вашим сценарием в Make.com
Уведомление Роскомнадзора — это тот документ, о котором вспоминают в последний момент, а зря. По-хорошему, оно должно быть подано до начала обработки персональных данных, а не «как-нибудь потом, когда отдел юридический будет свободен». В нём вы описываете цели обработки, состав данных, категории субъектов, способы обработки и в общем виде — какие инструменты используете. Если вы всерьёз встраиваете Make.com в свою архитектуру, имеет смысл отразить, что часть обработки автоматизирована с использованием интеграционных сервисов, пусть и без передачи им первичных персональных данных. В противном случае картинка в уведомлении и реальная инфраструктура будут отличаться, и при проверке это всплывёт.
Когда мы со Светой прошлись по её уведомлению, оказалось, что оно вообще не обновлялось с 2022 года. В нём было написано что-то вроде «обработка осуществляется преимущественно с использованием внутренних информационных систем», ни слова про автоматизированные интеграции, ни слова про использование внешних сервисов. При том, что Make.com уже вовсю управлял расписанием публикаций, пусть и в щадящем формате. Пришлось садиться с юристом и обновлять документ, описывая, что часть обработки представляет собой автоматизированные действия по доставке контента, а первичная обработка и хранение происходят на территории РФ. Это не идеальная формулировка (я бы ещё долго её полировала), но она лучше, чем полное молчание о реальном положении дел.
Это означает, что внедряя автоматизацию публикаций Make.com, вы одновременно внедряете обязательство привести в порядок своё уведомление в Роскомнадзор. Игнорировать эту связку — значит рассчитывать на удачу, а удача, как известно, любит подготовленных.
Как вести журналы обработки, если часть логики живёт в Make.com
Журналы обработки данных — это та часть работы, которую хочется отложить до пенсии. Но закон смотрит на это гораздо прозаичнее: если вы работаете с персональными данными в автоматизированных системах, у вас должны быть понятные записи о том, какие операции когда проводились, кто имел доступ и каковы были результаты. Когда часть логики уезжает в Make.com, возникает соблазн считать, что «там и так всё логируется». Увы, логи Make.com живут за пределами российского правового поля, и опираться только на них — слабая позиция. На практике я рекомендую дублировать ключевые события в журнал, который хранится в российском контуре.
В проекте со Светой мы сделали так: при каждом запуске сценария Make.com записывал в российскую систему минимум информации — идентификатор задания, время, статус (успешно/ошибка), список каналов. Никаких персональных данных, только техническая «телеметрия». С другой стороны, российская база вела свой журнал событий по обращениям к персональным данным: кто менял статусы согласий, кто допускал использование историй в автоматизации, кто редактировал контент-план. Да, это не делается за один вечер (хотя в теории можно попытаться…), но зато потом любые вопросы аудиторов закрываются гораздо спокойнее: у вас есть история, и она живёт в России.
Получается, что настройка расписания публикаций через Make.com автоматически тащит за собой три слоя: согласия, уведомления и журналы. Если один из них выпал, система становится хрупкой. Можно какое-то время жить и так, но это как ставить красивую надстройку на фундамент, в котором забыли арматуру.
Где Make.com реально экономит время и где я сама обожглась
Какие части публикационного процесса логично отдавать Make.com
Если отбросить романтику «автопостинг спасёт мир», Make.com лучше всего справляется с рутинными, но строго формализуемыми задачами. В контексте расписания публикаций это: доставка заранее утверждённого контента в нужные каналы по времени, перекладка статусов между системами, синхронизация расписаний, уведомления команды о сбоях. Я заметила, что там, где у вас есть чёткий контент-план и понятные правила «что куда уходит», Make.com даёт отличный рычаг: сценарий работает как конвейер, а вы занимаетесь либо стратегией, либо творчеством. Но там, где часть логики плавает в голове редактора, а часть в неформальных переписках, автоматизация начинает спотыкаться.
В проекте со Светой мы как раз начинали чуть не с конца: она хотела, чтобы Make.com сам выбирал, какие посты публиковать, исходя из свежести темы и реакции аудитории (я в какой-то момент поймала себя на мысли, что это немного амбициозно для первого захода). Пришлось шагнуть назад и договориться: сначала мы автоматизируем только то, что уже стабильно работает вручную — регулярные рубрики, анонсы занятий, напоминания о дедлайнах. Вся креативная часть, завязанная на тонкости формулировок, осталась у неё. Зато через месяц она выдохнула: блок «рутины» шёл сам, а она могла спокойно думать о новых форматах, а не нажимать «опубликовать» во всех соцсетях по кругу.
Чтобы понять, что отдавать Make.com, я иногда предлагаю простую практику.
Если задачу можно описать так, что другой человек выполнит её один в один, не задав ни одного уточняющего вопроса, эту задачу можно отдавать автоматизации.
Где я недооценила человеческий фактор и пришлось переделывать все сценарии
Признаюсь, у меня самой была история, где я переоценила мощь автоматизации и недооценила людей. В одном из проектов мы с командой настроили шикарное расписание публикаций: Make.com тянул контент из базы, учитывал часовые пояса, разводил посты по разным каналам, обновлял статусы и даже писал в рабочий чат, если что-то пошло не так. На бумаге всё выглядело идеально. На деле через пару недель выяснилось, что редакторы продолжали править тексты в последний момент прямо в интерфейсе соцсети, а не в базе, потому что так «быстрее». Автоматизация в итоге тащила устаревшие версии, а люди — свежие, ручные правки. Получилась двойная реальность, и это была моя ошибка (нет, подожди, наша общая, но я её пропустила).
Свете я этот эпизод честно рассказала заранее, чтобы она не удивлялась моему настойчивому интересу к процессам команды. Мы вместе с её коллегами договорились: правки делаем только в одном месте — в российской таблице, а не в VK или Telegram напрямую. Если кто-то упал в искушение и поправил пост по пути, он обязан вернуться и обновить базу. Да, звучит дисциплинарно, но иначе вы либо убиваете автоматизацию, либо живёте с постоянным когнитивным диссонансом. В моменте это немного бесило (я видела по лицам), зато теперь, когда система стабильно работает, все уже забыли, как это было — бегать и вспоминать, куда какой текст ушёл.
Получается, что make.com автоматизация — это не только про сценарии, но и про договорённости внутри команды: кто за что отвечает, где «источник правды», что считается нарушением процесса. И если это не проговорить, никакая техническая красота не спасёт от хаоса.
Как кейс Светы превратился из потенциального штрафа в экономию времени
Помнишь, я в начале рассказывала про Свету из маркетинга и её желание убежать от ночных публикаций? На старте она пришла с готовым «почти рабочим» сценарием Make.com: форма на сайте — Make.com — Google Sheets — автопостинг. Красиво, быстро, удобно и почти гарантированный штраф в перспективе. Мы развернули всё это, как одеяло, на полу: вынесли формы и таблицы в российский контур, переписали согласия, ограничили состав данных, которые уходят в Make.com, перенастроили расписание так, чтобы Make управлял только временем и каналами, но не видел ничего лишнего. Плюс поставили журналированиe и договорились о правилах правок.
Через три месяца после запуска у неё была ситуация, которая меня самой порадовала. В один из дней VK слегка моргнул API и часть постов не вышла. Света зашла в логи, увидела ошибку, вручную догнала публикации и написала в общий чат: «Коллеги, всё под контролем, завтра Make сам доберёт». Раньше в такой день она бы, скорее всего, до ночи сидела, проверяя каждое сообщество вручную. А тут система отработала сбой как взрослый организм. И главное — всё это не висело в серой зоне по 152-ФЗ. Я в этот момент поняла, что кейс можно считать состоявшимся: автоматизация перестала быть игрушкой и стала инструментом, который экономит часы и не создаёт скрытых юридических дыр.
Это означает, что даже если стартовая точка выглядит как «мы всё уже сделали, только чуть-чуть не по закону», есть смысл вернуться к архитектуре, как мы сделали со Светой, и перестроить всё на белый контур. Да, это не самый быстрый путь, но зато ночи станут гораздо спокойнее — и у маркетолога, и у юриста.
Какие ошибки при настройке расписания публикаций через Make.com встречаются чаще всего
Какие заблуждения про «мы не обрабатываем персональные данные» я слышу регулярно
Самая частая фраза, которую я слышу при аудите автоматизации: «Мы же просто постим контент, какие персональные данные?» Дальше выясняется, что через эту же схему проходят письма подписчиков, логины авторов, иногда даже фрагменты переписок, которые случайно попали в текст. Или сквозные ID, которые напрямую связаны с CRM и позволяют по ним поднять профиль человека. Юридически это всё попадает под обработку персональных данных, а технически спокойно летит через Make.com за границу. На вопрос «вы уведомляли об этом Роскомнадзор?» обычно следует пауза и взгляд в сторону. Я к таким ситуациям уже привыкла, но всё равно каждый раз поражаюсь, насколько сильно расходятся восприятие и факты.
Со Светой мы в начале сделали одно упражнение: выписали на лист все данные, которые так или иначе участвуют в процессе публикаций. Потом рядом поставили плюсы и минусы: можно ли по этим данным установить конкретного человека. Этот простой шаг тут же вскрыл несколько полей, которые команда вообще не считала персональными, хотя закон видел их иначе. Например, связку «ник в Telegram + город + тематика курса». В их нише этот набор уже почти однозначно указывал на конкретного ученика. Пришлось переписать часть шаблонов и убрать эти связки из автоматизированных публикаций.
Я заметила, что как только команда один раз проделает такое честное упражнение, разговор «мы не обрабатываем персональные данные» заканчивается. Остаётся другой, более конструктивный: «как сделать так, чтобы мы их обрабатывали правильно».
Где чаще всего ломается связка «российский сервер — Make.com — соцсети»
Вторая типичная проблема — архитектурные дыры между российским контуром и Make.com. На бумаге всё красиво: данные собираются в России, потом Make.com получает только то, что ему действительно нужно, и дальше публикует это в VK, Telegram, Дзен. На практике где-то в середине всегда находится «временная» Google-таблица или ещё какой-нибудь иностранный сервис, который использовали «на пилоте», а потом так и не убрали. Эта временная заплатка в итоге становится самым уязвимым местом: данные сначала уходят туда, потом возвращаются, а про локализацию все вспоминают только при слове «штраф».
В проекте со Светой мы тоже нашли такую «временную» штуку: один из старых сценариев тянул список для рассылки не из российской базы, а из Google Sheets, где в своё время тестировали гипотезу. Сценарий вроде бы «не про персональные данные», но в таблице лежали e-mail и пометки по сегментам. Хорошая новость — объём был небольшой. Плохая — формально это уже нарушение. Мы отключили этот сценарий, перенесли данные, а старую таблицу удалили. Я до сих пор подозреваю, что без аудита он жил бы ещё годами.
Это означает, что если вы хотите честно выстроить цепочку «Россия — Make.com — соцсети», имеет смысл пройтись по всем существующим сценариям и соединениям, а не только по тем, что вы сами считаете значимыми. Иногда самые проблемные вещи прячутся в старых «тестовых» связках.
Как избежать спонтанного «творчества» в автоматизации и сохранить контроль
Третья ошибка уже не про законы, а про человеческую природу. Как только у команды появляется инструмент типа Make.com, хочется экспериментировать: добавить ещё один модуль, попробовать новый триггер, скрестить расписание с аналитикой. Через пару месяцев в сценарии превращаются в слоёный пирог, где уже никто толком не понимает, что от чего зависит. Я не против экспериментов (сама люблю), но без минимальной дисциплины это заканчивается тем, что никто не может гарантировать, что именно выйдет в эфир завтра в 9 утра. А когда у вас ещё и юридические ограничения, такой сюрприз совсем ни к чему.
Со Светой мы договорились о простом правиле: любые изменения в сценариях, которые влияют на состав данных или логики публикаций, сначала описываются в одном абзаце и обсуждаются. Не в духе «утвердите ТЗ на 5 страницах», а «я хочу добавить такой модуль, он будет делать вот это, здесь задействованы такие поля». Это занимало по 10-15 минут, но зато избавило от бесплотного творчества прямо в продакшене. Плюс мы завели маленький журнал изменений по сценариям, чтобы через полгода можно было вспомнить, кто, когда и зачем что-то менял. Да, это уже почти внутренний аудит, но с ним жить спокойнее.
Получается, что настройка расписания публикаций Make.com — это ещё и про культуру работы с изменениями. Если её нет, сценарии постепенно превращаются в «чёрную магию», а результаты — в лотерею.
Как собрать всё воедино и не утонуть в деталях
Какая минимальная архитектура нужна, чтобы Make.com работал честно и полезно
Если собрать все кусочки вместе, минимальный контур для безопасной автоматизации публикаций через Make.com в России выглядит не так уж страшно. Вам нужен российский сервер или облако, где живут формы, базы и контент-план, отдельное согласие на обработку и использование историй в маркетинге, уведомление в Роскомнадзор, обновлённое под реальную картину, аккуратная интеграция Make.com, которая не видит лишних персональных данных, и сценарии, отвечающие за расписания и статусы. Плюс журналы — технических операций и обращений к персональным данным. Звучит много, но если идти шаг за шагом, это не гигантский проект на годы, а вполне подъёмная работа на несколько недель.
История со Светой как раз про это. Мы не строили сразу «идеальную систему», мы шли слоями: сначала вынесли данные в российский контур, потом подчистили сценарии Make.com, потом обновили согласия и уведомление, затем доделали журналы. Параллельно шла жизнь — посты выходили, курсы запускались, отчёты по метрикам обновлялись. В какой-то момент Света даже сказала, что ей стало проще объяснять новичкам, как всё устроено: «у нас данные живут тут, автоматизация — тут, а Make просто нажимает кнопки по расписанию». Для меня это был маркер, что система перестала быть хрупкой, её можно масштабировать и переносить на другие проекты.
Я заметила, что как только у команды в голове складывается эта минимальная архитектура, разговор про make.com автоматизация перестаёт быть спором «можно/нельзя» и превращается в конструктив «как именно мы это делаем, чтобы потом не краснеть перед проверяющими».
Как измерить эффект от автоматизации расписаний, а не только радоваться красоте схем
Любая автоматизация без цифр превращается в хобби. Чтобы понять, была ли игра свеч, я обычно считаю три вещи: сколько времени раньше уходило на ручные публикации, сколько ошибок происходило (забытые посты, дубли, неверное время), и как часто приходилось тушить пожары из-за человеческого фактора. В кейсе Светы до автоматизации у неё уходило по 1-1,5 часа в день только на то, чтобы разложить посты по каналам и проверить, что всё ушло. Плюс примерно раз в неделю что-то ломалось: пост не выходил в нужное время, забывали про одно из сообществ, путали часовые пояса.
После того как мы выстроили расписание через Make.com с опорой на российский контур, её участие сократилось до 15-20 минут в день: посмотреть, как отработали сценарии, внести правки в контент-план, если нужно, и проверить пару ключевых публикаций. Количество ошибок упало почти до нуля — не потому что мы стали идеальными, а потому что сценарий не устаёт и не забывает. За три месяца мы насчитали не больше трёх сбоев, и все были связаны с внешними API, а не с архитектурой.
В сухом остатке Света сэкономила около 20-25 часов в месяц, которые раньше уходили на механическую работу, и полностью убрала из своей жизни ночные «аврал-публикации». А я получила ещё один аргумент в копилку: честная, законопослушная автоматизация вполне может быть и полезной, и быстрой, и контролируемой.
К чему вернулась Света после трёх месяцев работы с Make.com и что из этого можно взять себе
Возвращаясь к той самой сцене из начала, где Света сидела с остывшим кофе и шестью вкладками VK, Telegram и планеров, через три месяца картинка выглядела иначе. Кофе всё ещё иногда остывал (это уже профессия, а не технология), но не из-за того, что она жонглировала публикациями. Make.com тихо крутил расписания, российский контур надёжно держал данные, юрист перестал нервно интересоваться, что там за иностранный сервис стоит в архитектуре, а сама Света начала думать о запуске ИИ-помощника для генерации черновиков постов. И да, теперь она уже автоматически спрашивает: «где эти данные будут храниться и кто их увидит», прежде чем что-то внедрять.
Если вынести из её истории один практический урок, он будет такой: не надо выбирать между «удобно» и «по закону». Можно построить автоматизацию публикаций Make.com так, чтобы и расписание работало, и 152-ФЗ соблюдался, и команда не сходила с ума. Для этого придётся один раз честно посмотреть на свою архитектуру, вынести персональные данные в российский контур, настроить сценарии Make.com в роли оркестратора, а не хранилища, и не забыть про согласия, уведомления и журналы. Дальше система начинает работать на вас, а не наоборот.
Если тебе хочется не просто прочитать про это, а аккуратно разложить свои процессы и собрать такую же прозрачную архитектуру, можно подсмотреть дополнительные разборы и схемы в моём телеграм-канале про автоматизацию и AI в белой зоне. А если интереснее посмотреть, чем мы занимаемся в MAREN и какие ещё связки автоматизации и комплаенса я собираю, загляни на сайт promaren.ru — это такой аккуратный каталог моих «экспериментов, доведённых до рабочего состояния».
Что ещё стоит учесть перед запуском своих сценариев
Как использовать Make.com только для оркестрации, а не как хранилище данных
Я бы посоветовала всегда начинать с самого жёсткого ограничения: считать Make.com чистым оркестратором, который не хранит и не анализирует персональные данные, а только двигает по расписанию обезличенные элементы контента. Это дисциплинирует архитектуру и сильно упрощает разговор с безопасностью. В такой логике все хранилища, где лежат имена, контакты, истории пользователей, находятся в российском контуре, а Make.com видит только результат обработки — тексты без личных меток, ссылки на медиа, параметры времени. Это не значит, что вы полностью исключаете Make из цепочки обработки, но вы сознательно не делаете его местом, где оседают чувствительные данные.
В кейсе Светы именно такой подход позволил спокойно объяснить модель проверки: при аудите видно, что Make используется как промежуточный сервис, который по API забирает уже подготовленный набор и по API же отдает его в соцсети. Никаких форм с персональными данными, никаких журналов согласий, никаких дублей CRM. Да, внутри Make.com всё равно хранятся логи выполнения и куски запросов, но поскольку мы заранее исключили из них персональные поля, эти логи не превращаются в иностранное хранилище персональных данных. Это не отменяет необходимости думать головой, но существенно снижает градус напряжения вокруг сервиса.
Чем меньше Make.com знает о ваших пользователях, тем проще жить потом, и в этот раз тут нет никакого скрытого подвоха.
Как встроить в архитектуру ещё и ИИ-агентов, не нарушая логику защиты данных
Как только автоматизация расписания публикаций более-менее устаканивается, следующий естественный шаг — добавлять ИИ-агентов: помощников, которые подбирают темы, предлагают формулировки, адаптируют текст под разные каналы. Здесь действуют те же принципы, что и с Make.com: не тянуть в ИИ реальные персональные данные людей, не использовать в промптах полные истории пользователей, не прикреплять к запросам таблицы с e-mail и логинами. Я заметила, что многим поначалу не очевидно, что промпт к ИИ — это тоже передача данных третьей стороне, и если в нём есть что-то про конкретного человека, это уже зона закона.
Света как раз хотела запустить ИИ-агента, который бы подсказывал формулировки для анонсов занятий. Мы договорились, что агент будет работать только с обезличенными данными: темой, форматом, датой, описанием без упоминания конкретных учеников. Все истории, где фигурируют реальные люди, по-прежнему писались вручную. Да, это оставляет часть работы в «ручном» режиме, но зато не превращает ИИ в ещё один потенциальный источник утечки или нарушения 152-ФЗ. И, что приятно, такие агенты прекрасно справляются с рутиной, не требуя от вас раскрывать лишние данные.
Это означает, что комбинация «российский контур + Make.com + ИИ-агенты» вполне жизнеспособна, если вы в каждом звене задаёте один и тот же вопрос: какие данные здесь на самом деле нужны, и могут ли они идентифицировать человека. Всё лишнее лучше выкинуть сразу, чем потом разгребать последствия.
Что делать, если вы понимаете, что сейчас всё построено «неправильно»
Иногда после таких разборов ко мне приходят с честным признанием: «Мы всё уже настроили, всё крутится, но после этого текста я понимаю, что у нас половина логики живёт в Make.com и Google, и это всё не очень законно. Что делать — всё ломать?» Ломать не обязательно, но останавливаться и пересобирать — точно да. Я обычно предлагаю идти по шагам: инвентаризация сценариев и точек, где появляются персональные данные, перенос первичной обработки в российский контур, постепенное выключение наиболее рискованных связок, обновление согласий и уведомления, настройка журналов. Параллельно часть автопостинга может временно вернуться в ручной режим — неприятно, но терпимо.
Света тоже не начинала с идеальной точки: у неё уже полгода жили сценарии с первичной обработкой за границей. Мы не стали их в одну ночь сносить, а аккуратно перенесли данные, закрыли самые острые места, и только потом перезапускали автоматизацию по новой архитектуре. Да, какое-то время ей пришлось чуть больше контролировать публикации, зато после перезапуска стало заметно проще: и отчитываться перед руководством, и спать спокойно. Даже если вы сейчас видите в своей системе кучу «красных флажков», это не повод опускать руки. Это повод принять взрослое решение: либо вы идёте в белую зону, либо честно признаёте, что играете в лотерею с регулятором.
Я, как человек, который любит, чтобы процессы были прозрачными, а метрики честными, всё-таки болею за первый вариант. Потому что когда автоматизация работает в белую, самый частый побочный эффект — это возвращённое время. И оно того стоит.
Ответы на частые вопросы про автоматизацию расписания публикаций в России
Можно ли использовать Make.com, если я вообще не трогаю персональные данные?
Если вы уверены, что в автоматизации нет и не будет персональных данных или связок, по которым можно идентифицировать человека, использовать Make.com допустимо как чистый технический сервис. В реальной жизни такие случаи редки, поэтому стоит всё равно перепроверить состав данных и пути их движения. Как только появляются имена, e-mail или устойчивые идентификаторы пользователей, нужно возвращаться к требованиям 152-ФЗ и архитектуре с российским контуром.
Как быть, если у меня уже настроены формы, которые отправляют данные сразу в Make.com?
В такой ситуации лучше не откладывать и перенести первичную обработку на российский сервер или облако, а формы переподключить к нему. После этого Make.com можно использовать только для оркестрации, забирая уже подготовленные и по возможности обезличенные данные. Старые сценарии, которые нарушают требования по локализации, стоит аккуратно отключить и зафиксировать изменения в документах и журналах.
Можно ли тестировать автоматизацию на реальных данных «для пилота»?
Для российских компаний использование реальных персональных данных в пилотах подчиняется тем же требованиям, что и в боевых системах. Если вы хотите обкатать автоматизацию, лучше использовать синтетические данные или специально подготовленные тестовые аккаунты. Пилот с настоящими e-mail и именами без корректной архитектуры и уведомления Роскомнадзора будет считаться нарушением.
Нужно ли обязательно уведомлять Роскомнадзор, если я всего лишь веду небольшой блог с автопостингом?
Размер проекта здесь не играет ключевой роли: если вы системно обрабатываете персональные данные граждан РФ, уведомление регулятора требуется. Автоматизация публикаций через Make.com сама по себе не является основанием для уведомления, но если она завязана на реальных пользователях, лучше оформить всё корректно. Это снизит риски при возможной проверке, даже если вы формально «маленький игрок».
Есть ли смысл полностью уходить с Make.com на российские аналоги ради спокойствия?
Такой путь тоже возможен и для некоторых компаний действительно комфортнее опираться только на отечественную инфраструктуру. Однако при аккуратной архитектуре и разделении контуров Make.com можно использовать как безопасный инструмент оркестрации. Решение зависит от вашей готовности управлять рисками и от того, насколько глубоко сервис встроен в процессы.
Что делать, если юрист категорически против Make.com, а команда на нём уже завязана?
В этом случае полезно сесть вместе и разложить архитектуру по шагам, показывая, какие данные где обрабатываются и как можно их обезопасить. Часто возражения связаны с тем, что юрист видит только худший сценарий, а команда — только удобство. Совместный дизайн с переносом первичной обработки в РФ и ограничением состава данных в Make.com помогает найти компромисс, при котором и закон выполняется, и процессы не останавливаются.